Journal
Ce journal contient 354 entrées.
 RSS Feed
RSS Feed Tag cloud
Tag cloud
Teach Yourself Japanese
Teach Yourself Japanese
 dim. 05 mai 2019 10:58:41 CEST -
dim. 05 mai 2019 10:58:41 CEST -
 -
link
- http://www.sf.airnet.ne.jp/~ts/japanese/index.html
-
link
- http://www.sf.airnet.ne.jp/~ts/japanese/index.html
 langue japonais
langue japonais
dim. 05 mai 2019 10:58:41 CEST -
-
link
- http://www.sf.airnet.ne.jp/~ts/japanese/index.html
langue japonais
Getting started with the i3 tiling window manager
 Démarrer avec i3
Démarrer avec i3
dim. 05 mai 2019 10:54:40 CEST -
-
link
- https://fedoramagazine.org/getting-started-i3-window-manager
linux
dim. 05 mai 2019 10:54:40 CEST -
-
link
- https://fedoramagazine.org/getting-started-i3-window-manager
linux
/proc
 /proc in a nutshell :)
/proc in a nutshell :)
dim. 05 mai 2019 10:52:30 CEST -
-
link
- https://files.mastodon.social/media_attachments/files/003/362/858/original/dfaad2a178597a23.jpeg
linux
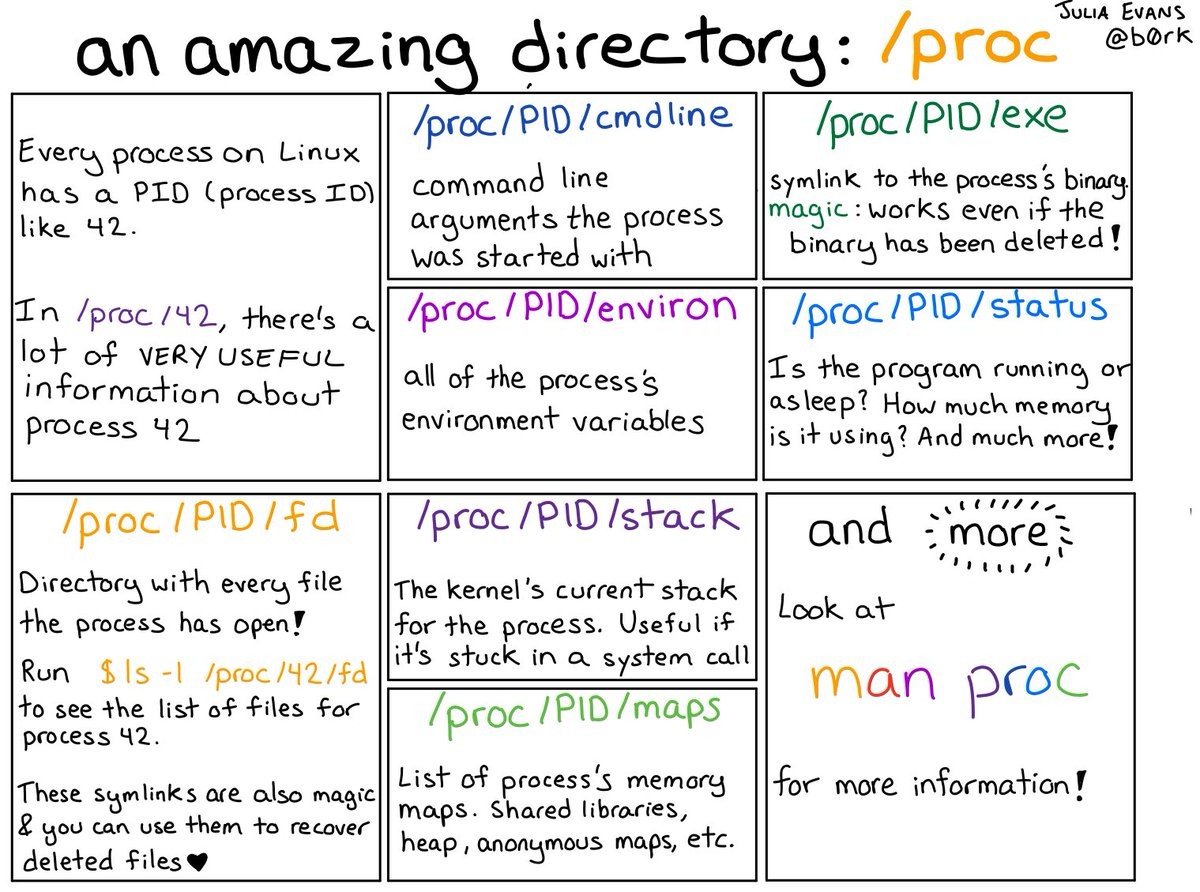{kind=link} dim. 05 mai 2019 10:52:30 CEST -
-
link
- https://files.mastodon.social/media_attachments/files/003/362/858/original/dfaad2a178597a23.jpeg
linux
dim. 05 mai 2019 10:52:30 CEST -
-
link
- https://files.mastodon.social/media_attachments/files/003/362/858/original/dfaad2a178597a23.jpeg
linux
AcoustID
 AcoustID is a project providing complete audio identification service, based entirely on open source software.
AcoustID is a project providing complete audio identification service, based entirely on open source software.
dim. 05 mai 2019 10:50:22 CEST -
-
link
- https://acoustid.org
musique multimédia
dim. 05 mai 2019 10:50:22 CEST -
-
link
- https://acoustid.org
musique multimédia
The Unreasonable Effectiveness of Recurrent Neural Networks
 Expérimentations avec des réseaux de neurones récurrents.
Expérimentations avec des réseaux de neurones récurrents.
Voir aussi (excellent blog): http://colah.github.io/posts/2015-08-Understanding-LSTMs
dim. 05 mai 2019 10:46:57 CEST -
-
link
- http://karpathy.github.io/2015/05/21/rnn-effectiveness
machine-learning
Voir aussi (excellent blog): http://colah.github.io/posts/2015-08-Understanding-LSTMs
dim. 05 mai 2019 10:46:57 CEST -
-
link
- http://karpathy.github.io/2015/05/21/rnn-effectiveness
machine-learning
OverTheWire: Wargames
 "The wargames offered by the OverTheWire community can help you to learn and practice security concepts in the form of fun-filled games."
"The wargames offered by the OverTheWire community can help you to learn and practice security concepts in the form of fun-filled games."
Pour les débutants, commencez par Bandit, pour intégrer les bases: http://overthewire.org/wargames/bandit
dim. 05 mai 2019 10:45:01 CEST -
-
link
- http://overthewire.org/wargames
sécurité jeu
Pour les débutants, commencez par Bandit, pour intégrer les bases: http://overthewire.org/wargames/bandit
dim. 05 mai 2019 10:45:01 CEST -
-
link
- http://overthewire.org/wargames
sécurité jeu
Seeing Theory
 A visual introduction to probability and statistics.
A visual introduction to probability and statistics.
dim. 05 mai 2019 10:42:03 CEST -
-
link
- https://seeing-theory.brown.edu
mathématiques statistiques
dim. 05 mai 2019 10:42:03 CEST -
-
link
- https://seeing-theory.brown.edu
mathématiques statistiques
Transcode
 transcode est un programme de traitement vidéo permettant notamment de stabiliser des vidéos.
transcode est un programme de traitement vidéo permettant notamment de stabiliser des vidéos.
dim. 05 mai 2019 10:38:55 CEST -
-
link
- http://www.quennec.fr/trucs-astuces/syst%C3%A8mes/gnulinux/commandes/multim%C3%A9dia/vid%C3%A9o/transcode
vidéo
dim. 05 mai 2019 10:38:55 CEST -
-
link
- http://www.quennec.fr/trucs-astuces/syst%C3%A8mes/gnulinux/commandes/multim%C3%A9dia/vid%C3%A9o/transcode
vidéo
Computing linear regression in one pass
 Dans le même ordre d'idée que le lien précédent, sauf qu'il s'agit cette fois d'effectuer une régression linéaire en continu. Comme beaucoup d'algorithmes continu, il présente l'avantage de travailler en mémoire constante.
Dans le même ordre d'idée que le lien précédent, sauf qu'il s'agit cette fois d'effectuer une régression linéaire en continu. Comme beaucoup d'algorithmes continu, il présente l'avantage de travailler en mémoire constante.
Le thumbnail vient de XKCD : https://xkcd.com/1725
lun. 10 avril 2017 10:32:57 CEST -
-
link
- https://www.johndcook.com/blog/running_regression/
mathématiques statistiques stream-processing
Le thumbnail vient de XKCD : https://xkcd.com/1725
lun. 10 avril 2017 10:32:57 CEST -
-
link
- https://www.johndcook.com/blog/running_regression/
mathématiques statistiques stream-processing
Computing skewness and kurtosis in one pass
 Comme vous l'avez peut être déjà remarqué, une bonne partie de mes travaux de thèse ont porté sur le traitement continu de flux de données : http://benjaminbillet.fr/media/benjaminbillet_memoire.pdf
Comme vous l'avez peut être déjà remarqué, une bonne partie de mes travaux de thèse ont porté sur le traitement continu de flux de données : http://benjaminbillet.fr/media/benjaminbillet_memoire.pdf
De fait, je m'intéresse beaucoup aux techniques mathématiques permettant de réaliser des calculs en continu (c'est-à-dire sans mémoriser l'intégralité des résultats passés).
Cet article de blog décrit comment calculer en continu l'espérance, la variance, l'écart-type, le coefficient de dissymétrie et le coefficient d'aplatissement sur un flux d'échantillons. De manière plus générale il s'agit d'une méthode pour calculer les moments (https://fr.wikipedia.org/wiki/Moment_%28mathématiques%29). On pourrait imaginer donc l'utiliser pour calculer d'autres mesures statistiques d'ordre supérieur. J'essayerais d'ailleurs, si je parviens à bien tout comprendre, d'en faire une implémentation généralisée :)
Quelques références:
- B. P. Welford (1962)."Note on a method for calculating corrected sums of squares and products".
- Donald E. Knuth (1998). The Art of Computer Programming, volume 2: Seminumerical Algorithms, 3rd edn.
lun. 10 avril 2017 10:22:27 CEST -
-
link
- https://www.johndcook.com/blog/skewness_kurtosis/
mathématiques statistiques stream-processing
De fait, je m'intéresse beaucoup aux techniques mathématiques permettant de réaliser des calculs en continu (c'est-à-dire sans mémoriser l'intégralité des résultats passés).
Cet article de blog décrit comment calculer en continu l'espérance, la variance, l'écart-type, le coefficient de dissymétrie et le coefficient d'aplatissement sur un flux d'échantillons. De manière plus générale il s'agit d'une méthode pour calculer les moments (https://fr.wikipedia.org/wiki/Moment_%28mathématiques%29). On pourrait imaginer donc l'utiliser pour calculer d'autres mesures statistiques d'ordre supérieur. J'essayerais d'ailleurs, si je parviens à bien tout comprendre, d'en faire une implémentation généralisée :)
Quelques références:
- B. P. Welford (1962)."Note on a method for calculating corrected sums of squares and products".
- Donald E. Knuth (1998). The Art of Computer Programming, volume 2: Seminumerical Algorithms, 3rd edn.
lun. 10 avril 2017 10:22:27 CEST -
-
link
- https://www.johndcook.com/blog/skewness_kurtosis/
mathématiques statistiques stream-processing
libcoap: C-Implementation of CoAP
 Implémentation en C du protocole CoAP (un protocole REST pour les machines fortement limitées en ressources, pour lequel il existe un mapping avec HTTP), décrit dans la RFC 7252.
Implémentation en C du protocole CoAP (un protocole REST pour les machines fortement limitées en ressources, pour lequel il existe un mapping avec HTTP), décrit dans la RFC 7252.
En plus du protocole de base, cette librairie implémente les ressources observables (RFC 7641) et la découverte des ressources liées (RFC 6690). Elle implémente aussi certains brouillons, comme l'annuaire de ressources CoAP (https://tools.ietf.org/html/draft-ietf-core-resource-directory-10).
RFC 7252 : https://tools.ietf.org/html/rfc7252
RFC 7641 : https://tools.ietf.org/html/rfc7641
RFC 6690 : https://tools.ietf.org/html/rfc6690
dim. 09 avril 2017 20:23:42 CEST -
-
link
- https://libcoap.net/
coap outil réseau rfc iot
En plus du protocole de base, cette librairie implémente les ressources observables (RFC 7641) et la découverte des ressources liées (RFC 6690). Elle implémente aussi certains brouillons, comme l'annuaire de ressources CoAP (https://tools.ietf.org/html/draft-ietf-core-resource-directory-10).
RFC 7252 : https://tools.ietf.org/html/rfc7252
RFC 7641 : https://tools.ietf.org/html/rfc7641
RFC 6690 : https://tools.ietf.org/html/rfc6690
dim. 09 avril 2017 20:23:42 CEST -
-
link
- https://libcoap.net/
coap outil réseau rfc iot
EXIF Tags
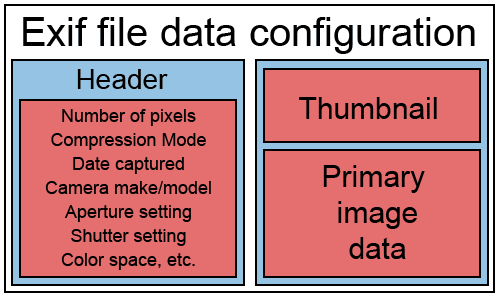 Liste des champs de l'Exchangeable Image File Format (EXIF) décrit de manière synthétique.
Liste des champs de l'Exchangeable Image File Format (EXIF) décrit de manière synthétique.
dim. 09 avril 2017 20:09:37 CEST -
-
link
- http://www.sno.phy.queensu.ca/~phil/exiftool/TagNames/EXIF.html
exif jpeg image 2d
dim. 09 avril 2017 20:09:37 CEST -
-
link
- http://www.sno.phy.queensu.ca/~phil/exiftool/TagNames/EXIF.html
exif jpeg image 2d
Les algorithmes : nouvelles formes de bureaucraties ? | InternetActu
 L'essayiste Adam Clair dresse une intéressante comparaison entre algorithme et bureaucratie. Les algorithmes sont paradoxaux rappelle-t-il : « ils sont conçus pour améliorer la prise de décision humaine en supprimant supposément ses biais et ses limites, mais les protocoles analytiques inévitablement réducteurs qu’ils mettent en œuvre se révèlent surtout vulnérables à des formes d’utilisation abusive. » Comme le dit très bien Cathy O’Neil dans son livre : loin d’être neutres et objectifs, « les algorithmes sont des opinions formalisées dans du code ».
L'essayiste Adam Clair dresse une intéressante comparaison entre algorithme et bureaucratie. Les algorithmes sont paradoxaux rappelle-t-il : « ils sont conçus pour améliorer la prise de décision humaine en supprimant supposément ses biais et ses limites, mais les protocoles analytiques inévitablement réducteurs qu’ils mettent en œuvre se révèlent surtout vulnérables à des formes d’utilisation abusive. » Comme le dit très bien Cathy O’Neil dans son livre : loin d’être neutres et objectifs, « les algorithmes sont des opinions formalisées dans du code ».
On parle bien sur ici des algorithmes dans le sens restreint de prise de décision pour le compte d'une organisation (les États, en l'occurrence). Par définition, donc, les algorithmes ne sont pas une *nouvelle* forme de bureaucratie ; ils en sont une parfaite implémentation. Il est effectivement peu pertinent de s'en prendre aux algorithmes pour critiquer les travers des bureaucratie, tout comme il est peut pertinent de s'en prendre au machine pour critiquer la disparition de l'emploi.
sam. 08 avril 2017 18:04:57 CEST -
-
link
- http://internetactu.blog.lemonde.fr/2017/04/08/les-algorithmes-nouvelles-formes-de-bureaucraties/
société algorithmique
On parle bien sur ici des algorithmes dans le sens restreint de prise de décision pour le compte d'une organisation (les États, en l'occurrence). Par définition, donc, les algorithmes ne sont pas une *nouvelle* forme de bureaucratie ; ils en sont une parfaite implémentation. Il est effectivement peu pertinent de s'en prendre aux algorithmes pour critiquer les travers des bureaucratie, tout comme il est peut pertinent de s'en prendre au machine pour critiquer la disparition de l'emploi.
sam. 08 avril 2017 18:04:57 CEST -
-
link
- http://internetactu.blog.lemonde.fr/2017/04/08/les-algorithmes-nouvelles-formes-de-bureaucraties/
société algorithmique
Géolocalisation des trains
 Tous les trains de la SNCF positionnés en temps réel (délai d'environ 5mn) sur une carte interactive.
