Journal
Ce journal contient 16 entrées.
 RSS Feed
RSS Feed Tag cloud
Tag cloud
DeepMind AlphaGo vs Lee Sedol: AlphaGo 4 – Lee Sedol 1
 J'étais complètement passé à côté de ça. Beaucoup de spécialistes pensaient qu'une machine capable de battre les humains au Go était impossible, car le nombre de possibilités à explorer est plus grand que pour les échecs.
J'étais complètement passé à côté de ça. Beaucoup de spécialistes pensaient qu'une machine capable de battre les humains au Go était impossible, car le nombre de possibilités à explorer est plus grand que pour les échecs.
C'est une (petite) victoire pour moi, car j'avais anticipé cette possibilité dès que je m'étais intéressé aux techniques utilisées pour les jeux d'échecs. Concrètement, le Go n'est pas différent des échecs : il se résout par une exploration systématique. Bien entendu, le nombre de possibilité est très grand, mais il aura suffit de limiter l'exploration systématique aux solutions les plus prometteuses, grâce à des techniques d'apprentissage artificiel.
Les algorithmes mis en œuvre dans AlphaGo sont très anciens (plus de 20 ans) et il apparaît que le seul élément qui manquait jusqu'à lors était un investissement massif de temps et d'argent (ici Google) pour entraîner ces algorithmes avec des dizaines de milliers de parties. Ce n'est donc qu'un hasard du calendrier si c'est aujourd'hui qu'une IA remporte une victoire (écrasante il faut bien le dire) au jeu de Go.
De la même façon, il est possible d'affirmer, sans trop de risques, que TOUS les jeux à exploration systématique peuvent être attaqués avec le même type d'algorithmes.
Bref : Computer science, ruining everything since 1960 :)
 lun. 09 mai 2016 17:35:28 CEST -
lun. 09 mai 2016 17:35:28 CEST -
 -
link
- https://gogameguru.com/tag/deepmind-alphago-lee-sedol/
-
link
- https://gogameguru.com/tag/deepmind-alphago-lee-sedol/
 informatique machine-learning
informatique machine-learning
C'est une (petite) victoire pour moi, car j'avais anticipé cette possibilité dès que je m'étais intéressé aux techniques utilisées pour les jeux d'échecs. Concrètement, le Go n'est pas différent des échecs : il se résout par une exploration systématique. Bien entendu, le nombre de possibilité est très grand, mais il aura suffit de limiter l'exploration systématique aux solutions les plus prometteuses, grâce à des techniques d'apprentissage artificiel.
Les algorithmes mis en œuvre dans AlphaGo sont très anciens (plus de 20 ans) et il apparaît que le seul élément qui manquait jusqu'à lors était un investissement massif de temps et d'argent (ici Google) pour entraîner ces algorithmes avec des dizaines de milliers de parties. Ce n'est donc qu'un hasard du calendrier si c'est aujourd'hui qu'une IA remporte une victoire (écrasante il faut bien le dire) au jeu de Go.
De la même façon, il est possible d'affirmer, sans trop de risques, que TOUS les jeux à exploration systématique peuvent être attaqués avec le même type d'algorithmes.
Bref : Computer science, ruining everything since 1960 :)
lun. 09 mai 2016 17:35:28 CEST -
-
link
- https://gogameguru.com/tag/deepmind-alphago-lee-sedol/
informatique machine-learning
Voici le résultat d'une image sauvegardée 500 fois
 Intéressante expérience où une image est sauvegardée de multiple fois en utilisant un format d'image destructif. Je suis assez surpris de voir le WEBP à ce point dégrader l'image.
Intéressante expérience où une image est sauvegardée de multiple fois en utilisant un format d'image destructif. Je suis assez surpris de voir le WEBP à ce point dégrader l'image.
sam. 16 avril 2016 09:05:28 CEST -
-
link
- http://www.lesnumeriques.com/appareil-photo-numerique/voici-resultat-image-sauvegardee-500-fois-n51275.html
image format
sam. 16 avril 2016 09:05:28 CEST -
-
link
- http://www.lesnumeriques.com/appareil-photo-numerique/voici-resultat-image-sauvegardee-500-fois-n51275.html
image format
Identifying Image Format from the First Few Bytes
 Une heuristique simple pour identifier un type d'image à partir des premiers octets. L'algorithme donné est écrit en C++ mais peut s'adapter facilement à d'autres langages.
