Journal
Ce journal contient 354 entrées.
 RSS Feed
RSS Feed Tag cloud
Tag cloud
Teach Yourself Japanese
Teach Yourself Japanese
 dim. 05 mai 2019 10:58:41 CEST -
dim. 05 mai 2019 10:58:41 CEST -
 -
link
- http://www.sf.airnet.ne.jp/~ts/japanese/index.html
-
link
- http://www.sf.airnet.ne.jp/~ts/japanese/index.html
 langue japonais
langue japonais
dim. 05 mai 2019 10:58:41 CEST -
-
link
- http://www.sf.airnet.ne.jp/~ts/japanese/index.html
langue japonais
Getting started with the i3 tiling window manager
 Démarrer avec i3
Démarrer avec i3
dim. 05 mai 2019 10:54:40 CEST -
-
link
- https://fedoramagazine.org/getting-started-i3-window-manager
linux
dim. 05 mai 2019 10:54:40 CEST -
-
link
- https://fedoramagazine.org/getting-started-i3-window-manager
linux
/proc
 /proc in a nutshell :)
/proc in a nutshell :)
dim. 05 mai 2019 10:52:30 CEST -
-
link
- https://files.mastodon.social/media_attachments/files/003/362/858/original/dfaad2a178597a23.jpeg
linux
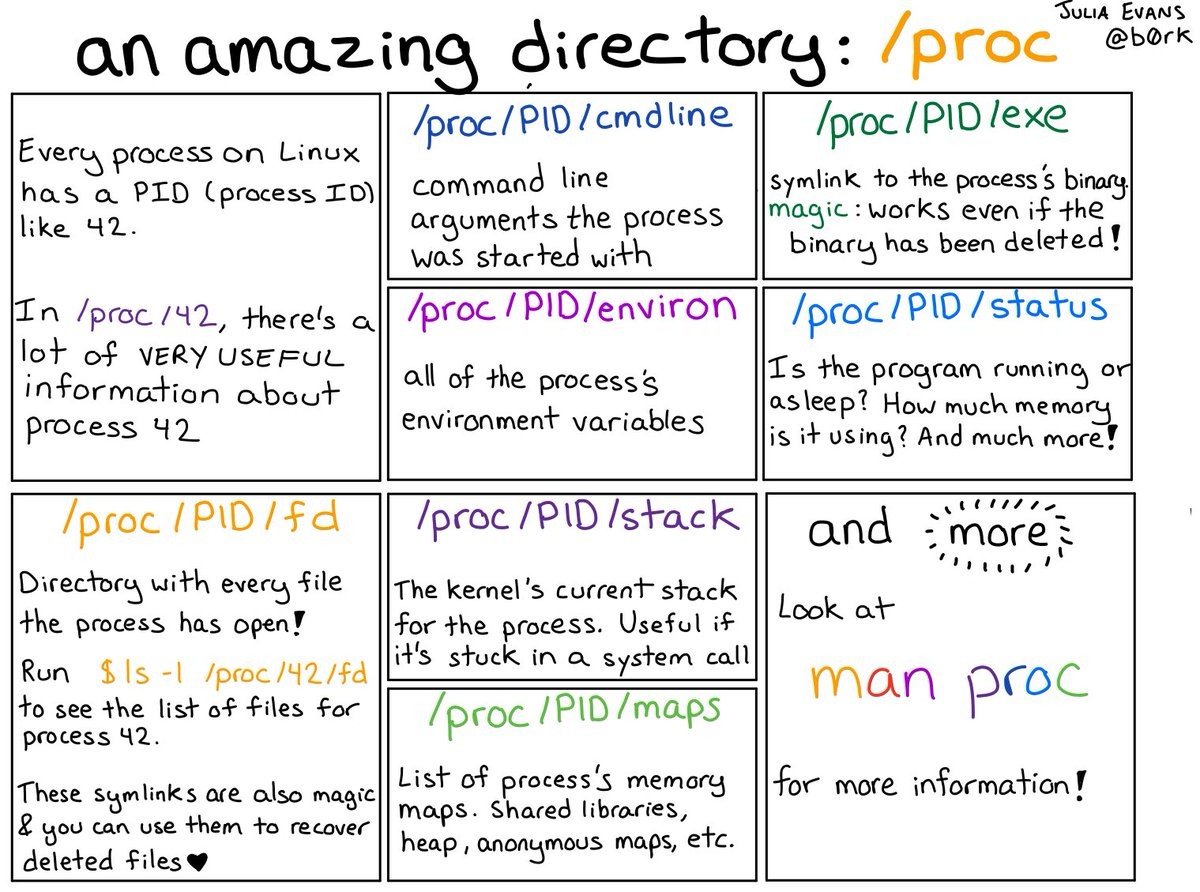{kind=link} dim. 05 mai 2019 10:52:30 CEST -
-
link
- https://files.mastodon.social/media_attachments/files/003/362/858/original/dfaad2a178597a23.jpeg
linux
dim. 05 mai 2019 10:52:30 CEST -
-
link
- https://files.mastodon.social/media_attachments/files/003/362/858/original/dfaad2a178597a23.jpeg
linux
AcoustID
 AcoustID is a project providing complete audio identification service, based entirely on open source software.
AcoustID is a project providing complete audio identification service, based entirely on open source software.
dim. 05 mai 2019 10:50:22 CEST -
-
link
- https://acoustid.org
musique multimédia
dim. 05 mai 2019 10:50:22 CEST -
-
link
- https://acoustid.org
musique multimédia
The Unreasonable Effectiveness of Recurrent Neural Networks
 Expérimentations avec des réseaux de neurones récurrents.
Expérimentations avec des réseaux de neurones récurrents.
Voir aussi (excellent blog): http://colah.github.io/posts/2015-08-Understanding-LSTMs
dim. 05 mai 2019 10:46:57 CEST -
-
link
- http://karpathy.github.io/2015/05/21/rnn-effectiveness
machine-learning
Voir aussi (excellent blog): http://colah.github.io/posts/2015-08-Understanding-LSTMs
dim. 05 mai 2019 10:46:57 CEST -
-
link
- http://karpathy.github.io/2015/05/21/rnn-effectiveness
machine-learning
OverTheWire: Wargames
 "The wargames offered by the OverTheWire community can help you to learn and practice security concepts in the form of fun-filled games."
"The wargames offered by the OverTheWire community can help you to learn and practice security concepts in the form of fun-filled games."
Pour les débutants, commencez par Bandit, pour intégrer les bases: http://overthewire.org/wargames/bandit
dim. 05 mai 2019 10:45:01 CEST -
-
link
- http://overthewire.org/wargames
sécurité jeu
Pour les débutants, commencez par Bandit, pour intégrer les bases: http://overthewire.org/wargames/bandit
dim. 05 mai 2019 10:45:01 CEST -
-
link
- http://overthewire.org/wargames
sécurité jeu
Seeing Theory
 A visual introduction to probability and statistics.
