Journal
Ce journal contient 5 entrées.
 RSS Feed
RSS Feed Tag cloud
Tag cloud
Blog Stéphane Bortzmeyer: RFC 7616: HTTP Digest Access Authentication
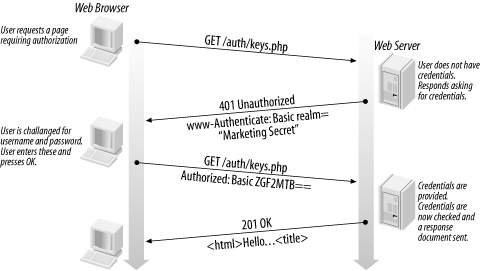 Moralité : peu importe que vous utilisiez le mécanisme d'identification/authentification Basic ou Digest, TLS est requis pour éviter (i) les attaques de l'homme du milieu, (ii) la transmission en clair du contenu autorisé.
Moralité : peu importe que vous utilisiez le mécanisme d'identification/authentification Basic ou Digest, TLS est requis pour éviter (i) les attaques de l'homme du milieu, (ii) la transmission en clair du contenu autorisé.
Qui plus est, ces mécanismes d'identification/authentification HTTP ne gérent pas d'état : il n'est pas possible pour le serveur de forcer l'utilisateur à se réauthentifier et il n'est pas non plus possible pour le client de se déconnecter (lire http://www.bortzmeyer.org/7235.html). En pratique, il vaut donc mieux privilégier un formulaire Web pour la saisie du mot de passe, puis un cookie/clé de session associée à chaque requête.
 sam. 06 août 2016 14:30:11 CEST -
sam. 06 août 2016 14:30:11 CEST -
 -
link
- http://www.bortzmeyer.org/7616.html
-
link
- http://www.bortzmeyer.org/7616.html
 sécurité http
sécurité http
Qui plus est, ces mécanismes d'identification/authentification HTTP ne gérent pas d'état : il n'est pas possible pour le serveur de forcer l'utilisateur à se réauthentifier et il n'est pas non plus possible pour le client de se déconnecter (lire http://www.bortzmeyer.org/7235.html). En pratique, il vaut donc mieux privilégier un formulaire Web pour la saisie du mot de passe, puis un cookie/clé de session associée à chaque requête.
sam. 06 août 2016 14:30:11 CEST -
-
link
- http://www.bortzmeyer.org/7616.html
sécurité http
Choosing an HTTP Status Code — Stop Making It Hard – Racksburg
 Choisir ses codes HTTP pour une API REST. Quelques trucs sont sans doute sujet à débat, mais c'est un point de départ intéressant.
Choisir ses codes HTTP pour une API REST. Quelques trucs sont sans doute sujet à débat, mais c'est un point de départ intéressant.
jeu. 12 mai 2016 09:25:34 CEST -
-
link
- http://racksburg.com/choosing-an-http-status-code/
rest http
jeu. 12 mai 2016 09:25:34 CEST -
-
link
- http://racksburg.com/choosing-an-http-status-code/
rest http
IP, TCP, and HTTP
 Pour ceux qui chercheraient à démarrer sur des sujets aussi vastes que les protocoles IP (version 4), TCP et HTTP, je trouve cette page assez complète et plutôt claire. Certes, il y aurait encore beaucoup à ajouter, mais c'est un excellent début.
Pour ceux qui chercheraient à démarrer sur des sujets aussi vastes que les protocoles IP (version 4), TCP et HTTP, je trouve cette page assez complète et plutôt claire. Certes, il y aurait encore beaucoup à ajouter, mais c'est un excellent début.
jeu. 10 juil. 2014 10:30:41 CEST -
-
link
- http://www.objc.io/issue-10/ip-tcp-http.html
réseau tcp/ip http
jeu. 10 juil. 2014 10:30:41 CEST -
-
link
- http://www.objc.io/issue-10/ip-tcp-http.html
réseau tcp/ip http
Blog Stéphane Bortzmeyer: La norme HTTP 1.1, nouvelle rédaction
 La RFC2616 (HTTP 1.1) a été remplacée par huit nouvelles RFC couvrant différents aspects du protocole HTTP. Plus claires, mieux structurées, plus rigoureuses et moins ambigües, ces nouvelles RFC sont le fruit du groupe de travail httpbis de l'IETF (voir le lien original et les RFC en questions pour plus de détails).
La RFC2616 (HTTP 1.1) a été remplacée par huit nouvelles RFC couvrant différents aspects du protocole HTTP. Plus claires, mieux structurées, plus rigoureuses et moins ambigües, ces nouvelles RFC sont le fruit du groupe de travail httpbis de l'IETF (voir le lien original et les RFC en questions pour plus de détails).