Tous les trains de la SNCF positionnés en temps réel (délai d'environ 5mn) sur une carte interactive.
dim. 19 mars 2017 13:36:03 CET -
-
link
- http://www.sncf.com/fr/geolocalisation
outil
dim. 19 mars 2017 13:36:03 CET -
-
link
- http://www.sncf.com/fr/geolocalisation
outil
Tools | Ludum Dare
 Liste d'outils utilisés par les participants au Ludum Dare (compétition de développement de jeux vidéo en 48h avec un thème imposé). Il y a de tout, des outils simplifiés (Construct, Game Maker, GDevelop), des moteurs (Unity, Murl), des outils de dessin et de modélisation, etc.
Liste d'outils utilisés par les participants au Ludum Dare (compétition de développement de jeux vidéo en 48h avec un thème imposé). Il y a de tout, des outils simplifiés (Construct, Game Maker, GDevelop), des moteurs (Unity, Murl), des outils de dessin et de modélisation, etc.
dim. 19 mars 2017 13:33:08 CET -
-
link
- http://ludumdare.com/compo/tools/
jeu-vidéo 2d 3d
dim. 19 mars 2017 13:33:08 CET -
-
link
- http://ludumdare.com/compo/tools/
jeu-vidéo 2d 3d
Réparer npm lorsqu'il s'autodétruit
 Si, pour une raison inconnue, npm s'autodétruit après une mise à jour globale (npm update -g), il peut s'agir d'un problème lié à une ancienne version.
Si, pour une raison inconnue, npm s'autodétruit après une mise à jour globale (npm update -g), il peut s'agir d'un problème lié à une ancienne version.
Réinstallez node (par exemple: brew uninstall --force node && brew install node) puis réinstallez npm en utilisant la version de npm fournie avec node (npm install -g npm).
C'est un problème idiot, mais malheureusement fréquent: https://github.com/npm/npm/issues/4099
jeu. 16 mars 2017 15:20:56 CET -
-
link
javascript npm
Réinstallez node (par exemple: brew uninstall --force node && brew install node) puis réinstallez npm en utilisant la version de npm fournie avec node (npm install -g npm).
C'est un problème idiot, mais malheureusement fréquent: https://github.com/npm/npm/issues/4099
jeu. 16 mars 2017 15:20:56 CET -
-
link
javascript npm
Table des matières: Tout ce que les développeurs devraient savoir sur les performances en SQL
 Tout est dans le titre. Il y a beaucoup de choses intéressantes, notamment sur les performances de la pagination et des tris.
Tout est dans le titre. Il y a beaucoup de choses intéressantes, notamment sur les performances de la pagination et des tris.
mer. 25 janv. 2017 11:35:31 CET -
-
link
- http://use-the-index-luke.com/fr/table-des-matieres
bdd sql
mer. 25 janv. 2017 11:35:31 CET -
-
link
- http://use-the-index-luke.com/fr/table-des-matieres
bdd sql
Amit’s A* Pages
 Beaucoup d'informations et d'expérimentations autour de A* (algorithme de pathfinding dont j'avais déjà parlé là en citant le même blog : http://www.benjaminbillet.fr/news/index.php?link=d5gw4e).
Beaucoup d'informations et d'expérimentations autour de A* (algorithme de pathfinding dont j'avais déjà parlé là en citant le même blog : http://www.benjaminbillet.fr/news/index.php?link=d5gw4e).
Il y a plusieurs sujets abordés en bas de page, dont la construction de maps dans les jeux vidéos.
Voir aussi: http://www.redblobgames.com
mer. 25 janv. 2017 11:32:34 CET -
-
link
- http://theory.stanford.edu/~amitp/GameProgramming/
pathfinding algorithmique
Il y a plusieurs sujets abordés en bas de page, dont la construction de maps dans les jeux vidéos.
Voir aussi: http://www.redblobgames.com
mer. 25 janv. 2017 11:32:34 CET -
-
link
- http://theory.stanford.edu/~amitp/GameProgramming/
pathfinding algorithmique
Strong consistency models
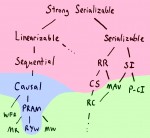 Article intéressant sur les modèles de consistances.
Article intéressant sur les modèles de consistances.
Ce blog est une mine d'informations.
mer. 25 janv. 2017 10:56:17 CET -
-
link
- https://aphyr.com/posts/313-strong-consistency-models
consistance bdd
Ce blog est une mine d'informations.
mer. 25 janv. 2017 10:56:17 CET -
-
link
- https://aphyr.com/posts/313-strong-consistency-models
consistance bdd
World's Smallest h.264 Encoder | Cardinal Peak
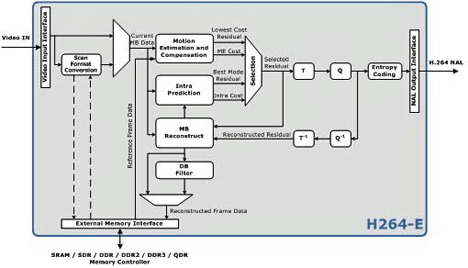 Le plus petit encodeur compatible avec la norme d'encodage vidéo H.264.
Le plus petit encodeur compatible avec la norme d'encodage vidéo H.264.
mer. 25 janv. 2017 10:45:00 CET -
-
link
- https://cardinalpeak.com/blog/worlds-smallest-h-264-encoder/
vidéo h264
mer. 25 janv. 2017 10:45:00 CET -
-
link
- https://cardinalpeak.com/blog/worlds-smallest-h-264-encoder/
vidéo h264
UserAgentString.com - List of User Agent Strings
 Liste d'User-Agent par navigateur. Je n'aurais pas imaginé qu'il puisse en exister autant.
Liste d'User-Agent par navigateur. Je n'aurais pas imaginé qu'il puisse en exister autant.
Voir aussi le délirant historique des User-Agent: http://webaim.org/blog/user-agent-string-history
mer. 25 janv. 2017 10:42:31 CET -
-
link
- http://useragentstring.com/pages/useragentstring.php
navigateur
Voir aussi le délirant historique des User-Agent: http://webaim.org/blog/user-agent-string-history
mer. 25 janv. 2017 10:42:31 CET -
-
link
- http://useragentstring.com/pages/useragentstring.php
navigateur
EE Times - 10 FPGA Design Techniques You Should Know
 "There are a number of universal design techniques with which FPGA engineers should be familiar -- here are some of the most important."
"There are a number of universal design techniques with which FPGA engineers should be familiar -- here are some of the most important."
A lire, ne serait-ce que par curiosité ;)
mer. 25 janv. 2017 10:41:36 CET -
-
link
- http://www.eetimes.com/document.asp?doc_id=1330128&print=yes
fpga électronique
A lire, ne serait-ce que par curiosité ;)
mer. 25 janv. 2017 10:41:36 CET -
-
link
- http://www.eetimes.com/document.asp?doc_id=1330128&print=yes
fpga électronique
Blue-Green Deployment
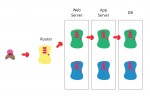 Le déploiement bleu-vert est une technique classique pour déployer une nouvelle version d'un serveur en évitant une interruption de service.
Le déploiement bleu-vert est une technique classique pour déployer une nouvelle version d'un serveur en évitant une interruption de service.
A noter: les tenants de cette technique passent souvent sous silence les problèmes de synchronisation entre les bases de données bleue et verte. La solution la plus radicale consiste à interdire les écritures, pour ne pas avoir à gérer la synchronisation. Ce n'est pas forcément idéal en pratique.
Si l'on souhaite conserver les écritures, alors deux cas se posent:
- le schéma de la base verte est le même que celui de la base bleu : il suffit que le système vert réplique les écritures dans les deux bases.
- le schéma de la base verte est différent de celui de la base bleu : il faut s'assurer que le système vert soit rétro-compatible avec la base bleue, pour pouvoir répliquer les écritures.
Voir aussi: https://www.rainforestqa.com/blog/2014-06-27-zero-downtime-database-migrations/
mer. 25 janv. 2017 10:39:30 CET -
-
link
- https://martinfowler.com/bliki/BlueGreenDeployment.html
architecture bdd
A noter: les tenants de cette technique passent souvent sous silence les problèmes de synchronisation entre les bases de données bleue et verte. La solution la plus radicale consiste à interdire les écritures, pour ne pas avoir à gérer la synchronisation. Ce n'est pas forcément idéal en pratique.
Si l'on souhaite conserver les écritures, alors deux cas se posent:
- le schéma de la base verte est le même que celui de la base bleu : il suffit que le système vert réplique les écritures dans les deux bases.
- le schéma de la base verte est différent de celui de la base bleu : il faut s'assurer que le système vert soit rétro-compatible avec la base bleue, pour pouvoir répliquer les écritures.
Voir aussi: https://www.rainforestqa.com/blog/2014-06-27-zero-downtime-database-migrations/
mer. 25 janv. 2017 10:39:30 CET -
-
link
- https://martinfowler.com/bliki/BlueGreenDeployment.html
architecture bdd
Colorful Image Colorization
 Cette technique de recolorisation d'image donne des résultats impressionnants
Cette technique de recolorisation d'image donne des résultats impressionnants
mer. 25 janv. 2017 10:21:08 CET -
-
link
- http://richzhang.github.io/colorization/
machine-learning image-processing 2d image
mer. 25 janv. 2017 10:21:08 CET -
-
link
- http://richzhang.github.io/colorization/
machine-learning image-processing 2d image
Loading models - Vulkan Tutorial
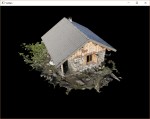 Vulkan (précedemment connu sous le nom d'OpenGL Next) est une interface de programmation graphique destinée à remplacer OpenGL. Plus moderne et plus efficace, il vise à unifier les versions mobiles (OpenGL ES) et bureau (OpenGL).
Vulkan (précedemment connu sous le nom d'OpenGL Next) est une interface de programmation graphique destinée à remplacer OpenGL. Plus moderne et plus efficace, il vise à unifier les versions mobiles (OpenGL ES) et bureau (OpenGL).
Je m'y suis mis pour tester, et c'est clairement un gros dépoussiérage d'OpenGL. Tout est plus clair (simplification), plus direct (suppression des fonctionnalités obsolètes ou redondantes), etc.
mer. 25 janv. 2017 10:05:26 CET -
-
link
- https://vulkan-tutorial.com/Loading_models
3d
Je m'y suis mis pour tester, et c'est clairement un gros dépoussiérage d'OpenGL. Tout est plus clair (simplification), plus direct (suppression des fonctionnalités obsolètes ou redondantes), etc.
mer. 25 janv. 2017 10:05:26 CET -
-
link
- https://vulkan-tutorial.com/Loading_models
3d
git-flow cheatsheet
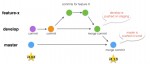 Comprendre git-flow en une infographie.
Comprendre git-flow en une infographie.
mer. 25 janv. 2017 10:00:51 CET -
-
link
- http://danielkummer.github.io/git-flow-cheatsheet/
git outil
mer. 25 janv. 2017 10:00:51 CET -
-
link
- http://danielkummer.github.io/git-flow-cheatsheet/
git outil
Seamless Cloning using OpenCV ( Python , C++ ) | Learn OpenCV
 Utilisation du Seamless Clone d'OpenCV pour fusionner deux images.
Utilisation du Seamless Clone d'OpenCV pour fusionner deux images.
mer. 25 janv. 2017 09:59:21 CET -
-
link
- http://www.learnopencv.com/seamless-cloning-using-opencv-python-cpp/
image-processing image 2d opencv
mer. 25 janv. 2017 09:59:21 CET -
-
link
- http://www.learnopencv.com/seamless-cloning-using-opencv-python-cpp/
image-processing image 2d opencv
Face Swap using OpenCV ( C++ / Python ) | Learn OpenCV
 Je me suis mis à OpenCV récemment pour développer un outil de redimensionnement d'image avec détection de visage. J'en parlerais peut être dans le blog technique, vu que j'ai rencontré pas mal de soucis avec sa compilation et son binding JNI.
Je me suis mis à OpenCV récemment pour développer un outil de redimensionnement d'image avec détection de visage. J'en parlerais peut être dans le blog technique, vu que j'ai rencontré pas mal de soucis avec sa compilation et son binding JNI.
Bref, je suis tombé sur cet article décrivant comment faire du "face swapping" avec la librairie.
mer. 25 janv. 2017 09:54:59 CET -
-
link
- http://www.learnopencv.com/face-swap-using-opencv-c-python/
image-processing image 2d opencv
Bref, je suis tombé sur cet article décrivant comment faire du "face swapping" avec la librairie.
mer. 25 janv. 2017 09:54:59 CET -
-
link
- http://www.learnopencv.com/face-swap-using-opencv-c-python/
image-processing image 2d opencv
htop-explique | Le blog de Carl Chenet
 Traduction française de l'excellent "htop explained": https://peteris.rocks/blog/htop
Traduction française de l'excellent "htop explained": https://peteris.rocks/blog/htop
mer. 25 janv. 2017 09:51:14 CET -
-
link
- https://carlchenet.com/category/htop-explique/
htop outil
mer. 25 janv. 2017 09:51:14 CET -
-
link
- https://carlchenet.com/category/htop-explique/
htop outil
The Infinite Drum Machine
 Une expérience de classification automatique sur des fichiers audio représentant des sons du quotidien. L'algorithme ne reçoit aucune information à priori (non supervisé) hormis les fichiers audio. La technique utilisée dans cette expérience est t-SNE (t-Distributed Stochastic Neighbor Embedding), permettant de réduire un espace à n dimensions vers un espace plus petit (ici 3 dimensions: X, Y, et couleur).
Une expérience de classification automatique sur des fichiers audio représentant des sons du quotidien. L'algorithme ne reçoit aucune information à priori (non supervisé) hormis les fichiers audio. La technique utilisée dans cette expérience est t-SNE (t-Distributed Stochastic Neighbor Embedding), permettant de réduire un espace à n dimensions vers un espace plus petit (ici 3 dimensions: X, Y, et couleur).
Description de t-SNE: http://jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
mer. 25 janv. 2017 09:47:44 CET -
-
link
- https://aiexperiments.withgoogle.com/drum-machine
machine-learning datamining clustering
Description de t-SNE: http://jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
mer. 25 janv. 2017 09:47:44 CET -
-
link
- https://aiexperiments.withgoogle.com/drum-machine
machine-learning datamining clustering
How to Write Papers So People Can Read Them - POPL 2016
 Comment écrire des articles scientifiques compréhensibles (certains principes généraux s'appliquent pour tout travail d'écriture).
Comment écrire des articles scientifiques compréhensibles (certains principes généraux s'appliquent pour tout travail d'écriture).
Les slides: https://www.mpi-sws.org/~dreyer/talks/talk-plmw16.pdf
mer. 25 janv. 2017 09:29:47 CET -
-
link
- https://youtu.be/L_6xoMjFr70
écriture
Les slides: https://www.mpi-sws.org/~dreyer/talks/talk-plmw16.pdf
mer. 25 janv. 2017 09:29:47 CET -
-
link
- https://youtu.be/L_6xoMjFr70
écriture
CDNs aren't just for caching - Julia Evans
 Un CDN ne sert pas qu'à faire du caching, mais aussi à:
Un CDN ne sert pas qu'à faire du caching, mais aussi à:
- amener le contenu au plus près des clients, donc accélérer l'accès
- accélérer l'ouverture des connexions TLS (https://en.wikipedia.org/wiki/Transport_Layer_Security#TLS_handshake)
- réduire l'impact des attaques par déni de service
mer. 25 janv. 2017 09:17:28 CET -
-
link
- http://jvns.ca/blog/2016/04/29/cdns-arent-just-for-caching/
cdn
- amener le contenu au plus près des clients, donc accélérer l'accès
- accélérer l'ouverture des connexions TLS (https://en.wikipedia.org/wiki/Transport_Layer_Security#TLS_handshake)
- réduire l'impact des attaques par déni de service
mer. 25 janv. 2017 09:17:28 CET -
-
link
- http://jvns.ca/blog/2016/04/29/cdns-arent-just-for-caching/
cdn
Séries de Fourier
 Voir aussi: http://www.benjaminbillet.fr/news/index.php?link=d5gw8e
Voir aussi: http://www.benjaminbillet.fr/news/index.php?link=d5gw8e
mer. 25 janv. 2017 09:10:18 CET -
-
link
- http://licence-eea.fr/series-de-fourier/
mathématiques signal-processing
mer. 25 janv. 2017 09:10:18 CET -
-
link
- http://licence-eea.fr/series-de-fourier/
mathématiques signal-processing
DBeaver | Free Universal SQL Client
"Free multi-platform database tool for developers, SQL programmers, database administrators and analysts. Supports all popular databases: MySQL, PostgreSQL, SQLite, Oracle, DB2, SQL Server, Sybase, Teradata, MongoDB, Cassandra, Redis, etc."
Et plus stable que MySQL workbench.
mer. 25 janv. 2017 09:03:47 CET -
-
link
- http://dbeaver.jkiss.org/
bdd
Et plus stable que MySQL workbench.
mer. 25 janv. 2017 09:03:47 CET -
-
link
- http://dbeaver.jkiss.org/
bdd
A Year Without a Byte | code.flickr.com
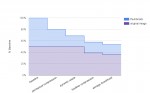 Quelques techniques utilisées par Flickr pour économiser l'espace de stockage.