Une heuristique simple pour identifier un type d'image à partir des premiers octets. L'algorithme donné est écrit en C++ mais peut s'adapter facilement à d'autres langages.
.jpg: FF D8 FF
.png: 89 50 4E 47 0D 0A 1A 0A
.gif: GIF87a ou GIF89a
.tiff: 49 49 2A 00 ou 4D 4D 00 2A
.bmp: BM
.webp: RIFF ???? WEBP
.ico: 00 00 01 00 ou 00 00 02 00 (cursor files)
ven. 08 avril 2016 14:55:17 CEST -
-
link
- https://oroboro.com/image-format-magic-bytes/
format image
.jpg: FF D8 FF
.png: 89 50 4E 47 0D 0A 1A 0A
.gif: GIF87a ou GIF89a
.tiff: 49 49 2A 00 ou 4D 4D 00 2A
.bmp: BM
.webp: RIFF ???? WEBP
.ico: 00 00 01 00 ou 00 00 02 00 (cursor files)
ven. 08 avril 2016 14:55:17 CEST -
-
link
- https://oroboro.com/image-format-magic-bytes/
format image
3 years of work
 C'est quoi une thèse ? 3 ans de travail et 180 tableaux blancs résumés en 11 secondes :')
C'est quoi une thèse ? 3 ans de travail et 180 tableaux blancs résumés en 11 secondes :')
http://benjaminbillet.fr/media/3yearsofwork.mp4
dim. 06 sept. 2015 20:48:17 CEST -
-
link
- http://benjaminbillet.fr/media/3yearsofwork.mp4
informatique stream-processing recherche
http://benjaminbillet.fr/media/3yearsofwork.mp4
dim. 06 sept. 2015 20:48:17 CEST -
-
link
- http://benjaminbillet.fr/media/3yearsofwork.mp4
informatique stream-processing recherche
/dev/log - Blog technique de Benjamin Billet
 J'inaugure une nouvelle partie pour le site : un blog qui me servira à prendre des notes sur mes projets personnels.
J'inaugure une nouvelle partie pour le site : un blog qui me servira à prendre des notes sur mes projets personnels.
Il m'arrive assez régulièrement de lancer des micro-projets sur des thématiques diverses et d'en profiter pour tester des technologies. Pour garder une trace des problèmes rencontrés et des méthodes de résolution, un moteur de blog me permettra de prendre des notes organisées par projets (catégories), ce de manière plus efficace que sur mon journal de liens.
J'inaugure le blog avec le petit projet sur lequel je travaille en ce moment ; un outil pour rechercher des images similaires sur ma machine.
C'est par ici :
http://benjaminbillet.fr/blog
Juste pour info, c'est un PluXml (http://www.pluxml.org), un moteur de blog très simple et sans base de données.
dim. 17 mai 2015 15:38:29 CEST -
-
link
- http://benjaminbillet.fr/blog
programmation informatique
Il m'arrive assez régulièrement de lancer des micro-projets sur des thématiques diverses et d'en profiter pour tester des technologies. Pour garder une trace des problèmes rencontrés et des méthodes de résolution, un moteur de blog me permettra de prendre des notes organisées par projets (catégories), ce de manière plus efficace que sur mon journal de liens.
J'inaugure le blog avec le petit projet sur lequel je travaille en ce moment ; un outil pour rechercher des images similaires sur ma machine.
C'est par ici :
http://benjaminbillet.fr/blog
Juste pour info, c'est un PluXml (http://www.pluxml.org), un moteur de blog très simple et sans base de données.
dim. 17 mai 2015 15:38:29 CEST -
-
link
- http://benjaminbillet.fr/blog
programmation informatique
JustWriting - Votre blog 100% Markdown (et sans base de données) - Le Hollandais Volant
 Non. Une base de données n'est pas une sorte de conteneur magique, c'est aussi un système de stockage basé sur des fichiers. Par contre, il est conçu spécifiquement pour gérer des données et fournit l'ensemble des mécanismes pour faire ça efficacement. Ce n'est pas pour rien que les théories à l'origine des bases de données sont vastes et complexes.