RFC7230 : http://www.rfc-editor.org/rfc/rfc7230.txt
RFC7231 : http://www.rfc-editor.org/rfc/rfc7231.txt
RFC7232 : http://www.rfc-editor.org/rfc/rfc7232.txt
RFC7233 : http://www.rfc-editor.org/rfc/rfc7233.txt
RFC7234 : http://www.rfc-editor.org/rfc/rfc7234.txt
RFC7235 : http://www.rfc-editor.org/rfc/rfc7235.txt
RFC7236 : http://www.rfc-editor.org/rfc/rfc7236.txt
RFC7237 : http://www.rfc-editor.org/rfc/rfc7237.txt
lun. 16 juin 2014 11:51:57 CEST -
-
link
- http://www.bortzmeyer.org/http-11-reecrit.html
rfc http web
RFC7230 : http://www.rfc-editor.org/rfc/rfc7230.txt
RFC7231 : http://www.rfc-editor.org/rfc/rfc7231.txt
RFC7232 : http://www.rfc-editor.org/rfc/rfc7232.txt
RFC7233 : http://www.rfc-editor.org/rfc/rfc7233.txt
RFC7234 : http://www.rfc-editor.org/rfc/rfc7234.txt
RFC7235 : http://www.rfc-editor.org/rfc/rfc7235.txt
RFC7236 : http://www.rfc-editor.org/rfc/rfc7236.txt
RFC7237 : http://www.rfc-editor.org/rfc/rfc7237.txt
lun. 16 juin 2014 11:51:57 CEST -
-
link
- http://www.bortzmeyer.org/http-11-reecrit.html
rfc http web
Le Hollandais Volant : Apprenez vos codes HTTP, bordel !
 En fait, le 302 Found est parfaitement standard, mais il faut se référer à la bonne spécification (HTTP 1.1 et pas HTTP 1.0).
En fait, le 302 Found est parfaitement standard, mais il faut se référer à la bonne spécification (HTTP 1.1 et pas HTTP 1.0).
A l'époque de HTTP 1.0, les codes 303 et 307 n'existaient pas, comme on peut le lire dans la spécification http://www.w3.org/Protocols/HTTP/1.0/spec.html#Code3xx qui ne mentionne que 300, 301, 302 et 304. Et, en effet, le 302 de HTTP 1.0 s'appelait bien "Moved Temporarily".
Sauf que le code 302 de HTTP 1.0 a été mal implémenté par plusieurs fabricants : les browsers changeaient le type de la requête lors de la redirection (un POST devenait un GET, par exemple).
Ainsi, pour lever l'ambiguité entre les comportements, HTTP 1.1 a introduit les codes 303 et 307 qui sont en fait des codes 302, mais avec un comportement défini (303 change le type de la requête en GET et 307 préserve le type de la requête).
Le code 302 en HTTP 1.1 a alors été renommé Found, et n'apporte pas de garantie sur le comportement. Il sert surtout pour la rétrocompatibilité avec les mauvaises implémentations.
La liste des codes de statut en HTTP 1.1 : http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.1.1
Le détail de la spécification sur 302 Found en HTTP 1.1 : http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3.3
Aujourd'hui, tous les serveurs et les browsers supportent HTTP 1.1, et heureusement car cette spécification date de 1997 (l'IETF travaille actuellement sur HTTP 2.0). HTTP 1.1 est assez différente de HTTP 1.0 à plusieurs points de vue: nouveaux headers/codes, négociation des contenus (les headers Accept-*), le pipelining par défaut (Connection: keep-alive), le transfert par chunks (Transfer-Encoding: chunked), etc.
==== EDIT ====
Le hollandais volant a dit : "Toujours est-il que le code 302 peut renvoyer soit "Found" soit "Moved Temporarily" selon l'humeur du webmaster :/"
Exactement ! Et c'est parfaitement autorisé par la spécification :)
http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.1
En fait, la "status line" d'une réponse HTTP est composée de deux parties, un "status code" (404, 200, etc.) et une "reason phrase" (OK, Not Found, etc.) qui décrit brièvement le status code.
Il est précisé que cette reason phrase est destinée aux êtres humains et pas aux machines, qui elles se contenteront du status code. Il y a d'ailleurs compatibilité descendante entre les codes : en terme de comportement, le code 302 signifie pareil en HTTP 1.1 qu'en HTTP 1.0.
