Journal
Ce journal contient 14 entrées.
 RSS Feed
RSS Feed Tag cloud
Tag cloud
Responsive pixel art showcase
 Un prototype de pixel-art responsive. C'est assez bluffant : ce n'est pas juste une image qui se redimensionne mais un ensemble de patterns qui peuvent se répéter (voire une image qui mute complètement en fonction de la taille et du ratio).
Un prototype de pixel-art responsive. C'est assez bluffant : ce n'est pas juste une image qui se redimensionne mais un ensemble de patterns qui peuvent se répéter (voire une image qui mute complètement en fonction de la taille et du ratio).
 dim. 03 avril 2016 12:48:25 CEST -
dim. 03 avril 2016 12:48:25 CEST -
 -
link
- http://essenmitsosse.de/pixel/?showcase=true&slide=2
-
link
- http://essenmitsosse.de/pixel/?showcase=true&slide=2
 web
web
dim. 03 avril 2016 12:48:25 CEST -
-
link
- http://essenmitsosse.de/pixel/?showcase=true&slide=2
web
Blog Stéphane Bortzmeyer: La norme HTTP 1.1, nouvelle rédaction
 La RFC2616 (HTTP 1.1) a été remplacée par huit nouvelles RFC couvrant différents aspects du protocole HTTP. Plus claires, mieux structurées, plus rigoureuses et moins ambigües, ces nouvelles RFC sont le fruit du groupe de travail httpbis de l'IETF (voir le lien original et les RFC en questions pour plus de détails).
La RFC2616 (HTTP 1.1) a été remplacée par huit nouvelles RFC couvrant différents aspects du protocole HTTP. Plus claires, mieux structurées, plus rigoureuses et moins ambigües, ces nouvelles RFC sont le fruit du groupe de travail httpbis de l'IETF (voir le lien original et les RFC en questions pour plus de détails).
RFC7230 : http://www.rfc-editor.org/rfc/rfc7230.txt
RFC7231 : http://www.rfc-editor.org/rfc/rfc7231.txt
RFC7232 : http://www.rfc-editor.org/rfc/rfc7232.txt
RFC7233 : http://www.rfc-editor.org/rfc/rfc7233.txt
RFC7234 : http://www.rfc-editor.org/rfc/rfc7234.txt
RFC7235 : http://www.rfc-editor.org/rfc/rfc7235.txt
RFC7236 : http://www.rfc-editor.org/rfc/rfc7236.txt
RFC7237 : http://www.rfc-editor.org/rfc/rfc7237.txt
lun. 16 juin 2014 11:51:57 CEST -
-
link
- http://www.bortzmeyer.org/http-11-reecrit.html
rfc http web
RFC7230 : http://www.rfc-editor.org/rfc/rfc7230.txt
RFC7231 : http://www.rfc-editor.org/rfc/rfc7231.txt
RFC7232 : http://www.rfc-editor.org/rfc/rfc7232.txt
RFC7233 : http://www.rfc-editor.org/rfc/rfc7233.txt
RFC7234 : http://www.rfc-editor.org/rfc/rfc7234.txt
RFC7235 : http://www.rfc-editor.org/rfc/rfc7235.txt
RFC7236 : http://www.rfc-editor.org/rfc/rfc7236.txt
RFC7237 : http://www.rfc-editor.org/rfc/rfc7237.txt
lun. 16 juin 2014 11:51:57 CEST -
-
link
- http://www.bortzmeyer.org/http-11-reecrit.html
rfc http web
Le Hollandais Volant : Apprenez vos codes HTTP, bordel !
 En fait, le 302 Found est parfaitement standard, mais il faut se référer à la bonne spécification (HTTP 1.1 et pas HTTP 1.0).
En fait, le 302 Found est parfaitement standard, mais il faut se référer à la bonne spécification (HTTP 1.1 et pas HTTP 1.0).
A l'époque de HTTP 1.0, les codes 303 et 307 n'existaient pas, comme on peut le lire dans la spécification http://www.w3.org/Protocols/HTTP/1.0/spec.html#Code3xx qui ne mentionne que 300, 301, 302 et 304. Et, en effet, le 302 de HTTP 1.0 s'appelait bien "Moved Temporarily".
Sauf que le code 302 de HTTP 1.0 a été mal implémenté par plusieurs fabricants : les browsers changeaient le type de la requête lors de la redirection (un POST devenait un GET, par exemple).
Ainsi, pour lever l'ambiguité entre les comportements, HTTP 1.1 a introduit les codes 303 et 307 qui sont en fait des codes 302, mais avec un comportement défini (303 change le type de la requête en GET et 307 préserve le type de la requête).