Non. Une base de données n'est pas une sorte de conteneur magique, c'est aussi un système de stockage basé sur des fichiers. Par contre, il est conçu spécifiquement pour gérer des données et fournit l'ensemble des mécanismes pour faire ça efficacement. Ce n'est pas pour rien que les théories à l'origine des bases de données sont vastes et complexes.
Concrètement, donc, il est tout à fait possible d'utiliser un sous-ensemble des optimisations d'une base de données sur un système de fichiers textes "maison". Par exemple, de manière générale, ce qui accélère beaucoup une base de données ce sont les index.
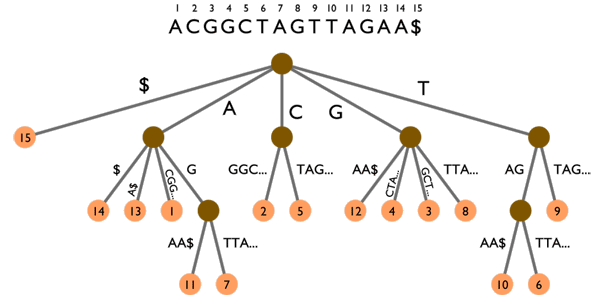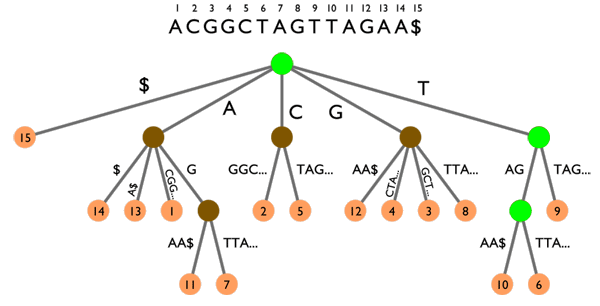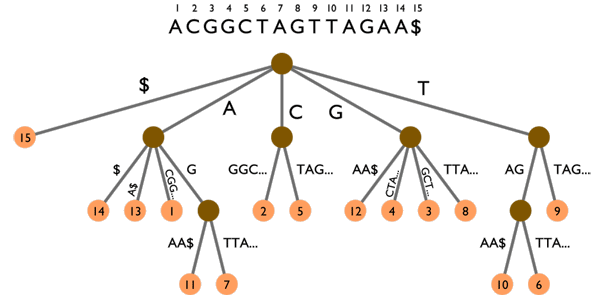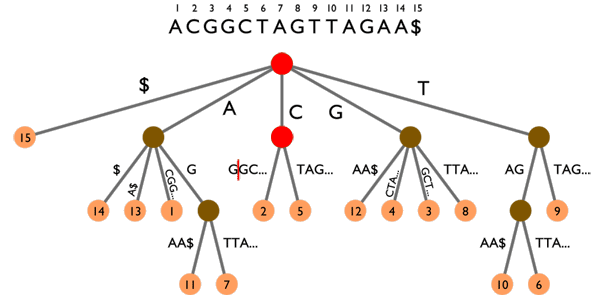
Une recherche rapide dans les articles peut donc se faire grâce à un index de mots-clés, grosso modo un gros tableau de la forme mot-clé -> [ID des articles contenant ce mot-clé]. Cet index est mis à jour à chaque ajout/édition/suppression d'articles. Si le nombre de mots-clés devient très grand et que l'on est limité en taille de fichier par PHP, les index hiérarchiques sont là pour ça. Dans ce type d'index, on va utiliser une chaîne de clé pour arriver jusqu'aux ID d'articles. Ainsi, les clés forment un arbre dont les feuilles sont les différents sous-ensembles de mot-clés/ID d'articles que l'on souhaite répartir dans des fichiers différents. Par exemple, cette chaîne peut être alphabétique : une première partition se ferait sur la première lettre des mots-clés, puis sur la seconde et ainsi de suite autant de fois que nécessaire. En augmentant ainsi le nombre de niveaux hiérarchiques, on peut gérer des index de TRES grande taille.