Les reason phrases sont parfaitement optionnelles, il est autorisé de ne donner que le status code, et les reason phrases mentionnées dans la spécification sont des recommandations : le serveur a le droit d'y écrire ce qu'il veut. Rien n'empêche, par exemple, d'avoir une réponse du type "500 Internal Server Error [ the server has just exploded ]" ou "403 Nope" :p
Quand on parse des réponses HTTP, il est préférable d'interpréter les codes et d'ignorer tout simplement les reason phrases. Si par contre on génère une réponse, il suffit de rester cohérent avec la version d'HTTP : si c'est HTTP 1.1 alors on a 302 Found, si c'est HTTP 1.0 alors on a 302 Moved Temporarily.
Un webmaster indélicat peut, en effet, inverser les deux, mais c'est autorisé par la spécification (même si c'est moche, je te l'accordes <<).
Qui plus est, dans une requête ou une réponse, la version d'HTTP est toujours spécifiée.
Requête : GET /page.html HTTP/1.1
Réponse : HTTP/1.1 200 OK
ven. 02 mai 2014 12:06:47 CEST -
-
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140501231207
http web
A l'époque de HTTP 1.0, les codes 303 et 307 n'existaient pas, comme on peut le lire dans la spécification http://www.w3.org/Protocols/HTTP/1.0/spec.html#Code3xx qui ne mentionne que 300, 301, 302 et 304. Et, en effet, le 302 de HTTP 1.0 s'appelait bien "Moved Temporarily".
Sauf que le code 302 de HTTP 1.0 a été mal implémenté par plusieurs fabricants : les browsers changeaient le type de la requête lors de la redirection (un POST devenait un GET, par exemple).
Ainsi, pour lever l'ambiguité entre les comportements, HTTP 1.1 a introduit les codes 303 et 307 qui sont en fait des codes 302, mais avec un comportement défini (303 change le type de la requête en GET et 307 préserve le type de la requête).
Le code 302 en HTTP 1.1 a alors été renommé Found, et n'apporte pas de garantie sur le comportement. Il sert surtout pour la rétrocompatibilité avec les mauvaises implémentations.
La liste des codes de statut en HTTP 1.1 : http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.1.1
Le détail de la spécification sur 302 Found en HTTP 1.1 : http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3.3
Aujourd'hui, tous les serveurs et les browsers supportent HTTP 1.1, et heureusement car cette spécification date de 1997 (l'IETF travaille actuellement sur HTTP 2.0). HTTP 1.1 est assez différente de HTTP 1.0 à plusieurs points de vue: nouveaux headers/codes, négociation des contenus (les headers Accept-*), le pipelining par défaut (Connection: keep-alive), le transfert par chunks (Transfer-Encoding: chunked), etc.
==== EDIT ====
Le hollandais volant a dit : "Toujours est-il que le code 302 peut renvoyer soit "Found" soit "Moved Temporarily" selon l'humeur du webmaster :/"
Exactement ! Et c'est parfaitement autorisé par la spécification :)
http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.1
En fait, la "status line" d'une réponse HTTP est composée de deux parties, un "status code" (404, 200, etc.) et une "reason phrase" (OK, Not Found, etc.) qui décrit brièvement le status code.
Il est précisé que cette reason phrase est destinée aux êtres humains et pas aux machines, qui elles se contenteront du status code. Il y a d'ailleurs compatibilité descendante entre les codes : en terme de comportement, le code 302 signifie pareil en HTTP 1.1 qu'en HTTP 1.0.
Les reason phrases sont parfaitement optionnelles, il est autorisé de ne donner que le status code, et les reason phrases mentionnées dans la spécification sont des recommandations : le serveur a le droit d'y écrire ce qu'il veut. Rien n'empêche, par exemple, d'avoir une réponse du type "500 Internal Server Error [ the server has just exploded ]" ou "403 Nope" :p
Quand on parse des réponses HTTP, il est préférable d'interpréter les codes et d'ignorer tout simplement les reason phrases. Si par contre on génère une réponse, il suffit de rester cohérent avec la version d'HTTP : si c'est HTTP 1.1 alors on a 302 Found, si c'est HTTP 1.0 alors on a 302 Moved Temporarily.
Un webmaster indélicat peut, en effet, inverser les deux, mais c'est autorisé par la spécification (même si c'est moche, je te l'accordes <<).
Qui plus est, dans une requête ou une réponse, la version d'HTTP est toujours spécifiée.
Requête : GET /page.html HTTP/1.1
Réponse : HTTP/1.1 200 OK
ven. 02 mai 2014 12:06:47 CEST -
-
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140501231207
http web
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.