Quelques techniques utilisées par Flickr pour économiser l'espace de stockage.
- Pour éviter des baisses de performance, on conserve toujours un peu d'espace disque libre (traditionnellement 10%). Toutefois, ce paramètre peut être ajusté empiriquement en fonction de l'usage (ici, réduit à 5%)
- Stocker moins de formats de miniature et laisser les clients (webs et mobiles) ajuster la taille de leur côté. Par exemple, si un client a besoin d'afficher une image en 1024x1024px, il va télécharger la version 2048x2048 et effectuer la réduction de son côté.
- Utiliser des algorithmes de compression d'image plus sophistiqués. Ces techniques consomment plus de CPU, mais peuvent réduire significativement la taille des images. Là encore, c'est à voir en fonction du besoin.
mer. 25 janv. 2017 08:56:13 CET -
-
link
- https://code.flickr.net/2017/01/05/a-year-without-a-byte/
stockage
- Pour éviter des baisses de performance, on conserve toujours un peu d'espace disque libre (traditionnellement 10%). Toutefois, ce paramètre peut être ajusté empiriquement en fonction de l'usage (ici, réduit à 5%)
- Stocker moins de formats de miniature et laisser les clients (webs et mobiles) ajuster la taille de leur côté. Par exemple, si un client a besoin d'afficher une image en 1024x1024px, il va télécharger la version 2048x2048 et effectuer la réduction de son côté.
- Utiliser des algorithmes de compression d'image plus sophistiqués. Ces techniques consomment plus de CPU, mais peuvent réduire significativement la taille des images. Là encore, c'est à voir en fonction du besoin.
mer. 25 janv. 2017 08:56:13 CET -
-
link
- https://code.flickr.net/2017/01/05/a-year-without-a-byte/
stockage
GitHub - tdebatty/java-string-similarity: Implementation of various string similarity and distance algorithms: Levenshtein, Jaro-winkler, n-Gram, Q-Gr
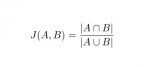 Une librairie Java pour calculer des distances ou des scores de similarité entre des chaînes de caractères.
Une librairie Java pour calculer des distances ou des scores de similarité entre des chaînes de caractères.
Algorithmes implémentés :
Levenshtein O(m*n)
Normalized Levenshtein O(m*n)
Weighted Levenshtein O(m*n)
Damerau-Levenshtein O(m*n)
Optimal String Alignment O(m*n)
Jaro-Winkler O(m*n)
Longest Common Subsequence O(m*n)
Metric Longest Common Subsequence O(m*n)
N-Gram O(m*n)
Q-Gram O(m+n)
Cosine similarity O(m+n)
Jaccard index O(m+n)
Sorensen-Dice coefficient O(m+n)
mer. 19 oct. 2016 12:38:50 CEST -
-
link
- https://github.com/tdebatty/java-string-similarity
similarité java algorithmique
Algorithmes implémentés :
Levenshtein O(m*n)
Normalized Levenshtein O(m*n)
Weighted Levenshtein O(m*n)
Damerau-Levenshtein O(m*n)
Optimal String Alignment O(m*n)
Jaro-Winkler O(m*n)
Longest Common Subsequence O(m*n)
Metric Longest Common Subsequence O(m*n)
N-Gram O(m*n)
Q-Gram O(m+n)
Cosine similarity O(m+n)
Jaccard index O(m+n)
Sorensen-Dice coefficient O(m+n)
mer. 19 oct. 2016 12:38:50 CEST -
-
link
- https://github.com/tdebatty/java-string-similarity
similarité java algorithmique
FarmBot
 FarmBot, un robot pour contrôler une petite plantation. Il peut planter, contrôler l'arrosage, détecter et tuer les mauvaises herbes, etc.
FarmBot, un robot pour contrôler une petite plantation. Il peut planter, contrôler l'arrosage, détecter et tuer les mauvaises herbes, etc.
C'est un bien beau bidule, il faut avouer.
Les plans sont open-source, ce qui est un bon point, mais la fabrication des pièces nécessite d'être bien équipé (imprimante 3D, outil de découpe du métal).
Possibilité de commander un kit de pièces pour 3500$, ce qui est malheureusement beaucoup trop cher :/
lun. 17 oct. 2016 16:16:37 CEST -
-
link
- http://i.imgur.com/L4D8gJN.mp4
robotique
C'est un bien beau bidule, il faut avouer.
Les plans sont open-source, ce qui est un bon point, mais la fabrication des pièces nécessite d'être bien équipé (imprimante 3D, outil de découpe du métal).
Possibilité de commander un kit de pièces pour 3500$, ce qui est malheureusement beaucoup trop cher :/
lun. 17 oct. 2016 16:16:37 CEST -
-
link
- http://i.imgur.com/L4D8gJN.mp4
robotique
Megaprocessor
 Traduction de la page d'accueil du projet:
Traduction de la page d'accueil du projet:
Qu'est-ce que c'est ? Le Megaprocessor est un microprocesseur, mais construit en plus gros. Beaucoup plus gros.
Comment ? Comme tous les processeurs modernes, le Megaprocessor fonctionne avec des transistors. Par contre, au lieu d'utiliser des transistors gravés sur une minuscule puce en silicium, il utilise des transistors individuels (NB: taille équivalente à un cube de 0.5 cm de côté). Par milliers. Et aussi énormément de LED (NB: diode électro-luminescente).
Pourquoi ? Réponse courte : Parce que je le voulais.
Pourquoi ? Réponse longue : Les ordinateurs sont plutôt opaques, il est impossible de comprendre comment ils marchent en regardant à l'intérieur. Ce que j'ai voulu faire, c'est entrer à l'intérieur et voir ce qui se passe. Le souci, c'est qu'on ne peut pas se rétrécir suffisamment pour marcher à l'intérieur d'une puce de silicium. Par contre, on peut faire le contraire : construire un processeur suffisamment gros pour marcher à l'intérieur. En plus, en ajoutant plein de LEDs, on pourrait VOIR les données circuler et les opérations logiques s'effectuer en temps réel. Ce serait génial.
--
Et je confirme : c'est génial. On peut même le programmer avec un assembleur basique (http://megaprocessor.com/programming.html)
lun. 17 oct. 2016 16:10:26 CEST -
-
link
- http://megaprocessor.com/
processeur électronique
Qu'est-ce que c'est ? Le Megaprocessor est un microprocesseur, mais construit en plus gros. Beaucoup plus gros.
Comment ? Comme tous les processeurs modernes, le Megaprocessor fonctionne avec des transistors. Par contre, au lieu d'utiliser des transistors gravés sur une minuscule puce en silicium, il utilise des transistors individuels (NB: taille équivalente à un cube de 0.5 cm de côté). Par milliers. Et aussi énormément de LED (NB: diode électro-luminescente).
Pourquoi ? Réponse courte : Parce que je le voulais.
Pourquoi ? Réponse longue : Les ordinateurs sont plutôt opaques, il est impossible de comprendre comment ils marchent en regardant à l'intérieur. Ce que j'ai voulu faire, c'est entrer à l'intérieur et voir ce qui se passe. Le souci, c'est qu'on ne peut pas se rétrécir suffisamment pour marcher à l'intérieur d'une puce de silicium. Par contre, on peut faire le contraire : construire un processeur suffisamment gros pour marcher à l'intérieur. En plus, en ajoutant plein de LEDs, on pourrait VOIR les données circuler et les opérations logiques s'effectuer en temps réel. Ce serait génial.
--
Et je confirme : c'est génial. On peut même le programmer avec un assembleur basique (http://megaprocessor.com/programming.html)
lun. 17 oct. 2016 16:10:26 CEST -
-
link
- http://megaprocessor.com/
processeur électronique
98 personal data points that Facebook uses to target ads to you - The Washington Post
 Facebook utilise 98 informations vous concernant pour déterminer quelles sont les publicités les plus susceptibles de vous intéresser.
Facebook utilise 98 informations vous concernant pour déterminer quelles sont les publicités les plus susceptibles de vous intéresser.
9. Ethnic affinity
...
20. Users in long-distance relationships
...
31. Conservatives and liberals
...
45. How much money user is likely to spend on next car
...
79. Users who are “heavy” buyers of beer, wine or spirits
...
82. Users who buy allergy medications, cough/cold medications, pain relief products, and over-the-counter meds
...
89. Users who are “receptive” to offers from companies offering online auto insurance, higher education or mortgages, and prepaid debit cards/satellite TV
Effrayant.
lun. 17 oct. 2016 15:36:20 CEST -
-
link
- https://www.washingtonpost.com/news/the-intersect/wp/2016/08/19/98-personal-data-points-that-facebook-uses-to-target-ads-to-you/
vie-privée publicité bêtise
9. Ethnic affinity
...
20. Users in long-distance relationships
...
31. Conservatives and liberals
...
45. How much money user is likely to spend on next car
...
79. Users who are “heavy” buyers of beer, wine or spirits
...
82. Users who buy allergy medications, cough/cold medications, pain relief products, and over-the-counter meds
...
89. Users who are “receptive” to offers from companies offering online auto insurance, higher education or mortgages, and prepaid debit cards/satellite TV
Effrayant.
lun. 17 oct. 2016 15:36:20 CEST -
-
link
- https://www.washingtonpost.com/news/the-intersect/wp/2016/08/19/98-personal-data-points-that-facebook-uses-to-target-ads-to-you/
vie-privée publicité bêtise
How to measure smartphone power usage |
 Mesurer la consommation électrique d'un smartphone. Testé et approuvé.
Mesurer la consommation électrique d'un smartphone. Testé et approuvé.
lun. 17 oct. 2016 15:31:06 CEST -
-
link
- http://www.epanorama.net/newepa/2014/04/28/how-to-measure-smartphone-power-usage/
mesure
lun. 17 oct. 2016 15:31:06 CEST -
-
link
- http://www.epanorama.net/newepa/2014/04/28/how-to-measure-smartphone-power-usage/
mesure
Welcome! — Pygments
 Pygments, coloration syntaxique (export RTF possible, permettant de copier-coller le code formaté dans une présentation, par exemple).
Pygments, coloration syntaxique (export RTF possible, permettant de copier-coller le code formaté dans une présentation, par exemple).
lun. 17 oct. 2016 15:29:04 CEST -
-
link
- http://pygments.org/
python coloration
lun. 17 oct. 2016 15:29:04 CEST -
-
link
- http://pygments.org/
python coloration
xkcd: Automation
 C'est bien vu. Préférez toujours la réutilisation d'un code existant, une librairie ou un outil plutôt que vos propres codes (qui devront malheureusement être maintenus). Toutes proportions gardées, bien entendu.
C'est bien vu. Préférez toujours la réutilisation d'un code existant, une librairie ou un outil plutôt que vos propres codes (qui devront malheureusement être maintenus). Toutes proportions gardées, bien entendu.
lun. 17 oct. 2016 15:27:31 CEST -
-
link
- https://xkcd.com/1319/
humour
lun. 17 oct. 2016 15:27:31 CEST -
-
link
- https://xkcd.com/1319/
humour
Procedural Content Generation in Games | A textbook and an overview of current research
 La synthèse procédurale de contenu pour les jeux vidéos est un sujet qui m'intéresse beaucoup. J'en ai fait un tour d'horizon pour la fête de la science à l'INRIA (http://benjaminbillet.fr/wiki/doku.php?id=fete_de_la_science_2012) mais en voici un textbook beaucoup plus complet :)
La synthèse procédurale de contenu pour les jeux vidéos est un sujet qui m'intéresse beaucoup. J'en ai fait un tour d'horizon pour la fête de la science à l'INRIA (http://benjaminbillet.fr/wiki/doku.php?id=fete_de_la_science_2012) mais en voici un textbook beaucoup plus complet :)
1 Introduction
2 The search-based approach
3 Constructive generation methods for dungeons and levels
4 Fractals, noise and agents with applications to landscapes and textures
5 Grammars and L-systems with applications to vegetation and levels
6 Rules and mechanics
7 Planning with applications to quests and story
8 ASP with applications to mazes and levels
9 Representations for search-based methods
10 The experience-driven perspective
11 Mixed-initiative approaches
12 Evaluating content generators
On y retrouve de nombreux sujets abordés dans ma présentation, mais avec plus d'excellents chapitres sur la génération de règles, de gameplay, de scénarios et de quêtes.
lun. 17 oct. 2016 15:23:22 CEST -
-
link
- http://pcgbook.com/
pcg synthèse-procédurale
1 Introduction
2 The search-based approach
3 Constructive generation methods for dungeons and levels
4 Fractals, noise and agents with applications to landscapes and textures
5 Grammars and L-systems with applications to vegetation and levels
6 Rules and mechanics
7 Planning with applications to quests and story
8 ASP with applications to mazes and levels
9 Representations for search-based methods
10 The experience-driven perspective
11 Mixed-initiative approaches
12 Evaluating content generators
On y retrouve de nombreux sujets abordés dans ma présentation, mais avec plus d'excellents chapitres sur la génération de règles, de gameplay, de scénarios et de quêtes.
lun. 17 oct. 2016 15:23:22 CEST -
-
link
- http://pcgbook.com/
pcg synthèse-procédurale
7 techniques mathématiques
 1. La descente de gradient
1. La descente de gradient
2. Le kdtree
3. La décomposition en valeurs singulières
4. La dimension de Vapnik-chervonenkis
5. Distributed Stochastic Neighboor Embedding
6. Radial basis Kernel trick
7. Affinity Propagation Clustering
lun. 17 oct. 2016 15:16:59 CEST -
-
link
- https://li.st/l/f00d8e06-3e49-4a69-97eb-dc3729b808f5
mathématiques
2. Le kdtree
3. La décomposition en valeurs singulières
4. La dimension de Vapnik-chervonenkis
5. Distributed Stochastic Neighboor Embedding
6. Radial basis Kernel trick
7. Affinity Propagation Clustering
lun. 17 oct. 2016 15:16:59 CEST -
-
link
- https://li.st/l/f00d8e06-3e49-4a69-97eb-dc3729b808f5
mathématiques
Une introduction aux arbres de décision
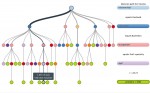 Résumé :
Résumé :
Les arbres de décision sont l’une des structures de données majeures de l’apprentissage statistique. Leur fonctionnement repose sur des heuristiques qui, tout en satisfaisant l’intuition, donnent des résultats remarquables en pratique (notamment lorsqu’ils sont utilisés en « forêts aléatoires »). Leur structure arborescente les rend également lisibles par un être humain, contrairement à d’autres approches où le prédicteur construit est une « boîte noire ».
L’introduction que nous proposons ici décrit les bases de leur fonctionnement tout en apportant quelques justifications théoriques. Nous aborderons aussi (brièvement) l’extension aux Random Forests. On supposera le lecteur familier avec le contexte général de l’apprentissage supervisé.1
lun. 17 oct. 2016 15:10:56 CEST -
-
link
- https://scaron.info/doc/intro-arbres-decision/
machine-learning mathématiques
Les arbres de décision sont l’une des structures de données majeures de l’apprentissage statistique. Leur fonctionnement repose sur des heuristiques qui, tout en satisfaisant l’intuition, donnent des résultats remarquables en pratique (notamment lorsqu’ils sont utilisés en « forêts aléatoires »). Leur structure arborescente les rend également lisibles par un être humain, contrairement à d’autres approches où le prédicteur construit est une « boîte noire ».
L’introduction que nous proposons ici décrit les bases de leur fonctionnement tout en apportant quelques justifications théoriques. Nous aborderons aussi (brièvement) l’extension aux Random Forests. On supposera le lecteur familier avec le contexte général de l’apprentissage supervisé.1
lun. 17 oct. 2016 15:10:56 CEST -
-
link
- https://scaron.info/doc/intro-arbres-decision/
machine-learning mathématiques
GitHub - dokan-dev/dokany: User mode file system library for windows with FUSE Wrapper
 Génial, un équivalent à FUSE (Filesystem in Userspace) pour Windows. Il s'agit d'une interface permettant d'écrire des systèmes de fichier "virtuels", c'est-à-dire ne nécessitant pas de modifier le noyau du système d'exploitation pour fonctionner.
Génial, un équivalent à FUSE (Filesystem in Userspace) pour Windows. Il s'agit d'une interface permettant d'écrire des systèmes de fichier "virtuels", c'est-à-dire ne nécessitant pas de modifier le noyau du système d'exploitation pour fonctionner.
C'est une fonctionnalité qui a toujours manqué à Windows.
jeu. 22 sept. 2016 14:29:10 CEST -
-
link
- https://github.com/dokan-dev/dokany
outil programmation système
C'est une fonctionnalité qui a toujours manqué à Windows.
jeu. 22 sept. 2016 14:29:10 CEST -
-
link
- https://github.com/dokan-dev/dokany
outil programmation système
Oh, shit, git!
 Une collection d'astuces pour rattraper les (petites) erreurs de manipulation avec git. Par exemple corriger le message d'un commit, amender un commit, etc.