A visual introduction to probability and statistics.
dim. 05 mai 2019 10:42:03 CEST -
-
link
- https://seeing-theory.brown.edu
mathématiques statistiques
dim. 05 mai 2019 10:42:03 CEST -
-
link
- https://seeing-theory.brown.edu
mathématiques statistiques
Transcode
 transcode est un programme de traitement vidéo permettant notamment de stabiliser des vidéos.
transcode est un programme de traitement vidéo permettant notamment de stabiliser des vidéos.
dim. 05 mai 2019 10:38:55 CEST -
-
link
- http://www.quennec.fr/trucs-astuces/syst%C3%A8mes/gnulinux/commandes/multim%C3%A9dia/vid%C3%A9o/transcode
vidéo
dim. 05 mai 2019 10:38:55 CEST -
-
link
- http://www.quennec.fr/trucs-astuces/syst%C3%A8mes/gnulinux/commandes/multim%C3%A9dia/vid%C3%A9o/transcode
vidéo
Computing linear regression in one pass
 Dans le même ordre d'idée que le lien précédent, sauf qu'il s'agit cette fois d'effectuer une régression linéaire en continu. Comme beaucoup d'algorithmes continu, il présente l'avantage de travailler en mémoire constante.
Dans le même ordre d'idée que le lien précédent, sauf qu'il s'agit cette fois d'effectuer une régression linéaire en continu. Comme beaucoup d'algorithmes continu, il présente l'avantage de travailler en mémoire constante.
Le thumbnail vient de XKCD : https://xkcd.com/1725
lun. 10 avril 2017 10:32:57 CEST -
-
link
- https://www.johndcook.com/blog/running_regression/
mathématiques statistiques stream-processing
Le thumbnail vient de XKCD : https://xkcd.com/1725
lun. 10 avril 2017 10:32:57 CEST -
-
link
- https://www.johndcook.com/blog/running_regression/
mathématiques statistiques stream-processing
Computing skewness and kurtosis in one pass
 Comme vous l'avez peut être déjà remarqué, une bonne partie de mes travaux de thèse ont porté sur le traitement continu de flux de données : http://benjaminbillet.fr/media/benjaminbillet_memoire.pdf
Comme vous l'avez peut être déjà remarqué, une bonne partie de mes travaux de thèse ont porté sur le traitement continu de flux de données : http://benjaminbillet.fr/media/benjaminbillet_memoire.pdf
De fait, je m'intéresse beaucoup aux techniques mathématiques permettant de réaliser des calculs en continu (c'est-à-dire sans mémoriser l'intégralité des résultats passés).
Cet article de blog décrit comment calculer en continu l'espérance, la variance, l'écart-type, le coefficient de dissymétrie et le coefficient d'aplatissement sur un flux d'échantillons. De manière plus générale il s'agit d'une méthode pour calculer les moments (https://fr.wikipedia.org/wiki/Moment_%28mathématiques%29). On pourrait imaginer donc l'utiliser pour calculer d'autres mesures statistiques d'ordre supérieur. J'essayerais d'ailleurs, si je parviens à bien tout comprendre, d'en faire une implémentation généralisée :)
Quelques références:
- B. P. Welford (1962)."Note on a method for calculating corrected sums of squares and products".
- Donald E. Knuth (1998). The Art of Computer Programming, volume 2: Seminumerical Algorithms, 3rd edn.
lun. 10 avril 2017 10:22:27 CEST -
-
link
- https://www.johndcook.com/blog/skewness_kurtosis/
mathématiques statistiques stream-processing
De fait, je m'intéresse beaucoup aux techniques mathématiques permettant de réaliser des calculs en continu (c'est-à-dire sans mémoriser l'intégralité des résultats passés).
Cet article de blog décrit comment calculer en continu l'espérance, la variance, l'écart-type, le coefficient de dissymétrie et le coefficient d'aplatissement sur un flux d'échantillons. De manière plus générale il s'agit d'une méthode pour calculer les moments (https://fr.wikipedia.org/wiki/Moment_%28mathématiques%29). On pourrait imaginer donc l'utiliser pour calculer d'autres mesures statistiques d'ordre supérieur. J'essayerais d'ailleurs, si je parviens à bien tout comprendre, d'en faire une implémentation généralisée :)
Quelques références:
- B. P. Welford (1962)."Note on a method for calculating corrected sums of squares and products".
- Donald E. Knuth (1998). The Art of Computer Programming, volume 2: Seminumerical Algorithms, 3rd edn.
lun. 10 avril 2017 10:22:27 CEST -
-
link
- https://www.johndcook.com/blog/skewness_kurtosis/
mathématiques statistiques stream-processing
libcoap: C-Implementation of CoAP
 Implémentation en C du protocole CoAP (un protocole REST pour les machines fortement limitées en ressources, pour lequel il existe un mapping avec HTTP), décrit dans la RFC 7252.
Implémentation en C du protocole CoAP (un protocole REST pour les machines fortement limitées en ressources, pour lequel il existe un mapping avec HTTP), décrit dans la RFC 7252.
En plus du protocole de base, cette librairie implémente les ressources observables (RFC 7641) et la découverte des ressources liées (RFC 6690). Elle implémente aussi certains brouillons, comme l'annuaire de ressources CoAP (https://tools.ietf.org/html/draft-ietf-core-resource-directory-10).
RFC 7252 : https://tools.ietf.org/html/rfc7252
RFC 7641 : https://tools.ietf.org/html/rfc7641
RFC 6690 : https://tools.ietf.org/html/rfc6690
dim. 09 avril 2017 20:23:42 CEST -
-
link
- https://libcoap.net/
coap outil réseau rfc iot
En plus du protocole de base, cette librairie implémente les ressources observables (RFC 7641) et la découverte des ressources liées (RFC 6690). Elle implémente aussi certains brouillons, comme l'annuaire de ressources CoAP (https://tools.ietf.org/html/draft-ietf-core-resource-directory-10).
RFC 7252 : https://tools.ietf.org/html/rfc7252
RFC 7641 : https://tools.ietf.org/html/rfc7641
RFC 6690 : https://tools.ietf.org/html/rfc6690
dim. 09 avril 2017 20:23:42 CEST -
-
link
- https://libcoap.net/
coap outil réseau rfc iot
EXIF Tags
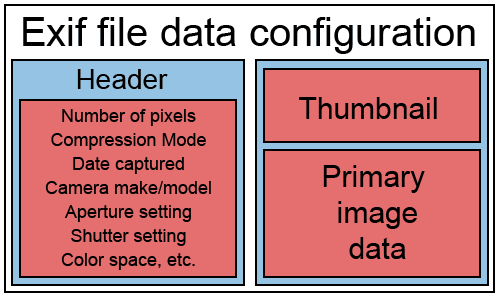 Liste des champs de l'Exchangeable Image File Format (EXIF) décrit de manière synthétique.
