Journal
Ce journal contient 8 entrées.
 RSS Feed
RSS Feed Tag cloud
Tag cloud
The Infinite Drum Machine
 Une expérience de classification automatique sur des fichiers audio représentant des sons du quotidien. L'algorithme ne reçoit aucune information à priori (non supervisé) hormis les fichiers audio. La technique utilisée dans cette expérience est t-SNE (t-Distributed Stochastic Neighbor Embedding), permettant de réduire un espace à n dimensions vers un espace plus petit (ici 3 dimensions: X, Y, et couleur).
Une expérience de classification automatique sur des fichiers audio représentant des sons du quotidien. L'algorithme ne reçoit aucune information à priori (non supervisé) hormis les fichiers audio. La technique utilisée dans cette expérience est t-SNE (t-Distributed Stochastic Neighbor Embedding), permettant de réduire un espace à n dimensions vers un espace plus petit (ici 3 dimensions: X, Y, et couleur).
Description de t-SNE: http://jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
 mer. 25 janv. 2017 09:47:44 CET -
mer. 25 janv. 2017 09:47:44 CET -
 -
link
- https://aiexperiments.withgoogle.com/drum-machine
-
link
- https://aiexperiments.withgoogle.com/drum-machine
 machine-learning datamining clustering
machine-learning datamining clustering
Description de t-SNE: http://jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
mer. 25 janv. 2017 09:47:44 CET -
-
link
- https://aiexperiments.withgoogle.com/drum-machine
machine-learning datamining clustering
Comment déterminer à quelle heure a été prise une photo ?
 Une méthode pour déterminer approximativement à quelle heure a été prise une photo, en se basant sur les ombres portées.
Une méthode pour déterminer approximativement à quelle heure a été prise une photo, en se basant sur les ombres portées.
sam. 07 nov. 2015 17:40:05 CET -
-
link
- http://joelmatriche.com/2015/10/28/determiner-plus-ou-moins-lheure-a-laquelle-une-photo-a-ete-prise/
datation
sam. 07 nov. 2015 17:40:05 CET -
-
link
- http://joelmatriche.com/2015/10/28/determiner-plus-ou-moins-lheure-a-laquelle-une-photo-a-ete-prise/
datation
A curated list of awesome Machine Learning frameworks, libraries and software
Une liste de librairies d'apprentissage artificiel, de traitement du langage naturel et de data mining. Pour divers langages : C/C++, Java, Python, etc.
mer. 16 juil. 2014 14:58:27 CEST -
-
link
- https://github.com/josephmisiti/awesome-machine-learning
machine-learning programmation datamining
mer. 16 juil. 2014 14:58:27 CEST -
-
link
- https://github.com/josephmisiti/awesome-machine-learning
machine-learning programmation datamining
CRAWDAD - A Community Resource for Archiving Wireless Data At Dartmouth
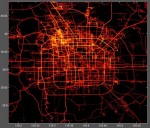 Tester des applications qui tirent parti de la mobilité peut s'avérer très difficile en pratique, même à une échelle raisonnable (besoin de trouver des testeurs, sur une longue période).
Tester des applications qui tirent parti de la mobilité peut s'avérer très difficile en pratique, même à une échelle raisonnable (besoin de trouver des testeurs, sur une longue période).
Pour simplifier cette tâche, il est d'usage de faire appel à des données pré-existantes (datasets) pour simuler la mobilité. Malheureusement, il existe peu de datasets publics, comme ceux publiés par Microsoft sur la mobilité des habitants et des taxis dans Beijing :
http://research.microsoft.com/en-us/downloads/b16d359d-d164-469e-9fd4-daa38f2b2e13/
http://research.microsoft.com/apps/pubs/?id=152883
CRAWDAD ouvre des datasets acquis lors de recherches spécifiques. On y retrouve un peu de tout, comme des logs de connexion, des traces de mobilité (humains, véhicules, etc.) ou des dump réseaux.
Je suppose, par ailleurs, que n'importe qui peut contribuer en proposant des datasets.
Overall CRAWDAD statistics:
89 datasets
19 tools
5846 users
98 countries
Le seul point négatif, c'est que l'inscription est obligatoire pour pouvoir télécharger les datasets. Cependant, j'ai été validé quelques heures seulement après mon inscription.
lun. 31 mars 2014 11:43:29 CEST -
-
link
- http://www.crawdad.org/all-byname.html
dataset
Pour simplifier cette tâche, il est d'usage de faire appel à des données pré-existantes (datasets) pour simuler la mobilité. Malheureusement, il existe peu de datasets publics, comme ceux publiés par Microsoft sur la mobilité des habitants et des taxis dans Beijing :
http://research.microsoft.com/en-us/downloads/b16d359d-d164-469e-9fd4-daa38f2b2e13/
http://research.microsoft.com/apps/pubs/?id=152883
CRAWDAD ouvre des datasets acquis lors de recherches spécifiques. On y retrouve un peu de tout, comme des logs de connexion, des traces de mobilité (humains, véhicules, etc.) ou des dump réseaux.
Je suppose, par ailleurs, que n'importe qui peut contribuer en proposant des datasets.