Une collection d'astuces pour rattraper les (petites) erreurs de manipulation avec git. Par exemple corriger le message d'un commit, amender un commit, etc.
jeu. 22 sept. 2016 14:22:56 CEST -
-
link
- http://ohshitgit.com/
git outil
jeu. 22 sept. 2016 14:22:56 CEST -
-
link
- http://ohshitgit.com/
git outil
How Not To Sort By Average Rating
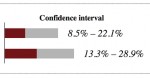 Une meilleure méthode pour la gestion des notations. Cette technique prend en compte à la fois la proportion de notes positives et la taille de l'échantillon.
Une meilleure méthode pour la gestion des notations. Cette technique prend en compte à la fois la proportion de notes positives et la taille de l'échantillon.
sam. 06 août 2016 15:08:43 CEST -
-
link
- http://www.evanmiller.org/how-not-to-sort-by-average-rating.html
mathématiques
sam. 06 août 2016 15:08:43 CEST -
-
link
- http://www.evanmiller.org/how-not-to-sort-by-average-rating.html
mathématiques
Elm – fun with L-System (Part 1) | theburningmonk.com
 Un L-Système ou système de Lindenmayer est une grammaire formelle permettant de décrire un ensemble de règles et de symboles qui modélisent un processus de croissance.
Un L-Système ou système de Lindenmayer est une grammaire formelle permettant de décrire un ensemble de règles et de symboles qui modélisent un processus de croissance.
Les symboles représentent l'état de l'être vivant à une itération X, tandis que les règles représentent la transformation des symboles en autres symboles (ou groupes de symboles). A partir de l'état X, les règles permettent de construire l'état X+1 et ainsi de suite jusqu'à obtenir une structure complexe.
J'ai traité le sujet des L-Systèmes lors de la fête de la science 2012 à l'INRIA. Voir ma présentation ici : http://benjaminbillet.fr/wiki/doku.php?id=fete_de_la_science_2012
Voir aussi : http://blog.rabidgremlin.com/2014/12/09/procedural-content-generation-l-systems/
sam. 06 août 2016 14:56:37 CEST -
-
link
- http://theburningmonk.com/2015/10/elm-fun-with-l-system-part-1/
synthèse-procédurale
Les symboles représentent l'état de l'être vivant à une itération X, tandis que les règles représentent la transformation des symboles en autres symboles (ou groupes de symboles). A partir de l'état X, les règles permettent de construire l'état X+1 et ainsi de suite jusqu'à obtenir une structure complexe.
J'ai traité le sujet des L-Systèmes lors de la fête de la science 2012 à l'INRIA. Voir ma présentation ici : http://benjaminbillet.fr/wiki/doku.php?id=fete_de_la_science_2012
Voir aussi : http://blog.rabidgremlin.com/2014/12/09/procedural-content-generation-l-systems/
sam. 06 août 2016 14:56:37 CEST -
-
link
- http://theburningmonk.com/2015/10/elm-fun-with-l-system-part-1/
synthèse-procédurale
Shadertoy BETA
 Un shader est un programme permettant de paramétrer une partie du pipeline de rendu réalisé par une carte graphique ou un moteur de rendu logiciel. Ces programmes sont exécutés directement par le GPU de la machine, étant donné que ces programmes effectuent de nombreuses opérations vectorielles pour lesquelles le GPU est très efficace.
Un shader est un programme permettant de paramétrer une partie du pipeline de rendu réalisé par une carte graphique ou un moteur de rendu logiciel. Ces programmes sont exécutés directement par le GPU de la machine, étant donné que ces programmes effectuent de nombreuses opérations vectorielles pour lesquelles le GPU est très efficace.
Il existe des shaders de plusieurs types, qui influent sur différentes étapes du pipeline, les plus connus étant les "vertex shaders" (qui influent sur la projection de l'espace 3D sur l'espace 2D) et les "pixel shaders" (qui influent sur les pixels).
Cet outil permet d'écrire des shaders en ligne et de les tester directement. Il y a des choses assez impressionnantes.
sam. 06 août 2016 14:42:48 CEST -
-
link
- https://www.shadertoy.com/
3d shader
Il existe des shaders de plusieurs types, qui influent sur différentes étapes du pipeline, les plus connus étant les "vertex shaders" (qui influent sur la projection de l'espace 3D sur l'espace 2D) et les "pixel shaders" (qui influent sur les pixels).
Cet outil permet d'écrire des shaders en ligne et de les tester directement. Il y a des choses assez impressionnantes.
sam. 06 août 2016 14:42:48 CEST -
-
link
- https://www.shadertoy.com/
3d shader
Blog Stéphane Bortzmeyer: RFC 7616: HTTP Digest Access Authentication
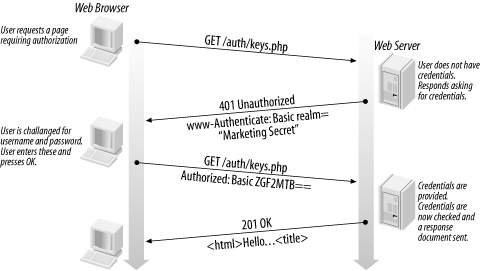 Moralité : peu importe que vous utilisiez le mécanisme d'identification/authentification Basic ou Digest, TLS est requis pour éviter (i) les attaques de l'homme du milieu, (ii) la transmission en clair du contenu autorisé.
Moralité : peu importe que vous utilisiez le mécanisme d'identification/authentification Basic ou Digest, TLS est requis pour éviter (i) les attaques de l'homme du milieu, (ii) la transmission en clair du contenu autorisé.
Qui plus est, ces mécanismes d'identification/authentification HTTP ne gérent pas d'état : il n'est pas possible pour le serveur de forcer l'utilisateur à se réauthentifier et il n'est pas non plus possible pour le client de se déconnecter (lire http://www.bortzmeyer.org/7235.html). En pratique, il vaut donc mieux privilégier un formulaire Web pour la saisie du mot de passe, puis un cookie/clé de session associée à chaque requête.
sam. 06 août 2016 14:30:11 CEST -
-
link
- http://www.bortzmeyer.org/7616.html
sécurité http
Qui plus est, ces mécanismes d'identification/authentification HTTP ne gérent pas d'état : il n'est pas possible pour le serveur de forcer l'utilisateur à se réauthentifier et il n'est pas non plus possible pour le client de se déconnecter (lire http://www.bortzmeyer.org/7235.html). En pratique, il vaut donc mieux privilégier un formulaire Web pour la saisie du mot de passe, puis un cookie/clé de session associée à chaque requête.
sam. 06 août 2016 14:30:11 CEST -
-
link
- http://www.bortzmeyer.org/7616.html
sécurité http
Blog Stéphane Bortzmeyer: Un bel exemple de logiciels de sécurité dangereux
 L'interception TLS est une technique permettant aux antivirus ou aux proxy d'entreprise de déchiffrer les flux TLS. Par exemple, un antivirus va ajouter son autorité de certification à la base des autorités de confiance maintenue par le système. De cette façon, l'antivirus peut forger de faux certificats valides pour les domaines visités et, de fait, intercepter le trafic chiffré.
L'interception TLS est une technique permettant aux antivirus ou aux proxy d'entreprise de déchiffrer les flux TLS. Par exemple, un antivirus va ajouter son autorité de certification à la base des autorités de confiance maintenue par le système. De cette façon, l'antivirus peut forger de faux certificats valides pour les domaines visités et, de fait, intercepter le trafic chiffré.
Grâce à cela, l'antivirus peut vérifier que les flux chiffrés ne sont pas émis par un logiciel malveillant. Dans le cas des proxy d'entreprise, cela permet de vérifier les communications qui sortent de l'entreprise.
Cette technique est un détournement délibéré du modèle de sécurité de TLS et doit donc être implémentée de façon irréprochable pour ne pas compromettre la sécurité. Des chercheurs viennent de montrer qu'un grand nombre de ces logiciels ne sont pas irréprochables et possèdent des failles graves.
sam. 06 août 2016 14:21:51 CEST -
-
link
- http://www.bortzmeyer.org/killed-by-proxy.html
sécurité
Grâce à cela, l'antivirus peut vérifier que les flux chiffrés ne sont pas émis par un logiciel malveillant. Dans le cas des proxy d'entreprise, cela permet de vérifier les communications qui sortent de l'entreprise.
Cette technique est un détournement délibéré du modèle de sécurité de TLS et doit donc être implémentée de façon irréprochable pour ne pas compromettre la sécurité. Des chercheurs viennent de montrer qu'un grand nombre de ces logiciels ne sont pas irréprochables et possèdent des failles graves.
sam. 06 août 2016 14:21:51 CEST -
-
link
- http://www.bortzmeyer.org/killed-by-proxy.html
sécurité
Home — Doctrine Project
 Doctrine, un ORM (object-relational mapper) pour PHP.
Doctrine, un ORM (object-relational mapper) pour PHP.
sam. 06 août 2016 14:01:16 CEST -
-
link
- http://www.doctrine-project.org
php orm
sam. 06 août 2016 14:01:16 CEST -
-
link
- http://www.doctrine-project.org
php orm
Apache Mynewt
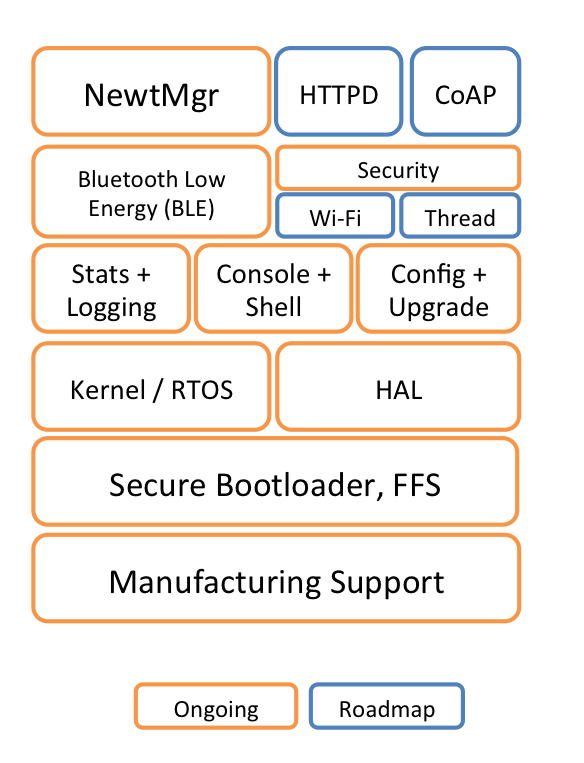
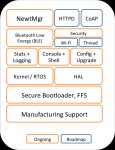 Apache Mynewt est un nouveau système d'exploitation temps réel pour les objets connectés (IoT) ayant des ressources très limitées. Supporte Bluetooth Low Energy pour la communication.
Apache Mynewt est un nouveau système d'exploitation temps réel pour les objets connectés (IoT) ayant des ressources très limitées. Supporte Bluetooth Low Energy pour la communication.
Roadmap: http://mynewt.apache.org/img/OS_arch.png
sam. 06 août 2016 13:59:08 CEST -
-
link
- http://mynewt.apache.org/
iot
Roadmap: http://mynewt.apache.org/img/OS_arch.png
{kind=link} sam. 06 août 2016 13:59:08 CEST -
-
link
- http://mynewt.apache.org/
iot
sam. 06 août 2016 13:59:08 CEST -
-
link
- http://mynewt.apache.org/
iot
Linux workstation security checklist
 Une liste de chose à vérifier pour améliorer la sécurité des postes de travail. Destiné plutôt aux administrateurs systèmes.
Une liste de chose à vérifier pour améliorer la sécurité des postes de travail. Destiné plutôt aux administrateurs systèmes.
sam. 06 août 2016 13:56:29 CEST -
-
link
- https://github.com/lfit/itpol/blob/master/linux-workstation-security.md
sécurité administration-système linux
sam. 06 août 2016 13:56:29 CEST -
-
link
- https://github.com/lfit/itpol/blob/master/linux-workstation-security.md
sécurité administration-système linux
Sockets en C
 Quelques documentations sur les sockets en C (bloquante, non bloquante, IPv6, etc.)
Quelques documentations sur les sockets en C (bloquante, non bloquante, IPv6, etc.)
http://www.scottklement.com/rpg/socktut/tutorial.html
http://www.tldp.org/HOWTO/Linux+IPv6-HOWTO/chapter-section-using-api.html
http://www.beej.us/guide/bgnet/output/html/singlepage/bgnet.html
http://mff.devnull.cz/pvu/src/tcp/
sam. 06 août 2016 13:47:04 CEST -
-
link
socket C/C++
http://www.scottklement.com/rpg/socktut/tutorial.html
http://www.tldp.org/HOWTO/Linux+IPv6-HOWTO/chapter-section-using-api.html
http://www.beej.us/guide/bgnet/output/html/singlepage/bgnet.html
http://mff.devnull.cz/pvu/src/tcp/
sam. 06 août 2016 13:47:04 CEST -
-
link
socket C/C++
How to implement the discrete Fourier transform
 Implémentation de la transformée de fourier discrète (DFT).
Implémentation de la transformée de fourier discrète (DFT).
https://fr.wikipedia.org/wiki/Transformation_de_Fourier_discr%C3%A8te
https://github.com/cscheiblich/jwave
sam. 06 août 2016 13:38:35 CEST -
-
link
- https://www.nayuki.io/page/how-to-implement-the-discrete-fourier-transform
dft
https://fr.wikipedia.org/wiki/Transformation_de_Fourier_discr%C3%A8te
https://github.com/cscheiblich/jwave
sam. 06 août 2016 13:38:35 CEST -
-
link
- https://www.nayuki.io/page/how-to-implement-the-discrete-fourier-transform
dft
WTF, HTML and CSS?
 Quelques problèmes HTML/CSS courants, et leurs solutions.
Quelques problèmes HTML/CSS courants, et leurs solutions.
sam. 06 août 2016 13:17:12 CEST -
-
link
- http://wtfhtmlcss.com/
css html
sam. 06 août 2016 13:17:12 CEST -
-
link
- http://wtfhtmlcss.com/
css html
An A-Z Index of the Bash command line | SS64.com
 An A-Z Index of the Bash command line for Linux.
An A-Z Index of the Bash command line for Linux.
sam. 06 août 2016 13:13:54 CEST -
-
link
- http://ss64.com/bash/index.html
bash linux
sam. 06 août 2016 13:13:54 CEST -
-
link
- http://ss64.com/bash/index.html
bash linux
SpaceBook®
 Carte interactive de la position des satellites. C'est impressionnant le nombre de satellites qui ne sont plus en fonctionnement.
Carte interactive de la position des satellites. C'est impressionnant le nombre de satellites qui ne sont plus en fonctionnement.
jeu. 19 mai 2016 16:51:09 CEST -
-
link
- http://apps.agi.com/SatelliteViewer/
jeu. 19 mai 2016 16:51:09 CEST -
-
link
- http://apps.agi.com/SatelliteViewer/
Choosing an HTTP Status Code — Stop Making It Hard – Racksburg
 Choisir ses codes HTTP pour une API REST. Quelques trucs sont sans doute sujet à débat, mais c'est un point de départ intéressant.
Choisir ses codes HTTP pour une API REST. Quelques trucs sont sans doute sujet à débat, mais c'est un point de départ intéressant.
jeu. 12 mai 2016 09:25:34 CEST -
-
link
- http://racksburg.com/choosing-an-http-status-code/
rest http
jeu. 12 mai 2016 09:25:34 CEST -
-
link
- http://racksburg.com/choosing-an-http-status-code/
rest http
DeepMind AlphaGo vs Lee Sedol: AlphaGo 4 – Lee Sedol 1
 J'étais complètement passé à côté de ça. Beaucoup de spécialistes pensaient qu'une machine capable de battre les humains au Go était impossible, car le nombre de possibilités à explorer est plus grand que pour les échecs.
J'étais complètement passé à côté de ça. Beaucoup de spécialistes pensaient qu'une machine capable de battre les humains au Go était impossible, car le nombre de possibilités à explorer est plus grand que pour les échecs.
C'est une (petite) victoire pour moi, car j'avais anticipé cette possibilité dès que je m'étais intéressé aux techniques utilisées pour les jeux d'échecs. Concrètement, le Go n'est pas différent des échecs : il se résout par une exploration systématique. Bien entendu, le nombre de possibilité est très grand, mais il aura suffit de limiter l'exploration systématique aux solutions les plus prometteuses, grâce à des techniques d'apprentissage artificiel.
Les algorithmes mis en œuvre dans AlphaGo sont très anciens (plus de 20 ans) et il apparaît que le seul élément qui manquait jusqu'à lors était un investissement massif de temps et d'argent (ici Google) pour entraîner ces algorithmes avec des dizaines de milliers de parties. Ce n'est donc qu'un hasard du calendrier si c'est aujourd'hui qu'une IA remporte une victoire (écrasante il faut bien le dire) au jeu de Go.