Liste des champs de l'Exchangeable Image File Format (EXIF) décrit de manière synthétique.
dim. 09 avril 2017 20:09:37 CEST -
-
link
- http://www.sno.phy.queensu.ca/~phil/exiftool/TagNames/EXIF.html
exif jpeg image 2d
dim. 09 avril 2017 20:09:37 CEST -
-
link
- http://www.sno.phy.queensu.ca/~phil/exiftool/TagNames/EXIF.html
exif jpeg image 2d
Les algorithmes : nouvelles formes de bureaucraties ? | InternetActu
 L'essayiste Adam Clair dresse une intéressante comparaison entre algorithme et bureaucratie. Les algorithmes sont paradoxaux rappelle-t-il : « ils sont conçus pour améliorer la prise de décision humaine en supprimant supposément ses biais et ses limites, mais les protocoles analytiques inévitablement réducteurs qu’ils mettent en œuvre se révèlent surtout vulnérables à des formes d’utilisation abusive. » Comme le dit très bien Cathy O’Neil dans son livre : loin d’être neutres et objectifs, « les algorithmes sont des opinions formalisées dans du code ».
L'essayiste Adam Clair dresse une intéressante comparaison entre algorithme et bureaucratie. Les algorithmes sont paradoxaux rappelle-t-il : « ils sont conçus pour améliorer la prise de décision humaine en supprimant supposément ses biais et ses limites, mais les protocoles analytiques inévitablement réducteurs qu’ils mettent en œuvre se révèlent surtout vulnérables à des formes d’utilisation abusive. » Comme le dit très bien Cathy O’Neil dans son livre : loin d’être neutres et objectifs, « les algorithmes sont des opinions formalisées dans du code ».
On parle bien sur ici des algorithmes dans le sens restreint de prise de décision pour le compte d'une organisation (les États, en l'occurrence). Par définition, donc, les algorithmes ne sont pas une *nouvelle* forme de bureaucratie ; ils en sont une parfaite implémentation. Il est effectivement peu pertinent de s'en prendre aux algorithmes pour critiquer les travers des bureaucratie, tout comme il est peut pertinent de s'en prendre au machine pour critiquer la disparition de l'emploi.
sam. 08 avril 2017 18:04:57 CEST -
-
link
- http://internetactu.blog.lemonde.fr/2017/04/08/les-algorithmes-nouvelles-formes-de-bureaucraties/
société algorithmique
On parle bien sur ici des algorithmes dans le sens restreint de prise de décision pour le compte d'une organisation (les États, en l'occurrence). Par définition, donc, les algorithmes ne sont pas une *nouvelle* forme de bureaucratie ; ils en sont une parfaite implémentation. Il est effectivement peu pertinent de s'en prendre aux algorithmes pour critiquer les travers des bureaucratie, tout comme il est peut pertinent de s'en prendre au machine pour critiquer la disparition de l'emploi.
sam. 08 avril 2017 18:04:57 CEST -
-
link
- http://internetactu.blog.lemonde.fr/2017/04/08/les-algorithmes-nouvelles-formes-de-bureaucraties/
société algorithmique
Géolocalisation des trains
 Tous les trains de la SNCF positionnés en temps réel (délai d'environ 5mn) sur une carte interactive.
Tous les trains de la SNCF positionnés en temps réel (délai d'environ 5mn) sur une carte interactive.
dim. 19 mars 2017 13:36:03 CET -
-
link
- http://www.sncf.com/fr/geolocalisation
outil
dim. 19 mars 2017 13:36:03 CET -
-
link
- http://www.sncf.com/fr/geolocalisation
outil
Tools | Ludum Dare
 Liste d'outils utilisés par les participants au Ludum Dare (compétition de développement de jeux vidéo en 48h avec un thème imposé). Il y a de tout, des outils simplifiés (Construct, Game Maker, GDevelop), des moteurs (Unity, Murl), des outils de dessin et de modélisation, etc.
Liste d'outils utilisés par les participants au Ludum Dare (compétition de développement de jeux vidéo en 48h avec un thème imposé). Il y a de tout, des outils simplifiés (Construct, Game Maker, GDevelop), des moteurs (Unity, Murl), des outils de dessin et de modélisation, etc.
dim. 19 mars 2017 13:33:08 CET -
-
link
- http://ludumdare.com/compo/tools/
jeu-vidéo 2d 3d
dim. 19 mars 2017 13:33:08 CET -
-
link
- http://ludumdare.com/compo/tools/
jeu-vidéo 2d 3d
Réparer npm lorsqu'il s'autodétruit
 Si, pour une raison inconnue, npm s'autodétruit après une mise à jour globale (npm update -g), il peut s'agir d'un problème lié à une ancienne version.
Si, pour une raison inconnue, npm s'autodétruit après une mise à jour globale (npm update -g), il peut s'agir d'un problème lié à une ancienne version.
Réinstallez node (par exemple: brew uninstall --force node && brew install node) puis réinstallez npm en utilisant la version de npm fournie avec node (npm install -g npm).
C'est un problème idiot, mais malheureusement fréquent: https://github.com/npm/npm/issues/4099
jeu. 16 mars 2017 15:20:56 CET -
-
link
javascript npm
Réinstallez node (par exemple: brew uninstall --force node && brew install node) puis réinstallez npm en utilisant la version de npm fournie avec node (npm install -g npm).
C'est un problème idiot, mais malheureusement fréquent: https://github.com/npm/npm/issues/4099
jeu. 16 mars 2017 15:20:56 CET -
-
link
javascript npm
Table des matières: Tout ce que les développeurs devraient savoir sur les performances en SQL
 Tout est dans le titre. Il y a beaucoup de choses intéressantes, notamment sur les performances de la pagination et des tris.
Tout est dans le titre. Il y a beaucoup de choses intéressantes, notamment sur les performances de la pagination et des tris.
mer. 25 janv. 2017 11:35:31 CET -
-
link
- http://use-the-index-luke.com/fr/table-des-matieres
bdd sql
mer. 25 janv. 2017 11:35:31 CET -
-
link
- http://use-the-index-luke.com/fr/table-des-matieres
bdd sql
Amit’s A* Pages
 Beaucoup d'informations et d'expérimentations autour de A* (algorithme de pathfinding dont j'avais déjà parlé là en citant le même blog : http://www.benjaminbillet.fr/news/index.php?link=d5gw4e).
Beaucoup d'informations et d'expérimentations autour de A* (algorithme de pathfinding dont j'avais déjà parlé là en citant le même blog : http://www.benjaminbillet.fr/news/index.php?link=d5gw4e).
Il y a plusieurs sujets abordés en bas de page, dont la construction de maps dans les jeux vidéos.
Voir aussi: http://www.redblobgames.com
mer. 25 janv. 2017 11:32:34 CET -
-
link
- http://theory.stanford.edu/~amitp/GameProgramming/
pathfinding algorithmique
Il y a plusieurs sujets abordés en bas de page, dont la construction de maps dans les jeux vidéos.
Voir aussi: http://www.redblobgames.com
mer. 25 janv. 2017 11:32:34 CET -
-
link
- http://theory.stanford.edu/~amitp/GameProgramming/
pathfinding algorithmique
Strong consistency models
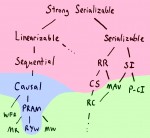 Article intéressant sur les modèles de consistances.
Article intéressant sur les modèles de consistances.