Le code 302 en HTTP 1.1 a alors été renommé Found, et n'apporte pas de garantie sur le comportement. Il sert surtout pour la rétrocompatibilité avec les mauvaises implémentations.
La liste des codes de statut en HTTP 1.1 : http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.1.1
Le détail de la spécification sur 302 Found en HTTP 1.1 : http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3.3
Aujourd'hui, tous les serveurs et les browsers supportent HTTP 1.1, et heureusement car cette spécification date de 1997 (l'IETF travaille actuellement sur HTTP 2.0). HTTP 1.1 est assez différente de HTTP 1.0 à plusieurs points de vue: nouveaux headers/codes, négociation des contenus (les headers Accept-*), le pipelining par défaut (Connection: keep-alive), le transfert par chunks (Transfer-Encoding: chunked), etc.
==== EDIT ====
Le hollandais volant a dit : "Toujours est-il que le code 302 peut renvoyer soit "Found" soit "Moved Temporarily" selon l'humeur du webmaster :/"
Exactement ! Et c'est parfaitement autorisé par la spécification :)
http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.1
En fait, la "status line" d'une réponse HTTP est composée de deux parties, un "status code" (404, 200, etc.) et une "reason phrase" (OK, Not Found, etc.) qui décrit brièvement le status code.
Il est précisé que cette reason phrase est destinée aux êtres humains et pas aux machines, qui elles se contenteront du status code. Il y a d'ailleurs compatibilité descendante entre les codes : en terme de comportement, le code 302 signifie pareil en HTTP 1.1 qu'en HTTP 1.0.
Les reason phrases sont parfaitement optionnelles, il est autorisé de ne donner que le status code, et les reason phrases mentionnées dans la spécification sont des recommandations : le serveur a le droit d'y écrire ce qu'il veut. Rien n'empêche, par exemple, d'avoir une réponse du type "500 Internal Server Error [ the server has just exploded ]" ou "403 Nope" :p
Quand on parse des réponses HTTP, il est préférable d'interpréter les codes et d'ignorer tout simplement les reason phrases. Si par contre on génère une réponse, il suffit de rester cohérent avec la version d'HTTP : si c'est HTTP 1.1 alors on a 302 Found, si c'est HTTP 1.0 alors on a 302 Moved Temporarily.
Un webmaster indélicat peut, en effet, inverser les deux, mais c'est autorisé par la spécification (même si c'est moche, je te l'accordes <<).
Qui plus est, dans une requête ou une réponse, la version d'HTTP est toujours spécifiée.
Requête : GET /page.html HTTP/1.1
Réponse : HTTP/1.1 200 OK
ven. 02 mai 2014 12:06:47 CEST -
-
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140501231207
http web
A l'époque de HTTP 1.0, les codes 303 et 307 n'existaient pas, comme on peut le lire dans la spécification http://www.w3.org/Protocols/HTTP/1.0/spec.html#Code3xx qui ne mentionne que 300, 301, 302 et 304. Et, en effet, le 302 de HTTP 1.0 s'appelait bien "Moved Temporarily".
Sauf que le code 302 de HTTP 1.0 a été mal implémenté par plusieurs fabricants : les browsers changeaient le type de la requête lors de la redirection (un POST devenait un GET, par exemple).
Ainsi, pour lever l'ambiguité entre les comportements, HTTP 1.1 a introduit les codes 303 et 307 qui sont en fait des codes 302, mais avec un comportement défini (303 change le type de la requête en GET et 307 préserve le type de la requête).
Le code 302 en HTTP 1.1 a alors été renommé Found, et n'apporte pas de garantie sur le comportement. Il sert surtout pour la rétrocompatibilité avec les mauvaises implémentations.
La liste des codes de statut en HTTP 1.1 : http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.1.1
Le détail de la spécification sur 302 Found en HTTP 1.1 : http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html#sec10.3.3
Aujourd'hui, tous les serveurs et les browsers supportent HTTP 1.1, et heureusement car cette spécification date de 1997 (l'IETF travaille actuellement sur HTTP 2.0). HTTP 1.1 est assez différente de HTTP 1.0 à plusieurs points de vue: nouveaux headers/codes, négociation des contenus (les headers Accept-*), le pipelining par défaut (Connection: keep-alive), le transfert par chunks (Transfer-Encoding: chunked), etc.
==== EDIT ====
Le hollandais volant a dit : "Toujours est-il que le code 302 peut renvoyer soit "Found" soit "Moved Temporarily" selon l'humeur du webmaster :/"
Exactement ! Et c'est parfaitement autorisé par la spécification :)
http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html#sec6.1
En fait, la "status line" d'une réponse HTTP est composée de deux parties, un "status code" (404, 200, etc.) et une "reason phrase" (OK, Not Found, etc.) qui décrit brièvement le status code.