De la même façon, il est possible d'affirmer, sans trop de risques, que TOUS les jeux à exploration systématique peuvent être attaqués avec le même type d'algorithmes.
Bref : Computer science, ruining everything since 1960 :)
lun. 09 mai 2016 17:35:28 CEST -
-
link
- https://gogameguru.com/tag/deepmind-alphago-lee-sedol/
informatique machine-learning
C'est une (petite) victoire pour moi, car j'avais anticipé cette possibilité dès que je m'étais intéressé aux techniques utilisées pour les jeux d'échecs. Concrètement, le Go n'est pas différent des échecs : il se résout par une exploration systématique. Bien entendu, le nombre de possibilité est très grand, mais il aura suffit de limiter l'exploration systématique aux solutions les plus prometteuses, grâce à des techniques d'apprentissage artificiel.
Les algorithmes mis en œuvre dans AlphaGo sont très anciens (plus de 20 ans) et il apparaît que le seul élément qui manquait jusqu'à lors était un investissement massif de temps et d'argent (ici Google) pour entraîner ces algorithmes avec des dizaines de milliers de parties. Ce n'est donc qu'un hasard du calendrier si c'est aujourd'hui qu'une IA remporte une victoire (écrasante il faut bien le dire) au jeu de Go.
De la même façon, il est possible d'affirmer, sans trop de risques, que TOUS les jeux à exploration systématique peuvent être attaqués avec le même type d'algorithmes.
Bref : Computer science, ruining everything since 1960 :)
lun. 09 mai 2016 17:35:28 CEST -
-
link
- https://gogameguru.com/tag/deepmind-alphago-lee-sedol/
informatique machine-learning
Brixo - Building Blocks Meet Electricity and IoT
 Encore un kickstarter intéressant dans le contexte de l'Internet des Objets : des sortes de légos connectés, embarquant des capteurs, des interfaces de communication ou simplement des connecteurs.
Encore un kickstarter intéressant dans le contexte de l'Internet des Objets : des sortes de légos connectés, embarquant des capteurs, des interfaces de communication ou simplement des connecteurs.
dim. 08 mai 2016 13:01:52 CEST -
-
link
- https://www.kickstarter.com/projects/1068475467/brixo-building-blocks-meet-electricity-and-iot
iot électronique
dim. 08 mai 2016 13:01:52 CEST -
-
link
- https://www.kickstarter.com/projects/1068475467/brixo-building-blocks-meet-electricity-and-iot
iot électronique
Voici le résultat d'une image sauvegardée 500 fois
 Intéressante expérience où une image est sauvegardée de multiple fois en utilisant un format d'image destructif. Je suis assez surpris de voir le WEBP à ce point dégrader l'image.
Intéressante expérience où une image est sauvegardée de multiple fois en utilisant un format d'image destructif. Je suis assez surpris de voir le WEBP à ce point dégrader l'image.
sam. 16 avril 2016 09:05:28 CEST -
-
link
- http://www.lesnumeriques.com/appareil-photo-numerique/voici-resultat-image-sauvegardee-500-fois-n51275.html
image format
sam. 16 avril 2016 09:05:28 CEST -
-
link
- http://www.lesnumeriques.com/appareil-photo-numerique/voici-resultat-image-sauvegardee-500-fois-n51275.html
image format
Identifying Image Format from the First Few Bytes
 Une heuristique simple pour identifier un type d'image à partir des premiers octets. L'algorithme donné est écrit en C++ mais peut s'adapter facilement à d'autres langages.
Une heuristique simple pour identifier un type d'image à partir des premiers octets. L'algorithme donné est écrit en C++ mais peut s'adapter facilement à d'autres langages.
.jpg: FF D8 FF
.png: 89 50 4E 47 0D 0A 1A 0A
.gif: GIF87a ou GIF89a
.tiff: 49 49 2A 00 ou 4D 4D 00 2A
.bmp: BM
.webp: RIFF ???? WEBP
.ico: 00 00 01 00 ou 00 00 02 00 (cursor files)
ven. 08 avril 2016 14:55:17 CEST -
-
link
- https://oroboro.com/image-format-magic-bytes/
format image
.jpg: FF D8 FF
.png: 89 50 4E 47 0D 0A 1A 0A
.gif: GIF87a ou GIF89a
.tiff: 49 49 2A 00 ou 4D 4D 00 2A
.bmp: BM
.webp: RIFF ???? WEBP
.ico: 00 00 01 00 ou 00 00 02 00 (cursor files)
ven. 08 avril 2016 14:55:17 CEST -
-
link
- https://oroboro.com/image-format-magic-bytes/
format image
Why I don’t use CSS preprocessors | 456 Berea Street
 C'est exactement mon ressenti vis à vis de ces outils, HTML et CSS sont déjà des langages de haut niveau, l'un pour décrire du contenu structuré l'autre pour décrire de la mise en forme. Il n'y a aucun intérêt à remplacer des langages uniques et standardisés par une multitude de DSL qui n'apportent, au final, pas grand chose si ce n'est une fragmentation indésirable en pratique.
C'est exactement mon ressenti vis à vis de ces outils, HTML et CSS sont déjà des langages de haut niveau, l'un pour décrire du contenu structuré l'autre pour décrire de la mise en forme. Il n'y a aucun intérêt à remplacer des langages uniques et standardisés par une multitude de DSL qui n'apportent, au final, pas grand chose si ce n'est une fragmentation indésirable en pratique.
Je copie l'article ici, pour mémoire :
Whenever I mention that I don’t use CSS preprocessors I tend to get strange looks from people who cannot imagine writing CSS without Sass. And so I have to defend my choice and explain why, over and over. Some people will understand, most won’t. Or they don’t want to. But here’s an attempt to explain my reasoning.
Back when CSS preprocessors first came into fashion I did try using them. And then every couple of years, due to external pressure and nagging, I have taken new looks and given them new chances. But to me they’ve always felt like solutions in need of a problem to solve. That is, I don’t really find the “problems” with CSS that preprocessors are intended to solve, problems. The scale of the site I’m building does not matter, be it a tiny site with just a few static pages or a humongous corporate intranet. I simply have never felt the need for mixins, nesting or extends.
A list of reasons then:
- I don’t feel the “problems” CSS preprocessors intend to solve are serious enough to warrant the cost, i.e. to me the solution is worse than the problem.
- I want absolute control of my CSS, which means I want to work hands on with it, and see exactly what will be sent to the browser (well, before it’s minified and gzipped, of course). If that means seeing the same declarations repeated in several rules, or having to see what vendor prefixes look like, so be it. To me, WET CSS is much more understandable and maintainable than DRY black box pseudo-CSS.
- I don’t want to learn and depend on a non-standard syntax to wrap my CSS in, making it require compilation before browsers can understand it. Neither do I want my colleagues to have to.
- I want my source CSS to be deployable at all times, albeit in un-minified, un-concatenated form. If my build process fails, for whatever reason (like an unpublished npm module), I can deploy the source CSS as an emergency solution. Performance may perhaps take a hit, but a slightly slower site is likely better than a site with broken or no CSS until the build process can be fixed.
- I don’t want to have to wait for compilation before seeing the results of my CSS changes. Processing time may be anything from negligible to frustrating, obviously, but if it takes longer than the time it takes for me to switch from my code editor to my browser and reload the page (≈1s) it’s too slow.
I’m fully aware that many people who use CSS preprocessors will disagree with most or all of the above. I already know that so no need to tell me :-).
However, me not using Sass or other CSS preprocessors like cssnext does not mean I don’t use CSS processors. The difference, as I see it, is whether or not your CSS requires compilation before browsers can understand it, which I really want to avoid.
I use PostCSS (with third party plugins and ones I’ve written myself) and CSScomb as helpers for things like:
- sorting declarations and fixing coding style issues with CSScomb
- automatically inserting vendor prefixes wherever they are necessary (or removing them wherever they’re not)
- inserting fallbacks for custom properties
- linting CSS
I set up both CSScomb and PostCSS to work on my source CSS, which means I always see the results. No black boxes. I can save my file and reload instantly without having to wait for compilation (since the changes are mostly cosmetic and vendor prefixes/fallbacks only need to be inserted once). But the tools save me some typing and fix most coding style inconsistencies for me. That’s my kind of CSS processing.
lun. 04 avril 2016 07:27:33 CEST -
-
link
- http://www.456bereastreet.com/archive/201603/why_i_dont_use_css_preprocessors/
css
Je copie l'article ici, pour mémoire :
Whenever I mention that I don’t use CSS preprocessors I tend to get strange looks from people who cannot imagine writing CSS without Sass. And so I have to defend my choice and explain why, over and over. Some people will understand, most won’t. Or they don’t want to. But here’s an attempt to explain my reasoning.
Back when CSS preprocessors first came into fashion I did try using them. And then every couple of years, due to external pressure and nagging, I have taken new looks and given them new chances. But to me they’ve always felt like solutions in need of a problem to solve. That is, I don’t really find the “problems” with CSS that preprocessors are intended to solve, problems. The scale of the site I’m building does not matter, be it a tiny site with just a few static pages or a humongous corporate intranet. I simply have never felt the need for mixins, nesting or extends.
A list of reasons then:
- I don’t feel the “problems” CSS preprocessors intend to solve are serious enough to warrant the cost, i.e. to me the solution is worse than the problem.
- I want absolute control of my CSS, which means I want to work hands on with it, and see exactly what will be sent to the browser (well, before it’s minified and gzipped, of course). If that means seeing the same declarations repeated in several rules, or having to see what vendor prefixes look like, so be it. To me, WET CSS is much more understandable and maintainable than DRY black box pseudo-CSS.
- I don’t want to learn and depend on a non-standard syntax to wrap my CSS in, making it require compilation before browsers can understand it. Neither do I want my colleagues to have to.
- I want my source CSS to be deployable at all times, albeit in un-minified, un-concatenated form. If my build process fails, for whatever reason (like an unpublished npm module), I can deploy the source CSS as an emergency solution. Performance may perhaps take a hit, but a slightly slower site is likely better than a site with broken or no CSS until the build process can be fixed.
- I don’t want to have to wait for compilation before seeing the results of my CSS changes. Processing time may be anything from negligible to frustrating, obviously, but if it takes longer than the time it takes for me to switch from my code editor to my browser and reload the page (≈1s) it’s too slow.
I’m fully aware that many people who use CSS preprocessors will disagree with most or all of the above. I already know that so no need to tell me :-).
However, me not using Sass or other CSS preprocessors like cssnext does not mean I don’t use CSS processors. The difference, as I see it, is whether or not your CSS requires compilation before browsers can understand it, which I really want to avoid.
I use PostCSS (with third party plugins and ones I’ve written myself) and CSScomb as helpers for things like:
- sorting declarations and fixing coding style issues with CSScomb
- automatically inserting vendor prefixes wherever they are necessary (or removing them wherever they’re not)
- inserting fallbacks for custom properties
- linting CSS
I set up both CSScomb and PostCSS to work on my source CSS, which means I always see the results. No black boxes. I can save my file and reload instantly without having to wait for compilation (since the changes are mostly cosmetic and vendor prefixes/fallbacks only need to be inserted once). But the tools save me some typing and fix most coding style inconsistencies for me. That’s my kind of CSS processing.
lun. 04 avril 2016 07:27:33 CEST -
-
link
- http://www.456bereastreet.com/archive/201603/why_i_dont_use_css_preprocessors/
css
Default passwords list - Select manufacturer
 Les mots de passe par défaut pour divers équipements informatiques (par exemple, routeurs), pour différents constructeurs.
Les mots de passe par défaut pour divers équipements informatiques (par exemple, routeurs), pour différents constructeurs.
D'où l'intérêt de TOUJOURS changer les mots de passe par défaut, même pour des interfaces web accédées uniquement localement : certains scripts JS malicieux essayent d'accéder aux interfaces web des routeurs sur le réseau local et essayent les mots de passe par défaut.
dim. 03 avril 2016 17:02:53 CEST -
-
link
- https://default-password.info/
sécurité
D'où l'intérêt de TOUJOURS changer les mots de passe par défaut, même pour des interfaces web accédées uniquement localement : certains scripts JS malicieux essayent d'accéder aux interfaces web des routeurs sur le réseau local et essayent les mots de passe par défaut.
dim. 03 avril 2016 17:02:53 CEST -
-
link
- https://default-password.info/
sécurité
Responsive pixel art showcase
 Un prototype de pixel-art responsive. C'est assez bluffant : ce n'est pas juste une image qui se redimensionne mais un ensemble de patterns qui peuvent se répéter (voire une image qui mute complètement en fonction de la taille et du ratio).
Un prototype de pixel-art responsive. C'est assez bluffant : ce n'est pas juste une image qui se redimensionne mais un ensemble de patterns qui peuvent se répéter (voire une image qui mute complètement en fonction de la taille et du ratio).
dim. 03 avril 2016 12:48:25 CEST -
-
link
- http://essenmitsosse.de/pixel/?showcase=true&slide=2
web
dim. 03 avril 2016 12:48:25 CEST -
-
link
- http://essenmitsosse.de/pixel/?showcase=true&slide=2
web
sorttable: Make all your tables sortable
sorttable, une petite librairie js pour ajouter des fonctions de tri à un tableau.
dim. 03 avril 2016 10:59:58 CEST -
-
link
- http://www.kryogenix.org/code/browser/sorttable/
javascript
dim. 03 avril 2016 10:59:58 CEST -
-
link
- http://www.kryogenix.org/code/browser/sorttable/
javascript
Le phonetic, un autre soundex francais (algorithme phonetique)
 Un algorithme phonétique (famille d'algorithmes conçus pour indexer les mots selon leur prononciation) pour la langue française. Implémentation en PHP, C++ et Java.
Un algorithme phonétique (famille d'algorithmes conçus pour indexer les mots selon leur prononciation) pour la langue française. Implémentation en PHP, C++ et Java.
dim. 03 avril 2016 10:56:20 CEST -
-
link
- http://www.roudoudou.com/php/phonetic.php
soundex
dim. 03 avril 2016 10:56:20 CEST -
-
link
- http://www.roudoudou.com/php/phonetic.php
soundex
What will happen if you...
 Excellente présentation sur les subtilités du C.
Excellente présentation sur les subtilités du C.
C'est aussi un parfait exemple de pourquoi un standard devrait toujours chercher à minimiser les ambiguïtés (comportement indéfinis ou non spécifiés), au lieu de laisser les implémentations se débrouiller. Ou, à tout le moins, proposer une implémentation de référence.
dim. 03 avril 2016 10:43:11 CEST -
-
link
- http://fr.slideshare.net/olvemaudal/deep-c/35-What_will_happen_if_you
C/C++
C'est aussi un parfait exemple de pourquoi un standard devrait toujours chercher à minimiser les ambiguïtés (comportement indéfinis ou non spécifiés), au lieu de laisser les implémentations se débrouiller. Ou, à tout le moins, proposer une implémentation de référence.
dim. 03 avril 2016 10:43:11 CEST -
-
link
- http://fr.slideshare.net/olvemaudal/deep-c/35-What_will_happen_if_you
C/C++
Maths and Science blog- matthen
 Des animations de curiosités mathématiques.
Des animations de curiosités mathématiques.
dim. 03 avril 2016 10:25:00 CEST -
-
link
- http://blog.matthen.com/
mathématiques animation
dim. 03 avril 2016 10:25:00 CEST -
-
link
- http://blog.matthen.com/
mathématiques animation
Java 8 Stream Tutorial - Benjamin Winterberg
 Un gros tutoriel par l'exemple pour l'API Stream de Java 8. Dans cette API, un stream (flux) est une suite d'éléments sur laquelle des opérations successives vont être appliquées (map, reduce, filtre, tri, agrégation, etc.). À noter que les traitements sur le flux peuvent être parallélisées très facilement.
Un gros tutoriel par l'exemple pour l'API Stream de Java 8. Dans cette API, un stream (flux) est une suite d'éléments sur laquelle des opérations successives vont être appliquées (map, reduce, filtre, tri, agrégation, etc.). À noter que les traitements sur le flux peuvent être parallélisées très facilement.
Le code est particulièrement élégant, du fait de l'approche fonctionnelle de l'API (https://fr.wikipedia.org/wiki/Programmation_fonctionnelle). Cela rappelle, par certains côtés, l'API LINQ de C#.
J'apprécie beaucoup que Java se dote de plus en plus de sucre syntaxique : les lambdas à la place des classes anonymes, les try with resources à la place des try/finally, les foreach à la place des itérateurs, les imports statiques, etc.
Au fil des évolutions, la critique comme quoi Java serait "trop objet", déjà plutôt idiote à l'origine*, devient parfaitement caduque. En effet Java peut être vu comme un langage multiparadigme :
- impératif, si l'on utilise des méthodes et des imports statiques
- objet, évidemment
- fonctionnel (à l'origine avec les classes anonymes et du bidouillage), grâce aux lambdas
Bien sûr, avec les librairies appropriées, d'autres approches sont possibles : programmation orientée aspects, programmation réactive, etc.