Ce blog est une mine d'informations.
mer. 25 janv. 2017 10:56:17 CET -
-
link
- https://aphyr.com/posts/313-strong-consistency-models
consistance bdd
Ce blog est une mine d'informations.
mer. 25 janv. 2017 10:56:17 CET -
-
link
- https://aphyr.com/posts/313-strong-consistency-models
consistance bdd
World's Smallest h.264 Encoder | Cardinal Peak
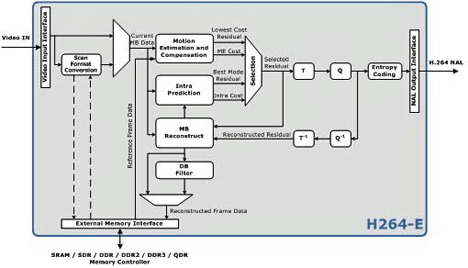 Le plus petit encodeur compatible avec la norme d'encodage vidéo H.264.
Le plus petit encodeur compatible avec la norme d'encodage vidéo H.264.
mer. 25 janv. 2017 10:45:00 CET -
-
link
- https://cardinalpeak.com/blog/worlds-smallest-h-264-encoder/
vidéo h264
mer. 25 janv. 2017 10:45:00 CET -
-
link
- https://cardinalpeak.com/blog/worlds-smallest-h-264-encoder/
vidéo h264
UserAgentString.com - List of User Agent Strings
 Liste d'User-Agent par navigateur. Je n'aurais pas imaginé qu'il puisse en exister autant.
Liste d'User-Agent par navigateur. Je n'aurais pas imaginé qu'il puisse en exister autant.
Voir aussi le délirant historique des User-Agent: http://webaim.org/blog/user-agent-string-history
mer. 25 janv. 2017 10:42:31 CET -
-
link
- http://useragentstring.com/pages/useragentstring.php
navigateur
Voir aussi le délirant historique des User-Agent: http://webaim.org/blog/user-agent-string-history
mer. 25 janv. 2017 10:42:31 CET -
-
link
- http://useragentstring.com/pages/useragentstring.php
navigateur
EE Times - 10 FPGA Design Techniques You Should Know
 "There are a number of universal design techniques with which FPGA engineers should be familiar -- here are some of the most important."
"There are a number of universal design techniques with which FPGA engineers should be familiar -- here are some of the most important."
A lire, ne serait-ce que par curiosité ;)
mer. 25 janv. 2017 10:41:36 CET -
-
link
- http://www.eetimes.com/document.asp?doc_id=1330128&print=yes
fpga électronique
A lire, ne serait-ce que par curiosité ;)
mer. 25 janv. 2017 10:41:36 CET -
-
link
- http://www.eetimes.com/document.asp?doc_id=1330128&print=yes
fpga électronique
Blue-Green Deployment
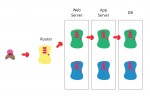 Le déploiement bleu-vert est une technique classique pour déployer une nouvelle version d'un serveur en évitant une interruption de service.
Le déploiement bleu-vert est une technique classique pour déployer une nouvelle version d'un serveur en évitant une interruption de service.
A noter: les tenants de cette technique passent souvent sous silence les problèmes de synchronisation entre les bases de données bleue et verte. La solution la plus radicale consiste à interdire les écritures, pour ne pas avoir à gérer la synchronisation. Ce n'est pas forcément idéal en pratique.
Si l'on souhaite conserver les écritures, alors deux cas se posent:
- le schéma de la base verte est le même que celui de la base bleu : il suffit que le système vert réplique les écritures dans les deux bases.
- le schéma de la base verte est différent de celui de la base bleu : il faut s'assurer que le système vert soit rétro-compatible avec la base bleue, pour pouvoir répliquer les écritures.
Voir aussi: https://www.rainforestqa.com/blog/2014-06-27-zero-downtime-database-migrations/
mer. 25 janv. 2017 10:39:30 CET -
-
link
- https://martinfowler.com/bliki/BlueGreenDeployment.html
architecture bdd
A noter: les tenants de cette technique passent souvent sous silence les problèmes de synchronisation entre les bases de données bleue et verte. La solution la plus radicale consiste à interdire les écritures, pour ne pas avoir à gérer la synchronisation. Ce n'est pas forcément idéal en pratique.
Si l'on souhaite conserver les écritures, alors deux cas se posent:
- le schéma de la base verte est le même que celui de la base bleu : il suffit que le système vert réplique les écritures dans les deux bases.
- le schéma de la base verte est différent de celui de la base bleu : il faut s'assurer que le système vert soit rétro-compatible avec la base bleue, pour pouvoir répliquer les écritures.
Voir aussi: https://www.rainforestqa.com/blog/2014-06-27-zero-downtime-database-migrations/
mer. 25 janv. 2017 10:39:30 CET -
-
link
- https://martinfowler.com/bliki/BlueGreenDeployment.html
architecture bdd
Colorful Image Colorization
 Cette technique de recolorisation d'image donne des résultats impressionnants
Cette technique de recolorisation d'image donne des résultats impressionnants
mer. 25 janv. 2017 10:21:08 CET -
-
link
- http://richzhang.github.io/colorization/
machine-learning image-processing 2d image
mer. 25 janv. 2017 10:21:08 CET -
-
link
- http://richzhang.github.io/colorization/
machine-learning image-processing 2d image
Loading models - Vulkan Tutorial
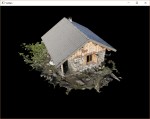 Vulkan (précedemment connu sous le nom d'OpenGL Next) est une interface de programmation graphique destinée à remplacer OpenGL. Plus moderne et plus efficace, il vise à unifier les versions mobiles (OpenGL ES) et bureau (OpenGL).
Vulkan (précedemment connu sous le nom d'OpenGL Next) est une interface de programmation graphique destinée à remplacer OpenGL. Plus moderne et plus efficace, il vise à unifier les versions mobiles (OpenGL ES) et bureau (OpenGL).
Je m'y suis mis pour tester, et c'est clairement un gros dépoussiérage d'OpenGL. Tout est plus clair (simplification), plus direct (suppression des fonctionnalités obsolètes ou redondantes), etc.
mer. 25 janv. 2017 10:05:26 CET -
-
link
- https://vulkan-tutorial.com/Loading_models
3d
Je m'y suis mis pour tester, et c'est clairement un gros dépoussiérage d'OpenGL. Tout est plus clair (simplification), plus direct (suppression des fonctionnalités obsolètes ou redondantes), etc.
mer. 25 janv. 2017 10:05:26 CET -
-
link
- https://vulkan-tutorial.com/Loading_models
3d
git-flow cheatsheet
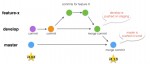 Comprendre git-flow en une infographie.
Comprendre git-flow en une infographie.
mer. 25 janv. 2017 10:00:51 CET -
-
link
- http://danielkummer.github.io/git-flow-cheatsheet/
git outil
mer. 25 janv. 2017 10:00:51 CET -
-
link
- http://danielkummer.github.io/git-flow-cheatsheet/
git outil
Seamless Cloning using OpenCV ( Python , C++ ) | Learn OpenCV
 Utilisation du Seamless Clone d'OpenCV pour fusionner deux images.