Overall CRAWDAD statistics:
89 datasets
19 tools
5846 users
98 countries
Le seul point négatif, c'est que l'inscription est obligatoire pour pouvoir télécharger les datasets. Cependant, j'ai été validé quelques heures seulement après mon inscription.
lun. 31 mars 2014 11:43:29 CEST -
-
link
- http://www.crawdad.org/all-byname.html
dataset
Accueil - data.gouv.fr
 data.gouv.fr c'est la plateforme mise en place par le gouvernement français dans le contexte de l'Open Data (l'ouverture au public des données collectées par l'état, les collectivités, les services publics, etc.).
data.gouv.fr c'est la plateforme mise en place par le gouvernement français dans le contexte de l'Open Data (l'ouverture au public des données collectées par l'état, les collectivités, les services publics, etc.).
N'importe quelle organisation peut s'enregistrer sur la plateforme et y déposer des jeux de données bruts dans des formats ouverts (CSV, TSV, PDF, etc.). L'initiative est bonne et la récupération des données est très simple ; le système est basé sur le logiciel open-source CKAN (http://ckan.org/about) de l'Open Knowledge Foundation.
Pour le moment on y trouve un peu de tout, comme la liste des musées de France, la géolocalisation des ambassades, des données concernant les revenus, etc.
Initiatives similaires en Grande Bretagne et au niveau Européen :
http://data.gov.uk
http://publicdata.eu
mer. 12 févr. 2014 19:58:13 CET -
-
link
- http://www.data.gouv.fr/
open-data dataset
N'importe quelle organisation peut s'enregistrer sur la plateforme et y déposer des jeux de données bruts dans des formats ouverts (CSV, TSV, PDF, etc.). L'initiative est bonne et la récupération des données est très simple ; le système est basé sur le logiciel open-source CKAN (http://ckan.org/about) de l'Open Knowledge Foundation.
Pour le moment on y trouve un peu de tout, comme la liste des musées de France, la géolocalisation des ambassades, des données concernant les revenus, etc.
Initiatives similaires en Grande Bretagne et au niveau Européen :
http://data.gov.uk
http://publicdata.eu
mer. 12 févr. 2014 19:58:13 CET -
-
link
- http://www.data.gouv.fr/
open-data dataset
Architecture de couche d'accès aux données (DAL) de hautes performances — Partie 1
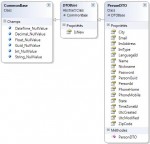 Ecrire des couches d'accès aux données proprement en, si l'on ne désire pas passer par un ORM.
Ecrire des couches d'accès aux données proprement en, si l'on ne désire pas passer par un ORM.
Le tutoriel est pour du .NET C#, mais les concepts impliqués (Data Access Layer, Data Transfer Object, Business Logic Layer et le reste de l'architecture) ne dépendent pas du langage et peuvent s'appliquer n'importe où.
ven. 07 févr. 2014 17:35:21 CET -
-
link
- http://rv26t.developpez.com/tutoriels/dotnet/c-sharp/data-transfert-object-partie1/
data architecture
Le tutoriel est pour du .NET C#, mais les concepts impliqués (Data Access Layer, Data Transfer Object, Business Logic Layer et le reste de l'architecture) ne dépendent pas du langage et peuvent s'appliquer n'importe où.
ven. 07 févr. 2014 17:35:21 CET -
-
link
- http://rv26t.developpez.com/tutoriels/dotnet/c-sharp/data-transfert-object-partie1/
data architecture
Mining of Massive Datasets
Un super bouquin sur le data mining, dont la couverture est certes moche, mais dont vous pouvez lire le contenu en ligne.
J'apprécie tout particulièrement son chapitre sur le stream processing, qui me concerne spécifiquement.
J'ai fait un backup du PDF du livre ici : http://benjaminbillet.fr/media/mining-of-massive-datasets.pdf
mer. 11 déc. 2013 19:36:15 CET -
-
link
- http://infolab.stanford.edu/~ullman/mmds.html
stream-processing datamining algorithmique
J'apprécie tout particulièrement son chapitre sur le stream processing, qui me concerne spécifiquement.
J'ai fait un backup du PDF du livre ici : http://benjaminbillet.fr/media/mining-of-massive-datasets.pdf
mer. 11 déc. 2013 19:36:15 CET -
-
link
- http://infolab.stanford.edu/~ullman/mmds.html
stream-processing datamining algorithmique
A Programmer's Guide to Data Mining
 Un guide d'introduction au data mining, par la pratique. Au programme :
Un guide d'introduction au data mining, par la pratique. Au programme :
- Chapter 1: Introduction
- Chapter 2: Get Started with Recommendation Systems
- Chapter 3: Implicit ratings and item-based filtering
- Chapter 4: Classification
- Chapter 5: Further Explorations in Classification
- Chapter 6: Naïve Bayes
- Chapter 7: Naïve Bayes and unstructured text
- Chapter 8: Clustering
Le guide est toujours en cours de rédaction, à suivre donc.
lun. 11 nov. 2013 14:06:42 CET -
-
link
- http://guidetodatamining.com/
datamining
- Chapter 1: Introduction
- Chapter 2: Get Started with Recommendation Systems
- Chapter 3: Implicit ratings and item-based filtering
- Chapter 4: Classification
- Chapter 5: Further Explorations in Classification
- Chapter 6: Naïve Bayes
- Chapter 7: Naïve Bayes and unstructured text
- Chapter 8: Clustering
Le guide est toujours en cours de rédaction, à suivre donc.
lun. 11 nov. 2013 14:06:42 CET -
-
link
- http://guidetodatamining.com/
datamining
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.