* Plutôt idiote car, indépendamment de tout langage, un paradigme de programmation est une manière d'écrire et de structurer des programmes. Un langage exploite les philosophies d'un ou de plusieurs paradigmes pour fournir des constructions syntaxiques qui simplifient l'écriture et la lecture du code pour un programmeur ayant décidé de penser conformément à ces philosophies. Rien n'empêche d'exploiter un langage et d'y écrire des programmes en se conformant à une philosophie différente. Le C est un exemple flagrant : impératif par nature, il est tellement permissif, que l'on peut y penser en objet, en fonctionnel, en réactif, etc.
mer. 24 févr. 2016 10:41:18 CET -
-
link
- http://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/
java stream fonctionnel
Le code est particulièrement élégant, du fait de l'approche fonctionnelle de l'API (https://fr.wikipedia.org/wiki/Programmation_fonctionnelle). Cela rappelle, par certains côtés, l'API LINQ de C#.
J'apprécie beaucoup que Java se dote de plus en plus de sucre syntaxique : les lambdas à la place des classes anonymes, les try with resources à la place des try/finally, les foreach à la place des itérateurs, les imports statiques, etc.
Au fil des évolutions, la critique comme quoi Java serait "trop objet", déjà plutôt idiote à l'origine*, devient parfaitement caduque. En effet Java peut être vu comme un langage multiparadigme :
- impératif, si l'on utilise des méthodes et des imports statiques
- objet, évidemment
- fonctionnel (à l'origine avec les classes anonymes et du bidouillage), grâce aux lambdas
Bien sûr, avec les librairies appropriées, d'autres approches sont possibles : programmation orientée aspects, programmation réactive, etc.
* Plutôt idiote car, indépendamment de tout langage, un paradigme de programmation est une manière d'écrire et de structurer des programmes. Un langage exploite les philosophies d'un ou de plusieurs paradigmes pour fournir des constructions syntaxiques qui simplifient l'écriture et la lecture du code pour un programmeur ayant décidé de penser conformément à ces philosophies. Rien n'empêche d'exploiter un langage et d'y écrire des programmes en se conformant à une philosophie différente. Le C est un exemple flagrant : impératif par nature, il est tellement permissif, que l'on peut y penser en objet, en fonctionnel, en réactif, etc.
mer. 24 févr. 2016 10:41:18 CET -
-
link
- http://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/
java stream fonctionnel
Why you shouldn't trust successful people's advice
 En résumé : soyez très critique vis-à-vis des avis de ceux qui réussissent. De par le biais du survivant (considérer uniquement le cas des survivants au détriment des non-survivants), nous avons tendance à surestimer l'expérience de ceux qui réussissent par rapport à l'expérience des personnes qui n'ont pas réussi.
En résumé : soyez très critique vis-à-vis des avis de ceux qui réussissent. De par le biais du survivant (considérer uniquement le cas des survivants au détriment des non-survivants), nous avons tendance à surestimer l'expérience de ceux qui réussissent par rapport à l'expérience des personnes qui n'ont pas réussi.
Concrètement, personne ne sait réellement quel est la méthode pour réussir, tout simplement parce que le facteur chance est énorme (avantages de départ, opportunités, bon endroit/bon moment, etc.). C'est d'ailleurs pour cela que la réussite à tendance à augmenter avec le nombre d'essais.
dim. 21 févr. 2016 12:28:00 CET -
-
link
- https://www.youtube.com/watch?v=1k7jeQQdqPA
bêtise réussite
Concrètement, personne ne sait réellement quel est la méthode pour réussir, tout simplement parce que le facteur chance est énorme (avantages de départ, opportunités, bon endroit/bon moment, etc.). C'est d'ailleurs pour cela que la réussite à tendance à augmenter avec le nombre d'essais.
dim. 21 févr. 2016 12:28:00 CET -
-
link
- https://www.youtube.com/watch?v=1k7jeQQdqPA
bêtise réussite
Réinitialiser les vbox guest additions sous linux mint
 De nombreuses distributions linux embarquent désormais les vbox guest additions directement dans leurs dépôts de paquets. Dans ce cas, il est déconseillé d'installer soi-même les vbox guest additions (de l'aveu même du script d'installation).
De nombreuses distributions linux embarquent désormais les vbox guest additions directement dans leurs dépôts de paquets. Dans ce cas, il est déconseillé d'installer soi-même les vbox guest additions (de l'aveu même du script d'installation).
Cependant, comme je suis curieux, j'ai tenté l'installation quand même et planté complètement mon système (Linux Mint) : copier-coller hôte-invité impossible, résolution figée, accélération 3D désactivée, etc.
Voilà la méthode que j'ai utilisé pour réparer tout ça (privilèges root requis).
1. On nettoie et on réinstalle
> apt-get autoremove --purge virtualbox-guest-dkms virtualbox-guest-utils virtualbox-guest-x11
> apt-get install virtualbox-guest-dkms virtualbox-guest-utils virtualbox-guest-x11
2. On force la reconfiguration
> dpkg-reconfigure virtualbox-guest-dkms
3. On redémarre ou on recharge simplement les modules concernés
> modprobe -a vboxguest vboxsf vboxvideo
jeu. 04 févr. 2016 08:22:43 CET -
-
link
virtualbox machine-virtuelle
Cependant, comme je suis curieux, j'ai tenté l'installation quand même et planté complètement mon système (Linux Mint) : copier-coller hôte-invité impossible, résolution figée, accélération 3D désactivée, etc.
Voilà la méthode que j'ai utilisé pour réparer tout ça (privilèges root requis).
1. On nettoie et on réinstalle
> apt-get autoremove --purge virtualbox-guest-dkms virtualbox-guest-utils virtualbox-guest-x11
> apt-get install virtualbox-guest-dkms virtualbox-guest-utils virtualbox-guest-x11
2. On force la reconfiguration
> dpkg-reconfigure virtualbox-guest-dkms
3. On redémarre ou on recharge simplement les modules concernés
> modprobe -a vboxguest vboxsf vboxvideo
jeu. 04 févr. 2016 08:22:43 CET -
-
link
virtualbox machine-virtuelle
Melody's Guide to Programming Language
Avec l'âge et l'expérience, je ne supporte vraiment plus les "frameworks" Java. Récemment j'ai du refaire du Spring et... franchement.
jeu. 24 déc. 2015 11:22:22 CET -
-
link
- http://www.sandraandwoo.com/2015/12/24/0747-melodys-guide-to-programming-languages/
humour
jeu. 24 déc. 2015 11:22:22 CET -
-
link
- http://www.sandraandwoo.com/2015/12/24/0747-melodys-guide-to-programming-languages/
humour
Réseau interne sous VirtualBox
 VirtualBox permet de créer différent types de réseaux pour vos VM :
VirtualBox permet de créer différent types de réseaux pour vos VM :
- NAT : la VM communique avec l'extérieur grâce à un mécanisme de NAT (network address translation). Depuis l'extérieur, les requêtes de la VM ont l'air d'être envoyées par la machine hôte.
- Bridged : la VM est considérée comme une machine à part entière sur le LAN, elle pourra obtenir son IP directement à partir d'un serveur DHCP accessible depuis le LAN.
- Internal Network : la VM est isolée (ne peut pas communiquer avec l'hôte), mais peut communiquer avec les autres VM de l'hôte.
Le mode Internal Network est celui qui m'intèresse ici. Pour le mettre en place (VirtualBox 5.0.10), il faut :
0. Arrêter vos VMs ;)
1. Pour chaque VM, passer l'interface réseau virtuelle en mode Internal Network et, éventuellement, donner un nom de réseau (par défaut: intnet).
2. Soit configurer les VM avec une IP statique (dépend de l'OS virtuel, bien sur), soit demander à VirtualBox de mettre en place un DHCP pour le réseau interne. La mise en place d'un DHCP ne peut se faire qu'avec une commande :
> VBoxManage dhcpserver add --netname <nom du réseau> --ip <ip du DHCP> --netmask <masque> --lowerip <borne inférieure de la plage d'IP> --upperip <borne supérieure de la plage d'IP> --enable
Par exemple :
> VBoxManage dhcpserver add --netname intnet --ip 10.10.10.254 --netmask 255.255.255.0 --lowerip 10.10.10.1 --upperip 10.10.10.100 --enable
Note : il se peut que la VM n'arrive pas à récupérer une IP depuis le DHCP de VirtualBox. Ce problème se résoud en changeant l'adresse MAC de l'interface réseau virtuelle, forçant l'OS virtuel à râfraichir ses configurations réseaux.
ven. 27 nov. 2015 08:50:46 CET -
-
link
machine-virtuelle virtualbox
- NAT : la VM communique avec l'extérieur grâce à un mécanisme de NAT (network address translation). Depuis l'extérieur, les requêtes de la VM ont l'air d'être envoyées par la machine hôte.
- Bridged : la VM est considérée comme une machine à part entière sur le LAN, elle pourra obtenir son IP directement à partir d'un serveur DHCP accessible depuis le LAN.
- Internal Network : la VM est isolée (ne peut pas communiquer avec l'hôte), mais peut communiquer avec les autres VM de l'hôte.
Le mode Internal Network est celui qui m'intèresse ici. Pour le mettre en place (VirtualBox 5.0.10), il faut :
0. Arrêter vos VMs ;)
1. Pour chaque VM, passer l'interface réseau virtuelle en mode Internal Network et, éventuellement, donner un nom de réseau (par défaut: intnet).
2. Soit configurer les VM avec une IP statique (dépend de l'OS virtuel, bien sur), soit demander à VirtualBox de mettre en place un DHCP pour le réseau interne. La mise en place d'un DHCP ne peut se faire qu'avec une commande :
> VBoxManage dhcpserver add --netname <nom du réseau> --ip <ip du DHCP> --netmask <masque> --lowerip <borne inférieure de la plage d'IP> --upperip <borne supérieure de la plage d'IP> --enable
Par exemple :
> VBoxManage dhcpserver add --netname intnet --ip 10.10.10.254 --netmask 255.255.255.0 --lowerip 10.10.10.1 --upperip 10.10.10.100 --enable
Note : il se peut que la VM n'arrive pas à récupérer une IP depuis le DHCP de VirtualBox. Ce problème se résoud en changeant l'adresse MAC de l'interface réseau virtuelle, forçant l'OS virtuel à râfraichir ses configurations réseaux.
ven. 27 nov. 2015 08:50:46 CET -
-
link
machine-virtuelle virtualbox
How "Exit Traps" Can Make Your Bash Scripts Way More Robust And Reliable
 Une petite technique pour améliorer la robustesse de vos scripts. "trap" permet de déclencher l'exécution d'une procédure lorsque le script quitte. Cela permet d'assurer que, même en cas d'erreur, le script termine dans un état prédictible (ressources désallouées, services relancés, etc.).
Une petite technique pour améliorer la robustesse de vos scripts. "trap" permet de déclencher l'exécution d'une procédure lorsque le script quitte. Cela permet d'assurer que, même en cas d'erreur, le script termine dans un état prédictible (ressources désallouées, services relancés, etc.).
#!/bin/bash
function finish {
# Your cleanup code here
}
trap finish EXIT
A noter que "trap" peut capturer d'autres signaux :
http://tldp.org/LDP/Bash-Beginners-Guide/html/sect_12_02.html
ven. 27 nov. 2015 08:35:36 CET -
-
link
- http://redsymbol.net/articles/bash-exit-traps/
bash
#!/bin/bash
function finish {
# Your cleanup code here
}
trap finish EXIT
A noter que "trap" peut capturer d'autres signaux :
http://tldp.org/LDP/Bash-Beginners-Guide/html/sect_12_02.html
ven. 27 nov. 2015 08:35:36 CET -
-
link
- http://redsymbol.net/articles/bash-exit-traps/
bash
Authentication Concept Map
 Une petite carte des concepts et du vocabulaire relatifs à l'authentification. Je me demandais justement d'où java.security sortait ces termes Subject, Principal, etc.
Une petite carte des concepts et du vocabulaire relatifs à l'authentification. Je me demandais justement d'où java.security sortait ces termes Subject, Principal, etc.
Source de l'image : http://telicthoughts.blogspot.fr/2011/02/authentication-concept-map.html
Voir aussi http://stackoverflow.com/a/5025140, qui explique que tout n'est malheureusement pas aussi bien défini :
"As noted in the comments, even the authoritative sources do not agree on these terms. I searched NIST, SANS, IEEE, MITRE and several "quasi-authoritative" sources such as security exam guides while preparing this response. No single source that I found which was at least quasi-authoritative covered all three terms and all differed significantly in their usage."
mar. 10 nov. 2015 10:09:04 CET -
-
link
- http://1.bp.blogspot.com/-a4Qxtcg0rec/TV01FzBKTYI/AAAAAAAAADs/di4kdadpPS4/s1600/authentication.jpg
sécurité authentification
{kind=link}
Source de l'image : http://telicthoughts.blogspot.fr/2011/02/authentication-concept-map.html
Voir aussi http://stackoverflow.com/a/5025140, qui explique que tout n'est malheureusement pas aussi bien défini :
"As noted in the comments, even the authoritative sources do not agree on these terms. I searched NIST, SANS, IEEE, MITRE and several "quasi-authoritative" sources such as security exam guides while preparing this response. No single source that I found which was at least quasi-authoritative covered all three terms and all differed significantly in their usage."
mar. 10 nov. 2015 10:09:04 CET -
-
link
- http://1.bp.blogspot.com/-a4Qxtcg0rec/TV01FzBKTYI/AAAAAAAAADs/di4kdadpPS4/s1600/authentication.jpg
sécurité authentification
Comparing floating point numbers
 Un problème très classique, mais toujours intéressant. Si vous faîtes du calcul scientifique, de manière générale, n'utilisez pas les flottants IEEE 754 ; préférez-y des librairies de calcul arithmétique à précision arbitraire.
Un problème très classique, mais toujours intéressant. Si vous faîtes du calcul scientifique, de manière générale, n'utilisez pas les flottants IEEE 754 ; préférez-y des librairies de calcul arithmétique à précision arbitraire.
En Java, vous pouvez utiliser la classe BigDecimal.
En C/C++, il y a GMP : https://gmplib.org
Pour les autres langages, voir https://en.wikipedia.org/wiki/List_of_arbitrary-precision_arithmetic_software
mar. 10 nov. 2015 09:58:36 CET -
-
link
- http://www.cygnus-software.com/papers/comparingfloats/comparingfloats.htm
flottant arithmétique
En Java, vous pouvez utiliser la classe BigDecimal.
En C/C++, il y a GMP : https://gmplib.org
Pour les autres langages, voir https://en.wikipedia.org/wiki/List_of_arbitrary-precision_arithmetic_software
mar. 10 nov. 2015 09:58:36 CET -
-
link
- http://www.cygnus-software.com/papers/comparingfloats/comparingfloats.htm
flottant arithmétique
L'opérateur conditionnel ternaire
Je n'aime pas beaucoup l'opérateur conditionnel ternaire (a ? b : c). Je déconseille toujours à mes étudiants de l'utiliser, car j'estime qu'il nuit à la lisibilité du code.
Eh bien, je vais pouvoir désormais illustrer mon conseil avec un exemple réel, qui vient du code de Jetty 9 :
super(new URL[]{},parent!=null?parent
:(Thread.currentThread().getContextClassLoader()!=null?Thread.currentThread().getContextClassLoader()
:(WebAppClassLoader.class.getClassLoader()!=null?WebAppClassLoader.class.getClassLoader()
:ClassLoader.getSystemClassLoader())));
mar. 10 nov. 2015 09:49:07 CET -
-
link
programmation
Eh bien, je vais pouvoir désormais illustrer mon conseil avec un exemple réel, qui vient du code de Jetty 9 :
super(new URL[]{},parent!=null?parent
:(Thread.currentThread().getContextClassLoader()!=null?Thread.currentThread().getContextClassLoader()
:(WebAppClassLoader.class.getClassLoader()!=null?WebAppClassLoader.class.getClassLoader()
:ClassLoader.getSystemClassLoader())));
mar. 10 nov. 2015 09:49:07 CET -
-
link
programmation
Git
 Ah ah, c'est tellement ça :p
Ah ah, c'est tellement ça :p
dim. 08 nov. 2015 09:09:17 CET -
-
link
- http://imgs.xkcd.com/comics/git.png
git
{kind=link} dim. 08 nov. 2015 09:09:17 CET -
-
link
- http://imgs.xkcd.com/comics/git.png
git
dim. 08 nov. 2015 09:09:17 CET -
-
link
- http://imgs.xkcd.com/comics/git.png
git
Comment déterminer à quelle heure a été prise une photo ?
 Une méthode pour déterminer approximativement à quelle heure a été prise une photo, en se basant sur les ombres portées.
Une méthode pour déterminer approximativement à quelle heure a été prise une photo, en se basant sur les ombres portées.
sam. 07 nov. 2015 17:40:05 CET -
-
link
- http://joelmatriche.com/2015/10/28/determiner-plus-ou-moins-lheure-a-laquelle-une-photo-a-ete-prise/
datation
sam. 07 nov. 2015 17:40:05 CET -
-
link
- http://joelmatriche.com/2015/10/28/determiner-plus-ou-moins-lheure-a-laquelle-une-photo-a-ete-prise/
datation
Récompenser pour motiver. Une bonne idée ?