Utilisation du Seamless Clone d'OpenCV pour fusionner deux images.
mer. 25 janv. 2017 09:59:21 CET -
-
link
- http://www.learnopencv.com/seamless-cloning-using-opencv-python-cpp/
image-processing image 2d opencv
mer. 25 janv. 2017 09:59:21 CET -
-
link
- http://www.learnopencv.com/seamless-cloning-using-opencv-python-cpp/
image-processing image 2d opencv
Face Swap using OpenCV ( C++ / Python ) | Learn OpenCV
 Je me suis mis à OpenCV récemment pour développer un outil de redimensionnement d'image avec détection de visage. J'en parlerais peut être dans le blog technique, vu que j'ai rencontré pas mal de soucis avec sa compilation et son binding JNI.
Je me suis mis à OpenCV récemment pour développer un outil de redimensionnement d'image avec détection de visage. J'en parlerais peut être dans le blog technique, vu que j'ai rencontré pas mal de soucis avec sa compilation et son binding JNI.
Bref, je suis tombé sur cet article décrivant comment faire du "face swapping" avec la librairie.
mer. 25 janv. 2017 09:54:59 CET -
-
link
- http://www.learnopencv.com/face-swap-using-opencv-c-python/
image-processing image 2d opencv
Bref, je suis tombé sur cet article décrivant comment faire du "face swapping" avec la librairie.
mer. 25 janv. 2017 09:54:59 CET -
-
link
- http://www.learnopencv.com/face-swap-using-opencv-c-python/
image-processing image 2d opencv
htop-explique | Le blog de Carl Chenet
 Traduction française de l'excellent "htop explained": https://peteris.rocks/blog/htop
Traduction française de l'excellent "htop explained": https://peteris.rocks/blog/htop
mer. 25 janv. 2017 09:51:14 CET -
-
link
- https://carlchenet.com/category/htop-explique/
htop outil
mer. 25 janv. 2017 09:51:14 CET -
-
link
- https://carlchenet.com/category/htop-explique/
htop outil
The Infinite Drum Machine
 Une expérience de classification automatique sur des fichiers audio représentant des sons du quotidien. L'algorithme ne reçoit aucune information à priori (non supervisé) hormis les fichiers audio. La technique utilisée dans cette expérience est t-SNE (t-Distributed Stochastic Neighbor Embedding), permettant de réduire un espace à n dimensions vers un espace plus petit (ici 3 dimensions: X, Y, et couleur).
Une expérience de classification automatique sur des fichiers audio représentant des sons du quotidien. L'algorithme ne reçoit aucune information à priori (non supervisé) hormis les fichiers audio. La technique utilisée dans cette expérience est t-SNE (t-Distributed Stochastic Neighbor Embedding), permettant de réduire un espace à n dimensions vers un espace plus petit (ici 3 dimensions: X, Y, et couleur).
Description de t-SNE: http://jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
mer. 25 janv. 2017 09:47:44 CET -
-
link
- https://aiexperiments.withgoogle.com/drum-machine
machine-learning datamining clustering
Description de t-SNE: http://jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
mer. 25 janv. 2017 09:47:44 CET -
-
link
- https://aiexperiments.withgoogle.com/drum-machine
machine-learning datamining clustering
How to Write Papers So People Can Read Them - POPL 2016
 Comment écrire des articles scientifiques compréhensibles (certains principes généraux s'appliquent pour tout travail d'écriture).
Comment écrire des articles scientifiques compréhensibles (certains principes généraux s'appliquent pour tout travail d'écriture).
Les slides: https://www.mpi-sws.org/~dreyer/talks/talk-plmw16.pdf
mer. 25 janv. 2017 09:29:47 CET -
-
link
- https://youtu.be/L_6xoMjFr70
écriture
Les slides: https://www.mpi-sws.org/~dreyer/talks/talk-plmw16.pdf
mer. 25 janv. 2017 09:29:47 CET -
-
link
- https://youtu.be/L_6xoMjFr70
écriture
CDNs aren't just for caching - Julia Evans
 Un CDN ne sert pas qu'à faire du caching, mais aussi à:
Un CDN ne sert pas qu'à faire du caching, mais aussi à:
- amener le contenu au plus près des clients, donc accélérer l'accès
- accélérer l'ouverture des connexions TLS (https://en.wikipedia.org/wiki/Transport_Layer_Security#TLS_handshake)
- réduire l'impact des attaques par déni de service
mer. 25 janv. 2017 09:17:28 CET -
-
link
- http://jvns.ca/blog/2016/04/29/cdns-arent-just-for-caching/
cdn
- amener le contenu au plus près des clients, donc accélérer l'accès
- accélérer l'ouverture des connexions TLS (https://en.wikipedia.org/wiki/Transport_Layer_Security#TLS_handshake)
- réduire l'impact des attaques par déni de service
mer. 25 janv. 2017 09:17:28 CET -
-
link
- http://jvns.ca/blog/2016/04/29/cdns-arent-just-for-caching/
cdn
Séries de Fourier
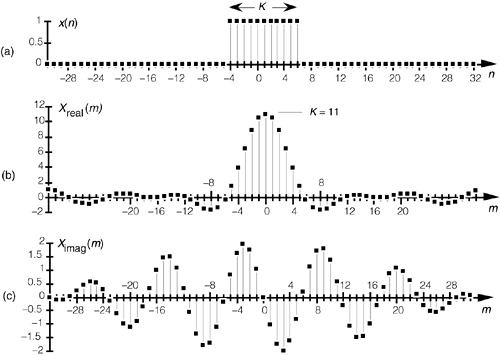 Voir aussi: http://www.benjaminbillet.fr/news/index.php?link=d5gw8e
Voir aussi: http://www.benjaminbillet.fr/news/index.php?link=d5gw8e
mer. 25 janv. 2017 09:10:18 CET -
-
link
- http://licence-eea.fr/series-de-fourier/
mathématiques signal-processing
mer. 25 janv. 2017 09:10:18 CET -
-
link
- http://licence-eea.fr/series-de-fourier/
mathématiques signal-processing
DBeaver | Free Universal SQL Client
"Free multi-platform database tool for developers, SQL programmers, database administrators and analysts. Supports all popular databases: MySQL, PostgreSQL, SQLite, Oracle, DB2, SQL Server, Sybase, Teradata, MongoDB, Cassandra, Redis, etc."
Et plus stable que MySQL workbench.
mer. 25 janv. 2017 09:03:47 CET -
-
link
- http://dbeaver.jkiss.org/
bdd
Et plus stable que MySQL workbench.
mer. 25 janv. 2017 09:03:47 CET -
-
link
- http://dbeaver.jkiss.org/
bdd
A Year Without a Byte | code.flickr.com
 Quelques techniques utilisées par Flickr pour économiser l'espace de stockage.
Quelques techniques utilisées par Flickr pour économiser l'espace de stockage.
- Pour éviter des baisses de performance, on conserve toujours un peu d'espace disque libre (traditionnellement 10%). Toutefois, ce paramètre peut être ajusté empiriquement en fonction de l'usage (ici, réduit à 5%)
- Stocker moins de formats de miniature et laisser les clients (webs et mobiles) ajuster la taille de leur côté. Par exemple, si un client a besoin d'afficher une image en 1024x1024px, il va télécharger la version 2048x2048 et effectuer la réduction de son côté.