Il est précisé que cette reason phrase est destinée aux êtres humains et pas aux machines, qui elles se contenteront du status code. Il y a d'ailleurs compatibilité descendante entre les codes : en terme de comportement, le code 302 signifie pareil en HTTP 1.1 qu'en HTTP 1.0.
Les reason phrases sont parfaitement optionnelles, il est autorisé de ne donner que le status code, et les reason phrases mentionnées dans la spécification sont des recommandations : le serveur a le droit d'y écrire ce qu'il veut. Rien n'empêche, par exemple, d'avoir une réponse du type "500 Internal Server Error [ the server has just exploded ]" ou "403 Nope" :p
Quand on parse des réponses HTTP, il est préférable d'interpréter les codes et d'ignorer tout simplement les reason phrases. Si par contre on génère une réponse, il suffit de rester cohérent avec la version d'HTTP : si c'est HTTP 1.1 alors on a 302 Found, si c'est HTTP 1.0 alors on a 302 Moved Temporarily.
Un webmaster indélicat peut, en effet, inverser les deux, mais c'est autorisé par la spécification (même si c'est moche, je te l'accordes <<).
Qui plus est, dans une requête ou une réponse, la version d'HTTP est toujours spécifiée.
Requête : GET /page.html HTTP/1.1
Réponse : HTTP/1.1 200 OK
ven. 02 mai 2014 12:06:47 CEST -
-
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140501231207
http web
HTML5 Form Validation
Description des attributs de validation de formulaire en HTML5 (required, pattern, etc.).
Comme le précise l'auteur, c'est pratique pour donner à l'utilisateur un feedback immédiat (pas de requête inutile, donc rapide) mais cela n'épargne en aucun cas la vérification des données côté serveur.
Une requête peut être forgée très facilement, et les données transmises par un utilisateur doivent toujours être considérées par le serveur comme potentiellement malveillantes.
Il serait d'ailleurs pratique d'avoir un outil qui génére automatiquement les vérifications serveur à partir du formulaire.
mer. 05 mars 2014 13:26:08 CET -
-
link
- http://www.sitepoint.com/html5-form-validation/
web html5 sécurité
Comme le précise l'auteur, c'est pratique pour donner à l'utilisateur un feedback immédiat (pas de requête inutile, donc rapide) mais cela n'épargne en aucun cas la vérification des données côté serveur.
Une requête peut être forgée très facilement, et les données transmises par un utilisateur doivent toujours être considérées par le serveur comme potentiellement malveillantes.
Il serait d'ailleurs pratique d'avoir un outil qui génére automatiquement les vérifications serveur à partir du formulaire.
mer. 05 mars 2014 13:26:08 CET -
-
link
- http://www.sitepoint.com/html5-form-validation/
web html5 sécurité
How browsers work
 Pour ceux qui se sont toujours demandés comment fonctionnent les navigateurs (notamment leur moteur de rendu). C'est vraiment un super travail de documentation et de vulgarisation.
Pour ceux qui se sont toujours demandés comment fonctionnent les navigateurs (notamment leur moteur de rendu). C'est vraiment un super travail de documentation et de vulgarisation.
lun. 17 févr. 2014 18:11:41 CET -
-
link
- http://taligarsiel.com/Projects/howbrowserswork1.htm
web navigateur
lun. 17 févr. 2014 18:11:41 CET -
-
link
- http://taligarsiel.com/Projects/howbrowserswork1.htm
web navigateur
Web Developer Checklist
Une checklist bien conçue pour les développeurs web qui conçoivent un nouveau site. Quelques choix sont discutables, notamment l'intégration sur les réseaux sociaux.
lun. 20 janv. 2014 22:11:50 CET -
-
link
- http://webdevchecklist.com/
web
lun. 20 janv. 2014 22:11:50 CET -
-
link
- http://webdevchecklist.com/
web
Mémo autohébergement - Phyks.me
 Un mémo très complet sur l'auto-hébergement.
Un mémo très complet sur l'auto-hébergement.
ven. 03 janv. 2014 17:05:23 CET -
-
link
- http://phyks.me/autohebergement.html
linux réseau web
ven. 03 janv. 2014 17:05:23 CET -
-
link
- http://phyks.me/autohebergement.html
linux réseau web
The Java EE 7 Tutorial:Java API for WebSocket
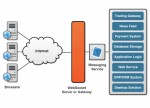 Les WebSocket (RFC 6455) sont des canaux bidirectionnels ouverts entre un navigateur et un serveur web en réutilisant la socket TCP d'une connexion HTTP.