 Pourquoi le management par la récompense n'est pas forcément une bonne idée.
Pourquoi le management par la récompense n'est pas forcément une bonne idée.
"Récompenser un enfant parce qu’il s’est “bien” comporté ne lui fait pas comprendre pourquoi il est important d’agir de la sorte. Non. Cela lui fait comprendre qu’en agissant ainsi, il est sûr de recevoir une récompense."
"Peut-on mêler une récompense extérieure au plaisir qu’il y a à effectuer une action pour elle-même ? Non. Dès le moment où il y a une récompense, nous serons avant tout motivés par la récompense."
sam. 07 nov. 2015 17:28:50 CET -
-
link
- https://medium.com/france/r%C3%A9compenser-pour-motiver-une-bonne-id%C3%A9e-lisez-cet-article-et-gagnez-100-euros-c1f032de66da#.b817btstg
motivation
"Récompenser un enfant parce qu’il s’est “bien” comporté ne lui fait pas comprendre pourquoi il est important d’agir de la sorte. Non. Cela lui fait comprendre qu’en agissant ainsi, il est sûr de recevoir une récompense."
"Peut-on mêler une récompense extérieure au plaisir qu’il y a à effectuer une action pour elle-même ? Non. Dès le moment où il y a une récompense, nous serons avant tout motivés par la récompense."
sam. 07 nov. 2015 17:28:50 CET -
-
link
- https://medium.com/france/r%C3%A9compenser-pour-motiver-une-bonne-id%C3%A9e-lisez-cet-article-et-gagnez-100-euros-c1f032de66da#.b817btstg
motivation
TCP TIME-WAIT & les serveurs Linux à fort trafic | Vincent Bernat
 Intéressant article sur les options 'net.ipv4.tcp_tw_recycle' et 'net.ipv4.tcp_tw_reuse' qui spécifient ce que la pile TCP/IP de Linux est autorisée à faire avec les connexions dans l'état TIME-WAIT ; un état d'attente destiné (i) à empêcher qu'une nouvelle connexion n'accepte de données qui arriveraient en retard et (ii) à assurer que l'hôte distant a fermé la connexion.
Intéressant article sur les options 'net.ipv4.tcp_tw_recycle' et 'net.ipv4.tcp_tw_reuse' qui spécifient ce que la pile TCP/IP de Linux est autorisée à faire avec les connexions dans l'état TIME-WAIT ; un état d'attente destiné (i) à empêcher qu'une nouvelle connexion n'accepte de données qui arriveraient en retard et (ii) à assurer que l'hôte distant a fermé la connexion.
Les explications sont très claires, par exemple le diagramme d'état de TCP : http://d1g3mdmxf8zbo9.cloudfront.net/images/tcp/tcp-state-diagram.png
En résumé, je recopie la conclusion de l'article :
Côté serveur, ne pas activer net.ipv4.tcp_tw_recycle à moins d’être sûr de ne jamais avoir à interagir avec des machines se partageant la même IP. Activer net.ipv4.tcp_tw_reuse est sans effet sur les connexions entrantes.
Côté client, activer net.ipv4.tcp_tw_reuse est une solution quasiment fiable. Activer en plus net.ipv4.tcp_tw_recycle est alors quasi-inutile.
sam. 07 nov. 2015 16:43:05 CET -
-
link
- http://vincent.bernat.im/fr/blog/2014-tcp-time-wait-state-linux.html
tcp/ip
Les explications sont très claires, par exemple le diagramme d'état de TCP : http://d1g3mdmxf8zbo9.cloudfront.net/images/tcp/tcp-state-diagram.png
{kind=link}
En résumé, je recopie la conclusion de l'article :
Côté serveur, ne pas activer net.ipv4.tcp_tw_recycle à moins d’être sûr de ne jamais avoir à interagir avec des machines se partageant la même IP. Activer net.ipv4.tcp_tw_reuse est sans effet sur les connexions entrantes.
Côté client, activer net.ipv4.tcp_tw_reuse est une solution quasiment fiable. Activer en plus net.ipv4.tcp_tw_recycle est alors quasi-inutile.
sam. 07 nov. 2015 16:43:05 CET -
-
link
- http://vincent.bernat.im/fr/blog/2014-tcp-time-wait-state-linux.html
tcp/ip
Blog Stéphane Bortzmeyer: Le principe de robustesse, une bonne ou une mauvaise idée ?
 Le principe de Postel est très connu dans le monde des protocoles réseaux : "Soyez rigoureux dans ce que produisez, soyez compréhensif avec ce qui vient des autres".
Le principe de Postel est très connu dans le monde des protocoles réseaux : "Soyez rigoureux dans ce que produisez, soyez compréhensif avec ce qui vient des autres".
L'objectif de ce principe consiste à maximiser le respect des standards, tout en introduisant une certaine robustesse envers les erreurs mineures et prévisibles qui pourraient exister dans les différentes implémentations.
Malheureusement, ce principe est mal compris, ou plutôt poussé à son extrême : des mécanismes complexes sont mis en œuvre pour résister à des erreurs hypothétiques, ce qui amène les développeurs à se montrer moins rigoureux et à faire émerger ces erreurs. Et une fois que ces erreurs deviennent une habitude, toute nouvelle implémentation se doit de gérer ces erreurs là.
En ce qui me concerne, j'applique le principe de Postel uniquement pour les erreurs évidentes (espaces en trop, par exemple) ou pour les erreurs faciles à détecter/corriger (valeurs oubliées). Hors de question de mettre en place des heuristiques complexes telles que celles implémentées par les navigateurs pour afficher du contenu à tout prix.
Avec le temps, je me rends compte aussi que le principe de Postel tend à être incompatible avec le principe "fail fast", qui consiste à dire qu'une erreur devrait survenir le plus tôt possible (et donc que, justement, un programme ne devrait pas chercher à corriger ou à ignorer les erreurs, mais plutôt échouer rapidement et de manière visible. En effet, l'existence d'une erreur est justement le signe que quelque chose ne va pas, et qu'il y a probablement des soucis en amont. Faire remonter ces erreurs permet de mettre en évidence ces soucis et de les corriger une bonne fois pour toute.
mar. 27 oct. 2015 19:51:03 CET -
-
link
- http://www.bortzmeyer.org/principe-robustesse.html
génie-logiciel postel programmation
L'objectif de ce principe consiste à maximiser le respect des standards, tout en introduisant une certaine robustesse envers les erreurs mineures et prévisibles qui pourraient exister dans les différentes implémentations.
Malheureusement, ce principe est mal compris, ou plutôt poussé à son extrême : des mécanismes complexes sont mis en œuvre pour résister à des erreurs hypothétiques, ce qui amène les développeurs à se montrer moins rigoureux et à faire émerger ces erreurs. Et une fois que ces erreurs deviennent une habitude, toute nouvelle implémentation se doit de gérer ces erreurs là.
En ce qui me concerne, j'applique le principe de Postel uniquement pour les erreurs évidentes (espaces en trop, par exemple) ou pour les erreurs faciles à détecter/corriger (valeurs oubliées). Hors de question de mettre en place des heuristiques complexes telles que celles implémentées par les navigateurs pour afficher du contenu à tout prix.
Avec le temps, je me rends compte aussi que le principe de Postel tend à être incompatible avec le principe "fail fast", qui consiste à dire qu'une erreur devrait survenir le plus tôt possible (et donc que, justement, un programme ne devrait pas chercher à corriger ou à ignorer les erreurs, mais plutôt échouer rapidement et de manière visible. En effet, l'existence d'une erreur est justement le signe que quelque chose ne va pas, et qu'il y a probablement des soucis en amont. Faire remonter ces erreurs permet de mettre en évidence ces soucis et de les corriger une bonne fois pour toute.
mar. 27 oct. 2015 19:51:03 CET -
-
link
- http://www.bortzmeyer.org/principe-robustesse.html
génie-logiciel postel programmation
Iterative Vs Incremental
 "IterativeDevelopment means:
"IterativeDevelopment means:
I write loads of stuff that's a complete mess
I go through it throwing out the irrelevant drivel, expanding on the important bits, and sorting out the structure
I go through it again now I can start to see the shape of it, sorting it some more
I go through it yet again, etc, until it's GoodEnough
IncrementalDevelopment means:
I write part one
I write part two
I write part three, etc, until the book is finished
[...]
So in practice, at least in XP practice, your development is both incremental and iterative.
-- StephenHutchinson
The danger is when people confuse the two. I saw a 200 person project iterating on their requirements (allowing arbitrary amount of change) when they should have been incrementing through their requirements, and incrementing & iterating (as you describe) through their design. They were, of course, not making any progress. Also saw a 100 person project claiming they were iterating through their entire novel, when in fact they were doing neither - they were stuck in the mud. They needed to get at least some part working first so they could tell they were moving - once again, needed incrementing as a base.
-- AlistairCockburn"
Image de la miniature : http://www.applitude.se/images/inc_vs_ite.png
lun. 19 oct. 2015 07:17:42 CEST -
-
link
- http://c2.com/cgi/wiki?IterativeVsIncremental
programmation génie-logiciel
I write loads of stuff that's a complete mess
I go through it throwing out the irrelevant drivel, expanding on the important bits, and sorting out the structure
I go through it again now I can start to see the shape of it, sorting it some more
I go through it yet again, etc, until it's GoodEnough
IncrementalDevelopment means:
I write part one
I write part two
I write part three, etc, until the book is finished
[...]
So in practice, at least in XP practice, your development is both incremental and iterative.
-- StephenHutchinson
The danger is when people confuse the two. I saw a 200 person project iterating on their requirements (allowing arbitrary amount of change) when they should have been incrementing through their requirements, and incrementing & iterating (as you describe) through their design. They were, of course, not making any progress. Also saw a 100 person project claiming they were iterating through their entire novel, when in fact they were doing neither - they were stuck in the mud. They needed to get at least some part working first so they could tell they were moving - once again, needed incrementing as a base.
-- AlistairCockburn"
Image de la miniature : http://www.applitude.se/images/inc_vs_ite.png
{kind=link} lun. 19 oct. 2015 07:17:42 CEST -
-
link
- http://c2.com/cgi/wiki?IterativeVsIncremental
programmation génie-logiciel
lun. 19 oct. 2015 07:17:42 CEST -
-
link
- http://c2.com/cgi/wiki?IterativeVsIncremental
programmation génie-logiciel
HTML5 flowchart
 Choisir rapidement quelle balise utiliser parmi nav, article, figure, aside, section et, en dernier recours, div.
Choisir rapidement quelle balise utiliser parmi nav, article, figure, aside, section et, en dernier recours, div.
lun. 19 oct. 2015 07:12:25 CEST -
-
link
- http://html5doctor.com/downloads/h5d-sectioning-flowchart.png
html5
{kind=link} lun. 19 oct. 2015 07:12:25 CEST -
-
link
- http://html5doctor.com/downloads/h5d-sectioning-flowchart.png
html5
lun. 19 oct. 2015 07:12:25 CEST -
-
link
- http://html5doctor.com/downloads/h5d-sectioning-flowchart.png
html5
Science article : a guide
 SMBC n'est pas toujours sérieux, mais c'est une méthode plutôt efficace pour classer rapidement les articles scientifiques : http://www.smbc-comics.com/index.php?id=3880
SMBC n'est pas toujours sérieux, mais c'est une méthode plutôt efficace pour classer rapidement les articles scientifiques : http://www.smbc-comics.com/index.php?id=3880
dim. 18 oct. 2015 11:31:10 CEST -
-
link
- http://www.smbc-comics.com/index.php?id=3880
science recherche
dim. 18 oct. 2015 11:31:10 CEST -
-
link
- http://www.smbc-comics.com/index.php?id=3880
science recherche
Tous les chercheurs skient sur les pistes de tennis | binaire
 "Rendre la parole scientifique aux chercheurs.
"Rendre la parole scientifique aux chercheurs.
Ils sont un peu moins médiatiques à écouter, mais ils partagent des grains de science qui augmentera le niveau de culture scientifique de toutes et tous dans notre société."
Voilà qui n'est que trop vrai.
dim. 11 oct. 2015 10:43:50 CEST -
-
link
- http://binaire.blog.lemonde.fr/2015/09/30/tous-les-chercheurs-skient-sur-les-pistes-de-tennis/
science recherche
Ils sont un peu moins médiatiques à écouter, mais ils partagent des grains de science qui augmentera le niveau de culture scientifique de toutes et tous dans notre société."
Voilà qui n'est que trop vrai.
dim. 11 oct. 2015 10:43:50 CEST -
-
link
- http://binaire.blog.lemonde.fr/2015/09/30/tous-les-chercheurs-skient-sur-les-pistes-de-tennis/
science recherche
The website is unknown - How DNS works
 Le fonctionnement du DNS illustré. Tout en vectoriel, c'est très propre.
Le fonctionnement du DNS illustré. Tout en vectoriel, c'est très propre.
lun. 05 oct. 2015 17:11:50 CEST -
-
link
- https://howdns.works/ep1/
dns protocole
lun. 05 oct. 2015 17:11:50 CEST -
-
link
- https://howdns.works/ep1/
dns protocole
Ephemeral Hosting
 C'est intéressant, cette page n'existe que si des personnes la visualisent. Il s'agit en fait d'un annuaire centralisé qui associe des hash à des connexions websocket ouvertes depuis des navigateurs.
C'est intéressant, cette page n'existe que si des personnes la visualisent. Il s'agit en fait d'un annuaire centralisé qui associe des hash à des connexions websocket ouvertes depuis des navigateurs.
Lorsque vous visualisez cette page, le hash "2bbbf21959178ef2f935e90fc60e5b6e368d27514fe305ca7dcecc32c0134838" est recherché dans l'annuaire et le contenu correspondant est téléchargé depuis l'un des navigateurs connecté au serveur (c'est-à-dire depuis l'un des navigateurs qui affiche la page à cet instant).
Une fois le contenu chargé, une connexion websocket depuis votre navigateur est ajoutée à l'annuaire et vous faîtes à votre tour partie du réseau.
Lorsque plus personne ne visualise cette page, elle disparaît purement et simplement. Bon, celle là étant la page principale, j'imagine que son auteur doit y rester connecté en permanence pour qu'elle ne disparaisse pas.
Mais attention, ce n'est pas réellement du pair à pair, d'une part parce que l'annuaire est centralisé mais aussi parce que l'annuaire est un proxy qui maintient des connexions vers tous ceux qui visualisent la page : il n'y a pas d'échange direct entre les navigateurs. Mais cela reste intéressant quand même.
Code source ici : https://github.com/losvedir/ephemeral2
lun. 05 oct. 2015 17:07:35 CEST -
-
link
- http://ephemeralp2p.durazo.us/2bbbf21959178ef2f935e90fc60e5b6e368d27514fe305ca7dcecc32c0134838?
p2p
Lorsque vous visualisez cette page, le hash "2bbbf21959178ef2f935e90fc60e5b6e368d27514fe305ca7dcecc32c0134838" est recherché dans l'annuaire et le contenu correspondant est téléchargé depuis l'un des navigateurs connecté au serveur (c'est-à-dire depuis l'un des navigateurs qui affiche la page à cet instant).
Une fois le contenu chargé, une connexion websocket depuis votre navigateur est ajoutée à l'annuaire et vous faîtes à votre tour partie du réseau.
Lorsque plus personne ne visualise cette page, elle disparaît purement et simplement. Bon, celle là étant la page principale, j'imagine que son auteur doit y rester connecté en permanence pour qu'elle ne disparaisse pas.
Mais attention, ce n'est pas réellement du pair à pair, d'une part parce que l'annuaire est centralisé mais aussi parce que l'annuaire est un proxy qui maintient des connexions vers tous ceux qui visualisent la page : il n'y a pas d'échange direct entre les navigateurs. Mais cela reste intéressant quand même.
Code source ici : https://github.com/losvedir/ephemeral2
lun. 05 oct. 2015 17:07:35 CEST -
-
link
- http://ephemeralp2p.durazo.us/2bbbf21959178ef2f935e90fc60e5b6e368d27514fe305ca7dcecc32c0134838?
p2p
http://www.alanzucconi.com/2015/09/30/colour-sorting/
 Le problème de tri des couleurs est directement défini par la difficulté de trouver une relation d'ordre qui soit visuellement satisfaisante pour un espace colorimétrique.
Le problème de tri des couleurs est directement défini par la difficulté de trouver une relation d'ordre qui soit visuellement satisfaisante pour un espace colorimétrique.