- Utiliser des algorithmes de compression d'image plus sophistiqués. Ces techniques consomment plus de CPU, mais peuvent réduire significativement la taille des images. Là encore, c'est à voir en fonction du besoin.
mer. 25 janv. 2017 08:56:13 CET -
-
link
- https://code.flickr.net/2017/01/05/a-year-without-a-byte/
stockage
- Pour éviter des baisses de performance, on conserve toujours un peu d'espace disque libre (traditionnellement 10%). Toutefois, ce paramètre peut être ajusté empiriquement en fonction de l'usage (ici, réduit à 5%)
- Stocker moins de formats de miniature et laisser les clients (webs et mobiles) ajuster la taille de leur côté. Par exemple, si un client a besoin d'afficher une image en 1024x1024px, il va télécharger la version 2048x2048 et effectuer la réduction de son côté.
- Utiliser des algorithmes de compression d'image plus sophistiqués. Ces techniques consomment plus de CPU, mais peuvent réduire significativement la taille des images. Là encore, c'est à voir en fonction du besoin.
mer. 25 janv. 2017 08:56:13 CET -
-
link
- https://code.flickr.net/2017/01/05/a-year-without-a-byte/
stockage
GitHub - tdebatty/java-string-similarity: Implementation of various string similarity and distance algorithms: Levenshtein, Jaro-winkler, n-Gram, Q-Gr
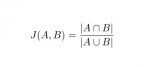 Une librairie Java pour calculer des distances ou des scores de similarité entre des chaînes de caractères.
Une librairie Java pour calculer des distances ou des scores de similarité entre des chaînes de caractères.
Algorithmes implémentés :
Levenshtein O(m*n)
Normalized Levenshtein O(m*n)
Weighted Levenshtein O(m*n)
Damerau-Levenshtein O(m*n)
Optimal String Alignment O(m*n)
Jaro-Winkler O(m*n)
Longest Common Subsequence O(m*n)
Metric Longest Common Subsequence O(m*n)
N-Gram O(m*n)
Q-Gram O(m+n)
Cosine similarity O(m+n)
Jaccard index O(m+n)
Sorensen-Dice coefficient O(m+n)
mer. 19 oct. 2016 12:38:50 CEST -
-
link
- https://github.com/tdebatty/java-string-similarity
similarité java algorithmique
Algorithmes implémentés :
Levenshtein O(m*n)
Normalized Levenshtein O(m*n)
Weighted Levenshtein O(m*n)
Damerau-Levenshtein O(m*n)
Optimal String Alignment O(m*n)
Jaro-Winkler O(m*n)
Longest Common Subsequence O(m*n)
Metric Longest Common Subsequence O(m*n)
N-Gram O(m*n)
Q-Gram O(m+n)
Cosine similarity O(m+n)
Jaccard index O(m+n)
Sorensen-Dice coefficient O(m+n)
mer. 19 oct. 2016 12:38:50 CEST -
-
link
- https://github.com/tdebatty/java-string-similarity
similarité java algorithmique
FarmBot
 FarmBot, un robot pour contrôler une petite plantation. Il peut planter, contrôler l'arrosage, détecter et tuer les mauvaises herbes, etc.
FarmBot, un robot pour contrôler une petite plantation. Il peut planter, contrôler l'arrosage, détecter et tuer les mauvaises herbes, etc.
C'est un bien beau bidule, il faut avouer.
Les plans sont open-source, ce qui est un bon point, mais la fabrication des pièces nécessite d'être bien équipé (imprimante 3D, outil de découpe du métal).
Possibilité de commander un kit de pièces pour 3500$, ce qui est malheureusement beaucoup trop cher :/
lun. 17 oct. 2016 16:16:37 CEST -
-
link
- http://i.imgur.com/L4D8gJN.mp4
robotique
C'est un bien beau bidule, il faut avouer.
Les plans sont open-source, ce qui est un bon point, mais la fabrication des pièces nécessite d'être bien équipé (imprimante 3D, outil de découpe du métal).
Possibilité de commander un kit de pièces pour 3500$, ce qui est malheureusement beaucoup trop cher :/
lun. 17 oct. 2016 16:16:37 CEST -
-
link
- http://i.imgur.com/L4D8gJN.mp4
robotique
Megaprocessor
 Traduction de la page d'accueil du projet:
Traduction de la page d'accueil du projet:
Qu'est-ce que c'est ? Le Megaprocessor est un microprocesseur, mais construit en plus gros. Beaucoup plus gros.
Comment ? Comme tous les processeurs modernes, le Megaprocessor fonctionne avec des transistors. Par contre, au lieu d'utiliser des transistors gravés sur une minuscule puce en silicium, il utilise des transistors individuels (NB: taille équivalente à un cube de 0.5 cm de côté). Par milliers. Et aussi énormément de LED (NB: diode électro-luminescente).
Pourquoi ? Réponse courte : Parce que je le voulais.
Pourquoi ? Réponse longue : Les ordinateurs sont plutôt opaques, il est impossible de comprendre comment ils marchent en regardant à l'intérieur. Ce que j'ai voulu faire, c'est entrer à l'intérieur et voir ce qui se passe. Le souci, c'est qu'on ne peut pas se rétrécir suffisamment pour marcher à l'intérieur d'une puce de silicium. Par contre, on peut faire le contraire : construire un processeur suffisamment gros pour marcher à l'intérieur. En plus, en ajoutant plein de LEDs, on pourrait VOIR les données circuler et les opérations logiques s'effectuer en temps réel. Ce serait génial.
--
Et je confirme : c'est génial. On peut même le programmer avec un assembleur basique (http://megaprocessor.com/programming.html)
lun. 17 oct. 2016 16:10:26 CEST -
-
link
- http://megaprocessor.com/
processeur électronique
Qu'est-ce que c'est ? Le Megaprocessor est un microprocesseur, mais construit en plus gros. Beaucoup plus gros.
Comment ? Comme tous les processeurs modernes, le Megaprocessor fonctionne avec des transistors. Par contre, au lieu d'utiliser des transistors gravés sur une minuscule puce en silicium, il utilise des transistors individuels (NB: taille équivalente à un cube de 0.5 cm de côté). Par milliers. Et aussi énormément de LED (NB: diode électro-luminescente).
Pourquoi ? Réponse courte : Parce que je le voulais.
Pourquoi ? Réponse longue : Les ordinateurs sont plutôt opaques, il est impossible de comprendre comment ils marchent en regardant à l'intérieur. Ce que j'ai voulu faire, c'est entrer à l'intérieur et voir ce qui se passe. Le souci, c'est qu'on ne peut pas se rétrécir suffisamment pour marcher à l'intérieur d'une puce de silicium. Par contre, on peut faire le contraire : construire un processeur suffisamment gros pour marcher à l'intérieur. En plus, en ajoutant plein de LEDs, on pourrait VOIR les données circuler et les opérations logiques s'effectuer en temps réel. Ce serait génial.
