Journal
 RSS Feed
RSS Feed Tag cloud
Tag cloud
Une introduction aux arbres de décision
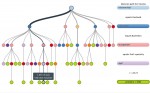 Résumé :
Résumé :
Les arbres de décision sont l’une des structures de données majeures de l’apprentissage statistique. Leur fonctionnement repose sur des heuristiques qui, tout en satisfaisant l’intuition, donnent des résultats remarquables en pratique (notamment lorsqu’ils sont utilisés en « forêts aléatoires »). Leur structure arborescente les rend également lisibles par un être humain, contrairement à d’autres approches où le prédicteur construit est une « boîte noire ».
L’introduction que nous proposons ici décrit les bases de leur fonctionnement tout en apportant quelques justifications théoriques. Nous aborderons aussi (brièvement) l’extension aux Random Forests. On supposera le lecteur familier avec le contexte général de l’apprentissage supervisé.1
 lun. 17 oct. 2016 15:10:56 CEST -
lun. 17 oct. 2016 15:10:56 CEST -
 -
link
- https://scaron.info/doc/intro-arbres-decision/
-
link
- https://scaron.info/doc/intro-arbres-decision/
 machine-learning mathématiques
machine-learning mathématiques
Les arbres de décision sont l’une des structures de données majeures de l’apprentissage statistique. Leur fonctionnement repose sur des heuristiques qui, tout en satisfaisant l’intuition, donnent des résultats remarquables en pratique (notamment lorsqu’ils sont utilisés en « forêts aléatoires »). Leur structure arborescente les rend également lisibles par un être humain, contrairement à d’autres approches où le prédicteur construit est une « boîte noire ».
L’introduction que nous proposons ici décrit les bases de leur fonctionnement tout en apportant quelques justifications théoriques. Nous aborderons aussi (brièvement) l’extension aux Random Forests. On supposera le lecteur familier avec le contexte général de l’apprentissage supervisé.1
lun. 17 oct. 2016 15:10:56 CEST -
-
link
- https://scaron.info/doc/intro-arbres-decision/
machine-learning mathématiques
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.