Si l'on prend les nuanciers types arc en ciel, ceux ci sont produits dans un espace HSL en faisant varier la teinte (hue) et en conservant la saturation et la luminance à une valeur fixe (typiquement 1). Essayez sur directement sur http://google.github.io/palette.js
Ici, la relation d'ordre est spécifiée par la valeur de teinte (unidimensionnelle) d'où un bel arc en ciel visuellement uniforme, comme ici : http://www.play-crafts.com/blog/wp-content/uploads/2013/12/hue.jpg
Cependant, si l'on fait varier aléatoirement la teinte, la saturation et la luminance, le bel arc en ciel n'est plus possible car un même vert peut exister en plusieurs niveaux de saturation/luminosité. Avec une simple relation d'ordre lexicographique sur les valeurs de teinte, saturation et luminance, le tri produit ceci http://www.alanzucconi.com/wp-content/uploads/2015/09/sort_hls.png
On observe que l'arc en ciel est là, mais avec des rais de différentes saturation/luminosité qui produisent du bruit dans le résultat.
Si l'on cherche à regrouper les couleurs entre elles, cela peut se faire en divisant l'espace en classes, soit uniformément (découpage en blocs uniformes), soit au moyen d'un algorithme de clustering.
Cela donne un résultat où les couleurs sont effectivement regroupées mais sans arc en ciel global : http://www.alanzucconi.com/wp-content/uploads/2015/09/sort_hsv-lum.png
Il est possible aussi de minimiser la distance entre toutes les couleurs lors de la réduction en dimension 1, ce qui se formalise en problème de voyageur du commerce. Toutefois, si le résultat obtenu est très lisse, il est aussi visuellement aléatoire : http://www.alanzucconi.com/wp-content/uploads/2015/09/sort_nn_hsv.png
dim. 04 oct. 2015 18:01:09 CEST -
-
link
- http://www.alanzucconi.com/2015/09/30/colour-sorting/
colorimétrie
Si l'on prend les nuanciers types arc en ciel, ceux ci sont produits dans un espace HSL en faisant varier la teinte (hue) et en conservant la saturation et la luminance à une valeur fixe (typiquement 1). Essayez sur directement sur http://google.github.io/palette.js
Ici, la relation d'ordre est spécifiée par la valeur de teinte (unidimensionnelle) d'où un bel arc en ciel visuellement uniforme, comme ici : http://www.play-crafts.com/blog/wp-content/uploads/2013/12/hue.jpg
{kind=link}
Cependant, si l'on fait varier aléatoirement la teinte, la saturation et la luminance, le bel arc en ciel n'est plus possible car un même vert peut exister en plusieurs niveaux de saturation/luminosité. Avec une simple relation d'ordre lexicographique sur les valeurs de teinte, saturation et luminance, le tri produit ceci http://www.alanzucconi.com/wp-content/uploads/2015/09/sort_hls.png
{kind=link}
On observe que l'arc en ciel est là, mais avec des rais de différentes saturation/luminosité qui produisent du bruit dans le résultat.
Si l'on cherche à regrouper les couleurs entre elles, cela peut se faire en divisant l'espace en classes, soit uniformément (découpage en blocs uniformes), soit au moyen d'un algorithme de clustering.
Cela donne un résultat où les couleurs sont effectivement regroupées mais sans arc en ciel global : http://www.alanzucconi.com/wp-content/uploads/2015/09/sort_hsv-lum.png
{kind=link}
Il est possible aussi de minimiser la distance entre toutes les couleurs lors de la réduction en dimension 1, ce qui se formalise en problème de voyageur du commerce. Toutefois, si le résultat obtenu est très lisse, il est aussi visuellement aléatoire : http://www.alanzucconi.com/wp-content/uploads/2015/09/sort_nn_hsv.png
{kind=link} dim. 04 oct. 2015 18:01:09 CEST -
-
link
- http://www.alanzucconi.com/2015/09/30/colour-sorting/
colorimétrie
dim. 04 oct. 2015 18:01:09 CEST -
-
link
- http://www.alanzucconi.com/2015/09/30/colour-sorting/
colorimétrie
Gen I Capture Mechanics | The Cave of Dragonflies
 Description très complète et très détaillées des algorithmes de capture dans le jeu Pokémon (génération 1). Bah quoi, c'est intéressant aussi :)
Description très complète et très détaillées des algorithmes de capture dans le jeu Pokémon (génération 1). Bah quoi, c'est intéressant aussi :)
dim. 04 oct. 2015 16:34:14 CEST -
-
link
- http://www.dragonflycave.com/rbycapture.aspx
jeu-vidéo
dim. 04 oct. 2015 16:34:14 CEST -
-
link
- http://www.dragonflycave.com/rbycapture.aspx
jeu-vidéo
The C++14 Standard: What You Need to Know
 Avancée dans C++14.
Avancée dans C++14.
Voir aussi les évolutions depuis C++11 :
http://www.codeproject.com/Articles/570638/Ten-Cplusplus-Features-Every-Cplusplus-Developer
http://blog.smartbear.com/c-plus-plus/the-biggest-changes-in-c11-and-why-you-should-care/
dim. 04 oct. 2015 16:29:36 CEST -
-
link
- http://www.drdobbs.com/cpp/the-c14-standard/240169034
C/C++
Voir aussi les évolutions depuis C++11 :
http://www.codeproject.com/Articles/570638/Ten-Cplusplus-Features-Every-Cplusplus-Developer
http://blog.smartbear.com/c-plus-plus/the-biggest-changes-in-c11-and-why-you-should-care/
dim. 04 oct. 2015 16:29:36 CEST -
-
link
- http://www.drdobbs.com/cpp/the-c14-standard/240169034
C/C++
Reverse Engineering for Beginners
 Un livre gratuit sur le reverse engineering, assez intéressant.
Un livre gratuit sur le reverse engineering, assez intéressant.
Les sources Latex sont accessibles ici : https://github.com/dennis714/RE-for-beginners
dim. 04 oct. 2015 16:26:02 CEST -
-
link
- http://beginners.re/
reverse-engineering
Les sources Latex sont accessibles ici : https://github.com/dennis714/RE-for-beginners
dim. 04 oct. 2015 16:26:02 CEST -
-
link
- http://beginners.re/
reverse-engineering
The Song of the Introvert
 Étant moi-même un peu introverti, je traduis ici un article très intéressant sur la façon dont nous ressentons les interactions avec les autres :
Étant moi-même un peu introverti, je traduis ici un article très intéressant sur la façon dont nous ressentons les interactions avec les autres :
"Vous êtes une menace.
C'est un mot fort. Je ne veux pas dire que vous êtes synonyme de douleur, de blessure ou de dégât. Mais je suis un introverti et vous, en tant qu'inconnu, vous êtes une menace à mes yeux. Je ne sais pas ce quelles sont vos intentions, mais je suis certain que vous en avez. Aussi, tant que je ne sais quelles sont vos intentions exactes, vous êtes une menace. Car vous voyez...
J'ai des problèmes de contrôle.
Je ne suis serein que lorsque je suis seul dans mon Antre. Mes affaires y sont à leurs places, le mobilier est à mon goût et les murs sont rouges - ils m'entourent complètement. Il y a rarement des surprises dans mon Antre, et c'est comme ça que je l'aime, merci. Mon Antre est le lieu où je peux réduire le chaos et...
Vous êtes une forme de chaos.
Vous êtes une forme de désordre et de confusion. Je n'ai pas encore déterminé comment interagir visuellement avec vous, je ne sais pas non plus quelles sont vos intentions et je ne comprends donc pas qu'est-ce qui vous motive : vous êtes imprévisible. Vous êtes inconnu, ce qui signifie que vous êtes porteur d'inattendu, et l'inattendu n'est pas le sel de la vie, ce sont des données nouvelles qui ne cadrent pas encore avec mon système et...
Je suis obsédé par les systèmes.
Mon amour de la prévision a un coût. Je rédige absolument tout dans un petit carnet noir - sans lignes. Il y a des cases à côté de ce qui doit être suivi, il y a des étoiles pour ce que je ne dois pas oublier. Un surligneur jaune et un stylo bille .5mm m'accompagnent partout car ce carnet fait partie du système bien défini qui me permet de ne rien manquer. Vous voyez, paradoxalement, alors que je préférerais me cacher dans Antre, j'aime aussi beaucoup les signaux et...
Vous êtes plein de signaux.
Je suis fasciné par la façon dont vous ponctuez vos phrases avec vos mains. Vous faîtes des pauses aussi longtemps que nécessaire pour être sûr de dire quelque chose d'utile. Parfois ces pauses sont exaspéremment longues. Vous êtes profondément optimiste et affirmez bizarrement des choses impossibles. Vous n'avez pas peur de donner du feedback aux inconnus. Vous êtes capable de donner le même feedback avec un simple coup d'œil. C'est fascinant de voir comment chacun de vous construit ses propres systèmes pour vivre au quotidien. Je suis fasciné car...
Je suis insatiablement (et silencieusement) curieux.
Ma curiosité est un mécanisme de défense. J'essaye désespérément de retourner dans mon Antre, où la surprise est parfaitement planifiée. J'ai appris le plus de choses, le plus vite possible, à propos de vous : au plus vite je pourrais déterminer vos intentions, au plus vite je saurais ce qui vous motive. Et lorsque je saurais ce qui vous motive, je pourrais mieux comprendre comment communiquer avec vous. Je n'essaye pas de vous manipuler, je n'essaye pas de vous flatter, j'essaye simplement de vous comprendre car...
Je suis un introverti."
Bon, ce texte est un peu difficile à traduire, je trouve : il y a des phrases que j'ai interprété très librement. N'hésitez pas à me suggérer des améliorations par email : contact@benjaminbillet.fr
dim. 04 oct. 2015 16:06:52 CEST -
-
link
- http://randsinrepose.com/archives/the-song-of-the-introvert/
communication personnalité
"Vous êtes une menace.
C'est un mot fort. Je ne veux pas dire que vous êtes synonyme de douleur, de blessure ou de dégât. Mais je suis un introverti et vous, en tant qu'inconnu, vous êtes une menace à mes yeux. Je ne sais pas ce quelles sont vos intentions, mais je suis certain que vous en avez. Aussi, tant que je ne sais quelles sont vos intentions exactes, vous êtes une menace. Car vous voyez...
J'ai des problèmes de contrôle.
Je ne suis serein que lorsque je suis seul dans mon Antre. Mes affaires y sont à leurs places, le mobilier est à mon goût et les murs sont rouges - ils m'entourent complètement. Il y a rarement des surprises dans mon Antre, et c'est comme ça que je l'aime, merci. Mon Antre est le lieu où je peux réduire le chaos et...
Vous êtes une forme de chaos.
Vous êtes une forme de désordre et de confusion. Je n'ai pas encore déterminé comment interagir visuellement avec vous, je ne sais pas non plus quelles sont vos intentions et je ne comprends donc pas qu'est-ce qui vous motive : vous êtes imprévisible. Vous êtes inconnu, ce qui signifie que vous êtes porteur d'inattendu, et l'inattendu n'est pas le sel de la vie, ce sont des données nouvelles qui ne cadrent pas encore avec mon système et...
Je suis obsédé par les systèmes.
Mon amour de la prévision a un coût. Je rédige absolument tout dans un petit carnet noir - sans lignes. Il y a des cases à côté de ce qui doit être suivi, il y a des étoiles pour ce que je ne dois pas oublier. Un surligneur jaune et un stylo bille .5mm m'accompagnent partout car ce carnet fait partie du système bien défini qui me permet de ne rien manquer. Vous voyez, paradoxalement, alors que je préférerais me cacher dans Antre, j'aime aussi beaucoup les signaux et...
Vous êtes plein de signaux.
Je suis fasciné par la façon dont vous ponctuez vos phrases avec vos mains. Vous faîtes des pauses aussi longtemps que nécessaire pour être sûr de dire quelque chose d'utile. Parfois ces pauses sont exaspéremment longues. Vous êtes profondément optimiste et affirmez bizarrement des choses impossibles. Vous n'avez pas peur de donner du feedback aux inconnus. Vous êtes capable de donner le même feedback avec un simple coup d'œil. C'est fascinant de voir comment chacun de vous construit ses propres systèmes pour vivre au quotidien. Je suis fasciné car...
Je suis insatiablement (et silencieusement) curieux.
Ma curiosité est un mécanisme de défense. J'essaye désespérément de retourner dans mon Antre, où la surprise est parfaitement planifiée. J'ai appris le plus de choses, le plus vite possible, à propos de vous : au plus vite je pourrais déterminer vos intentions, au plus vite je saurais ce qui vous motive. Et lorsque je saurais ce qui vous motive, je pourrais mieux comprendre comment communiquer avec vous. Je n'essaye pas de vous manipuler, je n'essaye pas de vous flatter, j'essaye simplement de vous comprendre car...
Je suis un introverti."
Bon, ce texte est un peu difficile à traduire, je trouve : il y a des phrases que j'ai interprété très librement. N'hésitez pas à me suggérer des améliorations par email : contact@benjaminbillet.fr
dim. 04 oct. 2015 16:06:52 CEST -
-
link
- http://randsinrepose.com/archives/the-song-of-the-introvert/
communication personnalité
3 years of work
 C'est quoi une thèse ? 3 ans de travail et 180 tableaux blancs résumés en 11 secondes :')
C'est quoi une thèse ? 3 ans de travail et 180 tableaux blancs résumés en 11 secondes :')
http://benjaminbillet.fr/media/3yearsofwork.mp4
dim. 06 sept. 2015 20:48:17 CEST -
-
link
- http://benjaminbillet.fr/media/3yearsofwork.mp4
informatique stream-processing recherche
http://benjaminbillet.fr/media/3yearsofwork.mp4
dim. 06 sept. 2015 20:48:17 CEST -
-
link
- http://benjaminbillet.fr/media/3yearsofwork.mp4
informatique stream-processing recherche
Le prochain processeur mobile de Qualcomm va lutter contre les malwares | {niKo[piK]}
 Pour le grand public, la mise en oeuvre de la sécurité au niveau matériel n'est pas une bonne idée. La sécurité est le domaine qui évolue le plus vite en informatique, du fait de la lutte permanente entre ceux qui attaquent et ceux qui protègent.
Pour le grand public, la mise en oeuvre de la sécurité au niveau matériel n'est pas une bonne idée. La sécurité est le domaine qui évolue le plus vite en informatique, du fait de la lutte permanente entre ceux qui attaquent et ceux qui protègent.
Amener cela au niveau matériel signifie qu'il ne sera plus possible de mettre à jour la sécurité sans mettre à jour, au mieux, un firmware, là où une mise à jour du système d'exploitation aurait suffit.
sam. 05 sept. 2015 17:45:13 CEST -
-
link
- http://www.nikopik.com/2015/09/le-prochain-processeur-mobile-de-qualcomm-va-lutter-contre-les-malwares.html
sécurité
Amener cela au niveau matériel signifie qu'il ne sera plus possible de mettre à jour la sécurité sans mettre à jour, au mieux, un firmware, là où une mise à jour du système d'exploitation aurait suffit.
sam. 05 sept. 2015 17:45:13 CEST -
-
link
- http://www.nikopik.com/2015/09/le-prochain-processeur-mobile-de-qualcomm-va-lutter-contre-les-malwares.html
sécurité
L’économie malade de ses modèles | CNRS Le journal
 L'économie, telle qu'elle est pratiquée, étudiée, appliquée et encensée n'a aucune valeur scientifique. Il s'agit d'un empilement d'idées arbitraires, de postulats absurdes et de raisonnement mathématiques aberrants.
L'économie, telle qu'elle est pratiquée, étudiée, appliquée et encensée n'a aucune valeur scientifique. Il s'agit d'un empilement d'idées arbitraires, de postulats absurdes et de raisonnement mathématiques aberrants.
Deux extraits révélateurs :
"Adopter un point de vue dynamique est une évidence dans toutes les disciplines scientifiques, sauf pour les économistes néoclassiques, qui restent figés sur une méthodologie statique qui date des années 1870"
"Le pire étant que la validité mathématique de ces simplifications a été étudiée et réfutée (link is external) dans les années 1970 par l’économiste français Gérard Debreu. Malheureusement, comme à chaque fois que la communauté des économistes néoclassiques a été confrontée à un résultat qui la gênait, l’auteur a été célébré par un prix Nobel… et le résultat a été oublié."
sam. 05 sept. 2015 17:40:13 CEST -
-
link
- https://lejournal.cnrs.fr/articles/leconomie-malade-de-ses-modeles
économie piège bêtise
Deux extraits révélateurs :
"Adopter un point de vue dynamique est une évidence dans toutes les disciplines scientifiques, sauf pour les économistes néoclassiques, qui restent figés sur une méthodologie statique qui date des années 1870"
"Le pire étant que la validité mathématique de ces simplifications a été étudiée et réfutée (link is external) dans les années 1970 par l’économiste français Gérard Debreu. Malheureusement, comme à chaque fois que la communauté des économistes néoclassiques a été confrontée à un résultat qui la gênait, l’auteur a été célébré par un prix Nobel… et le résultat a été oublié."
sam. 05 sept. 2015 17:40:13 CEST -
-
link
- https://lejournal.cnrs.fr/articles/leconomie-malade-de-ses-modeles
économie piège bêtise
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.