--
Et je confirme : c'est génial. On peut même le programmer avec un assembleur basique (http://megaprocessor.com/programming.html)
lun. 17 oct. 2016 16:10:26 CEST -
-
link
- http://megaprocessor.com/
processeur électronique
98 personal data points that Facebook uses to target ads to you - The Washington Post
 Facebook utilise 98 informations vous concernant pour déterminer quelles sont les publicités les plus susceptibles de vous intéresser.
Facebook utilise 98 informations vous concernant pour déterminer quelles sont les publicités les plus susceptibles de vous intéresser.
9. Ethnic affinity
...
20. Users in long-distance relationships
...
31. Conservatives and liberals
...
45. How much money user is likely to spend on next car
...
79. Users who are “heavy” buyers of beer, wine or spirits
...
82. Users who buy allergy medications, cough/cold medications, pain relief products, and over-the-counter meds
...
89. Users who are “receptive” to offers from companies offering online auto insurance, higher education or mortgages, and prepaid debit cards/satellite TV
Effrayant.
lun. 17 oct. 2016 15:36:20 CEST -
-
link
- https://www.washingtonpost.com/news/the-intersect/wp/2016/08/19/98-personal-data-points-that-facebook-uses-to-target-ads-to-you/
vie-privée publicité bêtise
9. Ethnic affinity
...
20. Users in long-distance relationships
...
31. Conservatives and liberals
...
45. How much money user is likely to spend on next car
...
79. Users who are “heavy” buyers of beer, wine or spirits
...
82. Users who buy allergy medications, cough/cold medications, pain relief products, and over-the-counter meds
...
89. Users who are “receptive” to offers from companies offering online auto insurance, higher education or mortgages, and prepaid debit cards/satellite TV
Effrayant.
lun. 17 oct. 2016 15:36:20 CEST -
-
link
- https://www.washingtonpost.com/news/the-intersect/wp/2016/08/19/98-personal-data-points-that-facebook-uses-to-target-ads-to-you/
vie-privée publicité bêtise
How to measure smartphone power usage |
 Mesurer la consommation électrique d'un smartphone. Testé et approuvé.
Mesurer la consommation électrique d'un smartphone. Testé et approuvé.
lun. 17 oct. 2016 15:31:06 CEST -
-
link
- http://www.epanorama.net/newepa/2014/04/28/how-to-measure-smartphone-power-usage/
mesure
lun. 17 oct. 2016 15:31:06 CEST -
-
link
- http://www.epanorama.net/newepa/2014/04/28/how-to-measure-smartphone-power-usage/
mesure
Welcome! — Pygments
 Pygments, coloration syntaxique (export RTF possible, permettant de copier-coller le code formaté dans une présentation, par exemple).
Pygments, coloration syntaxique (export RTF possible, permettant de copier-coller le code formaté dans une présentation, par exemple).
lun. 17 oct. 2016 15:29:04 CEST -
-
link
- http://pygments.org/
python coloration
lun. 17 oct. 2016 15:29:04 CEST -
-
link
- http://pygments.org/
python coloration
xkcd: Automation
 C'est bien vu. Préférez toujours la réutilisation d'un code existant, une librairie ou un outil plutôt que vos propres codes (qui devront malheureusement être maintenus). Toutes proportions gardées, bien entendu.
C'est bien vu. Préférez toujours la réutilisation d'un code existant, une librairie ou un outil plutôt que vos propres codes (qui devront malheureusement être maintenus). Toutes proportions gardées, bien entendu.
lun. 17 oct. 2016 15:27:31 CEST -
-
link
- https://xkcd.com/1319/
humour
lun. 17 oct. 2016 15:27:31 CEST -
-
link
- https://xkcd.com/1319/
humour
Procedural Content Generation in Games | A textbook and an overview of current research
 La synthèse procédurale de contenu pour les jeux vidéos est un sujet qui m'intéresse beaucoup. J'en ai fait un tour d'horizon pour la fête de la science à l'INRIA (http://benjaminbillet.fr/wiki/doku.php?id=fete_de_la_science_2012) mais en voici un textbook beaucoup plus complet :)
La synthèse procédurale de contenu pour les jeux vidéos est un sujet qui m'intéresse beaucoup. J'en ai fait un tour d'horizon pour la fête de la science à l'INRIA (http://benjaminbillet.fr/wiki/doku.php?id=fete_de_la_science_2012) mais en voici un textbook beaucoup plus complet :)
1 Introduction
2 The search-based approach
3 Constructive generation methods for dungeons and levels
4 Fractals, noise and agents with applications to landscapes and textures
5 Grammars and L-systems with applications to vegetation and levels
6 Rules and mechanics
7 Planning with applications to quests and story
8 ASP with applications to mazes and levels
9 Representations for search-based methods
10 The experience-driven perspective
11 Mixed-initiative approaches
12 Evaluating content generators
On y retrouve de nombreux sujets abordés dans ma présentation, mais avec plus d'excellents chapitres sur la génération de règles, de gameplay, de scénarios et de quêtes.
lun. 17 oct. 2016 15:23:22 CEST -
-
link
- http://pcgbook.com/
pcg synthèse-procédurale
1 Introduction
2 The search-based approach
3 Constructive generation methods for dungeons and levels
4 Fractals, noise and agents with applications to landscapes and textures
5 Grammars and L-systems with applications to vegetation and levels
6 Rules and mechanics
7 Planning with applications to quests and story
8 ASP with applications to mazes and levels
9 Representations for search-based methods
10 The experience-driven perspective
11 Mixed-initiative approaches
12 Evaluating content generators
On y retrouve de nombreux sujets abordés dans ma présentation, mais avec plus d'excellents chapitres sur la génération de règles, de gameplay, de scénarios et de quêtes.
lun. 17 oct. 2016 15:23:22 CEST -
-
link
- http://pcgbook.com/
pcg synthèse-procédurale
7 techniques mathématiques
 1. La descente de gradient
1. La descente de gradient
2. Le kdtree
3. La décomposition en valeurs singulières
4. La dimension de Vapnik-chervonenkis
5. Distributed Stochastic Neighboor Embedding
6. Radial basis Kernel trick
7. Affinity Propagation Clustering
lun. 17 oct. 2016 15:16:59 CEST -
-
link
- https://li.st/l/f00d8e06-3e49-4a69-97eb-dc3729b808f5
mathématiques
2. Le kdtree
3. La décomposition en valeurs singulières
4. La dimension de Vapnik-chervonenkis
5. Distributed Stochastic Neighboor Embedding
6. Radial basis Kernel trick
7. Affinity Propagation Clustering
lun. 17 oct. 2016 15:16:59 CEST -
-
link
- https://li.st/l/f00d8e06-3e49-4a69-97eb-dc3729b808f5
mathématiques
Une introduction aux arbres de décision
 Résumé :
Résumé :
Les arbres de décision sont l’une des structures de données majeures de l’apprentissage statistique. Leur fonctionnement repose sur des heuristiques qui, tout en satisfaisant l’intuition, donnent des résultats remarquables en pratique (notamment lorsqu’ils sont utilisés en « forêts aléatoires »). Leur structure arborescente les rend également lisibles par un être humain, contrairement à d’autres approches où le prédicteur construit est une « boîte noire ».