Les WebSocket (RFC 6455) sont des canaux bidirectionnels ouverts entre un navigateur et un serveur web en réutilisant la socket TCP d'une connexion HTTP.
En pratique cela permet de simplifier l'écriture des applications Webs qui nécessitent de récupérer des évènements depuis un serveur.
Cela permet notamment de se passer des techniques de polling jusqu'alors massivement utilisées.
A noter qu'il ne faut pas confondre les WebSocket et WebRTC, qui désigne un ensemble de protocoles et d'API permettant à des navigateurs de communiquer en pair-à-pair. WebRTC est encore cependant à l'état de brouillon au W3C et à l'IETF même si Chrome, Firefox et Opera ont déjà intégrés des implémentations.
lun. 16 déc. 2013 10:45:24 CET -
-
link
- http://docs.oracle.com/javaee/7/tutorial/doc/websocket.htm
java websocket web
En pratique cela permet de simplifier l'écriture des applications Webs qui nécessitent de récupérer des évènements depuis un serveur.
Cela permet notamment de se passer des techniques de polling jusqu'alors massivement utilisées.
A noter qu'il ne faut pas confondre les WebSocket et WebRTC, qui désigne un ensemble de protocoles et d'API permettant à des navigateurs de communiquer en pair-à-pair. WebRTC est encore cependant à l'état de brouillon au W3C et à l'IETF même si Chrome, Firefox et Opera ont déjà intégrés des implémentations.
lun. 16 déc. 2013 10:45:24 CET -
-
link
- http://docs.oracle.com/javaee/7/tutorial/doc/websocket.htm
java websocket web
audreyr/favicon-cheat-sheet · GitHub
Mais quel bazar juste pour afficher une favicon, c'en est ridicule...
ven. 20 sept. 2013 15:01:50 CEST -
-
link
- https://github.com/audreyr/favicon-cheat-sheet
web
ven. 20 sept. 2013 15:01:50 CEST -
-
link
- https://github.com/audreyr/favicon-cheat-sheet
web
D3.js - Data-Driven Documents
D3.js (Data-Driven Documents) est une bibliothèque graphique JavaScript qui permet d'afficher des données sous forme graphique. C'est une librairie très populaire et très simple d'utilisation, à consommer sans modération.
jeu. 29 août 2013 17:13:35 CEST -
-
link
- http://d3js.org/
javascript web
jeu. 29 août 2013 17:13:35 CEST -
-
link
- http://d3js.org/
javascript web
HTML5 input types explained
 Une liste des nouveaux input types disponibles en HTML5 et leur rendu.
Une liste des nouveaux input types disponibles en HTML5 et leur rendu.
EDIT : voir aussi http://katzki.de/journal/html5-input-types-explained/
sam. 08 juin 2013 15:54:05 CEST -
-
link
- http://sixrevisions.com/html5/new-html5-form-input-types/
html5 web
EDIT : voir aussi http://katzki.de/journal/html5-input-types-explained/
sam. 08 juin 2013 15:54:05 CEST -
-
link
- http://sixrevisions.com/html5/new-html5-form-input-types/
html5 web
Emotion Markup Language (EmotionML)
Dans la lignée de http://benjaminbillet.fr/news/?link=d5gwd et http://benjaminbillet.fr/news/?link=d5gwe voilà le format de description d'émotion imaginé par le W3C. Par contre, on dirait que ce n'est pas une blague et que ce format est destiné à l'informatique orientée émotion, ou informatique affective (affective computing).
http://fr.wikipedia.org/wiki/Informatique_affective
Fallait oser <<
jeu. 10 janv. 2013 21:45:29 CET -
-
link
- http://www.w3.org/TR/2009/WD-emotionml-20091029/
w3c langage web
http://fr.wikipedia.org/wiki/Informatique_affective
Fallait oser <<
jeu. 10 janv. 2013 21:45:29 CET -
-
link
- http://www.w3.org/TR/2009/WD-emotionml-20091029/
w3c langage web
lab.goetter.fr
Diverses expérimentations en HTML5/CSS. Plein de petites choses intéressantes.
jeu. 27 déc. 2012 18:16:00 CET -
-
link
- http://lab.goetter.fr
html5 css3 web
jeu. 27 déc. 2012 18:16:00 CET -
-
link
- http://lab.goetter.fr
html5 css3 web
Search Engine-Friendly URLs - SitePoint
Comment faire de "jolies" URLs sans utiliser mod_rewrite.
sam. 09 juin 2012 09:42:52 CEST -
-
link
- http://www.sitepoint.com/search-engine-friendly-urls/
web
sam. 09 juin 2012 09:42:52 CEST -
-
link
- http://www.sitepoint.com/search-engine-friendly-urls/
web
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.