L’introduction que nous proposons ici décrit les bases de leur fonctionnement tout en apportant quelques justifications théoriques. Nous aborderons aussi (brièvement) l’extension aux Random Forests. On supposera le lecteur familier avec le contexte général de l’apprentissage supervisé.1
lun. 17 oct. 2016 15:10:56 CEST -
-
link
- https://scaron.info/doc/intro-arbres-decision/
machine-learning mathématiques
Les arbres de décision sont l’une des structures de données majeures de l’apprentissage statistique. Leur fonctionnement repose sur des heuristiques qui, tout en satisfaisant l’intuition, donnent des résultats remarquables en pratique (notamment lorsqu’ils sont utilisés en « forêts aléatoires »). Leur structure arborescente les rend également lisibles par un être humain, contrairement à d’autres approches où le prédicteur construit est une « boîte noire ».
L’introduction que nous proposons ici décrit les bases de leur fonctionnement tout en apportant quelques justifications théoriques. Nous aborderons aussi (brièvement) l’extension aux Random Forests. On supposera le lecteur familier avec le contexte général de l’apprentissage supervisé.1
lun. 17 oct. 2016 15:10:56 CEST -
-
link
- https://scaron.info/doc/intro-arbres-decision/
machine-learning mathématiques
GitHub - dokan-dev/dokany: User mode file system library for windows with FUSE Wrapper
 Génial, un équivalent à FUSE (Filesystem in Userspace) pour Windows. Il s'agit d'une interface permettant d'écrire des systèmes de fichier "virtuels", c'est-à-dire ne nécessitant pas de modifier le noyau du système d'exploitation pour fonctionner.
Génial, un équivalent à FUSE (Filesystem in Userspace) pour Windows. Il s'agit d'une interface permettant d'écrire des systèmes de fichier "virtuels", c'est-à-dire ne nécessitant pas de modifier le noyau du système d'exploitation pour fonctionner.
C'est une fonctionnalité qui a toujours manqué à Windows.
jeu. 22 sept. 2016 14:29:10 CEST -
-
link
- https://github.com/dokan-dev/dokany
outil programmation système
C'est une fonctionnalité qui a toujours manqué à Windows.
jeu. 22 sept. 2016 14:29:10 CEST -
-
link
- https://github.com/dokan-dev/dokany
outil programmation système
Oh, shit, git!
 Une collection d'astuces pour rattraper les (petites) erreurs de manipulation avec git. Par exemple corriger le message d'un commit, amender un commit, etc.
Une collection d'astuces pour rattraper les (petites) erreurs de manipulation avec git. Par exemple corriger le message d'un commit, amender un commit, etc.
jeu. 22 sept. 2016 14:22:56 CEST -
-
link
- http://ohshitgit.com/
git outil
jeu. 22 sept. 2016 14:22:56 CEST -
-
link
- http://ohshitgit.com/
git outil
How Not To Sort By Average Rating
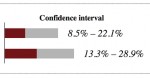 Une meilleure méthode pour la gestion des notations. Cette technique prend en compte à la fois la proportion de notes positives et la taille de l'échantillon.
Une meilleure méthode pour la gestion des notations. Cette technique prend en compte à la fois la proportion de notes positives et la taille de l'échantillon.
sam. 06 août 2016 15:08:43 CEST -
-
link
- http://www.evanmiller.org/how-not-to-sort-by-average-rating.html
mathématiques
sam. 06 août 2016 15:08:43 CEST -
-
link
- http://www.evanmiller.org/how-not-to-sort-by-average-rating.html
mathématiques
Elm – fun with L-System (Part 1) | theburningmonk.com
 Un L-Système ou système de Lindenmayer est une grammaire formelle permettant de décrire un ensemble de règles et de symboles qui modélisent un processus de croissance.
Un L-Système ou système de Lindenmayer est une grammaire formelle permettant de décrire un ensemble de règles et de symboles qui modélisent un processus de croissance.
Les symboles représentent l'état de l'être vivant à une itération X, tandis que les règles représentent la transformation des symboles en autres symboles (ou groupes de symboles). A partir de l'état X, les règles permettent de construire l'état X+1 et ainsi de suite jusqu'à obtenir une structure complexe.
J'ai traité le sujet des L-Systèmes lors de la fête de la science 2012 à l'INRIA. Voir ma présentation ici : http://benjaminbillet.fr/wiki/doku.php?id=fete_de_la_science_2012
Voir aussi : http://blog.rabidgremlin.com/2014/12/09/procedural-content-generation-l-systems/
sam. 06 août 2016 14:56:37 CEST -
-
link
- http://theburningmonk.com/2015/10/elm-fun-with-l-system-part-1/
synthèse-procédurale
Les symboles représentent l'état de l'être vivant à une itération X, tandis que les règles représentent la transformation des symboles en autres symboles (ou groupes de symboles). A partir de l'état X, les règles permettent de construire l'état X+1 et ainsi de suite jusqu'à obtenir une structure complexe.
J'ai traité le sujet des L-Systèmes lors de la fête de la science 2012 à l'INRIA. Voir ma présentation ici : http://benjaminbillet.fr/wiki/doku.php?id=fete_de_la_science_2012
Voir aussi : http://blog.rabidgremlin.com/2014/12/09/procedural-content-generation-l-systems/
sam. 06 août 2016 14:56:37 CEST -
-
link
- http://theburningmonk.com/2015/10/elm-fun-with-l-system-part-1/
synthèse-procédurale
Shadertoy BETA
 Un shader est un programme permettant de paramétrer une partie du pipeline de rendu réalisé par une carte graphique ou un moteur de rendu logiciel. Ces programmes sont exécutés directement par le GPU de la machine, étant donné que ces programmes effectuent de nombreuses opérations vectorielles pour lesquelles le GPU est très efficace.
Un shader est un programme permettant de paramétrer une partie du pipeline de rendu réalisé par une carte graphique ou un moteur de rendu logiciel. Ces programmes sont exécutés directement par le GPU de la machine, étant donné que ces programmes effectuent de nombreuses opérations vectorielles pour lesquelles le GPU est très efficace.
Il existe des shaders de plusieurs types, qui influent sur différentes étapes du pipeline, les plus connus étant les "vertex shaders" (qui influent sur la projection de l'espace 3D sur l'espace 2D) et les "pixel shaders" (qui influent sur les pixels).
Cet outil permet d'écrire des shaders en ligne et de les tester directement. Il y a des choses assez impressionnantes.
sam. 06 août 2016 14:42:48 CEST -
-
link
- https://www.shadertoy.com/
3d shader
Il existe des shaders de plusieurs types, qui influent sur différentes étapes du pipeline, les plus connus étant les "vertex shaders" (qui influent sur la projection de l'espace 3D sur l'espace 2D) et les "pixel shaders" (qui influent sur les pixels).
Cet outil permet d'écrire des shaders en ligne et de les tester directement. Il y a des choses assez impressionnantes.
sam. 06 août 2016 14:42:48 CEST -
-
link
- https://www.shadertoy.com/
3d shader
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.