La liaison articles/commentaires est le plus simple, il suffit d'avoir un fichier de commentaires par article, et un index de mot-clé sur les commentaires pour pouvoir faire des recherches par mot-clé. Si l'on souhaite pouvoir faire des recherches par date, on prendra soin de créer un index approprié, dont les clés sont triées par date : un index trié est très rapide à parcourir en utilisant une recherche dichotomique.
A noter qu'un index inverse des commentaires vers les articles peut s'avérer très utile pour retrouver facilement un article à partir du commentaire.
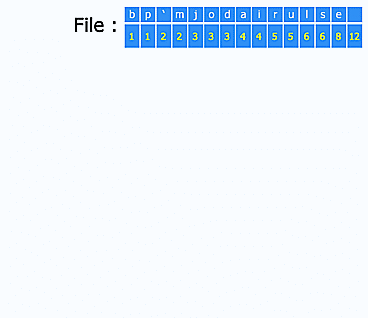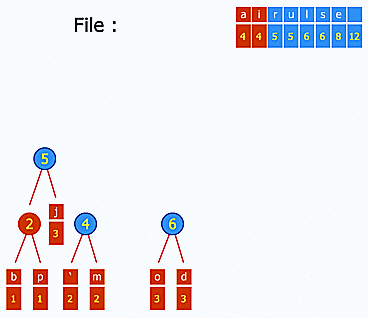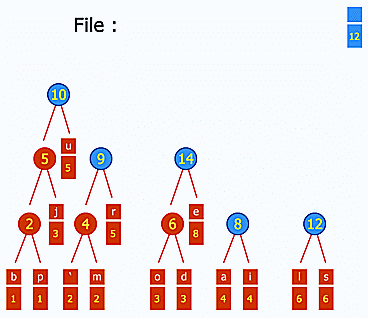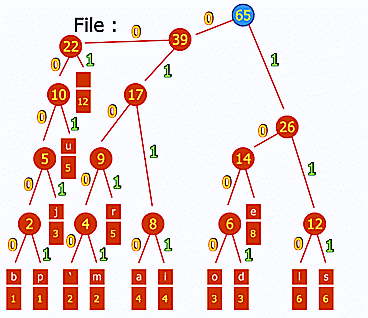
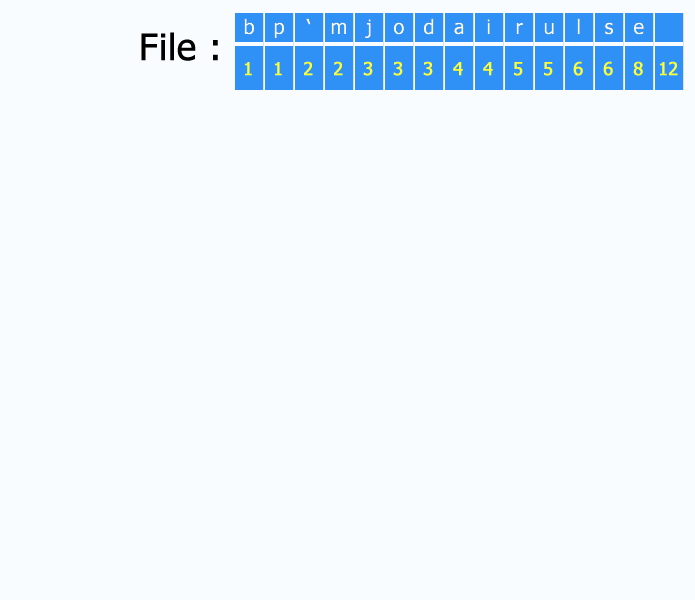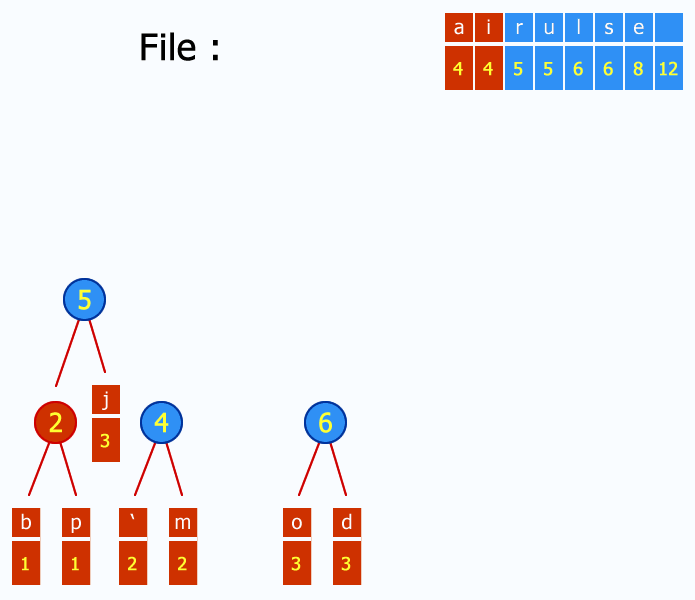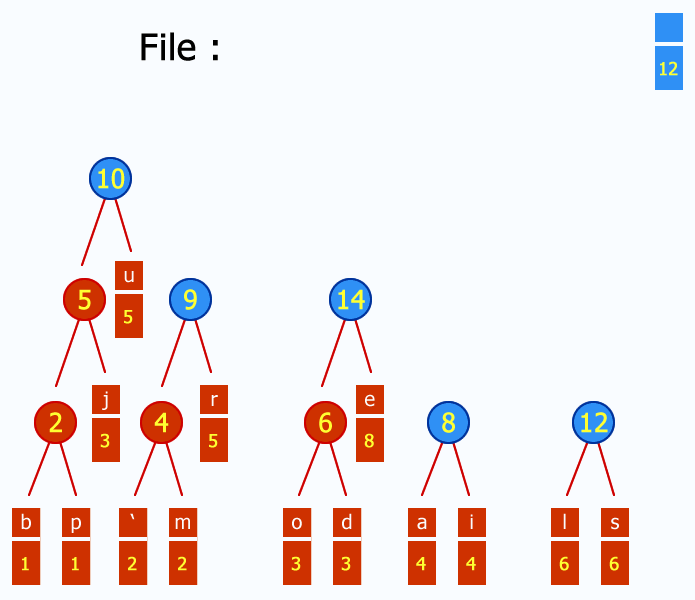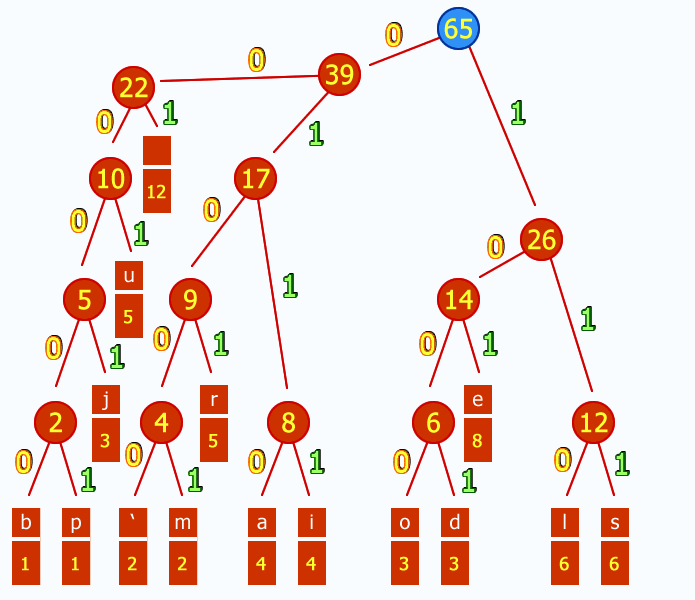
Enfin, pour gérer l'ensemble des articles et d'éventuelles métadonnées, on utilisera aussi un index d'articles. Cet index peut être distribué : par exemple, Ginger utilise des fichiers liés, découpés en blocs de x articles, ce qui permet de pré-paginer l'affichage des liens avec des facteurs de x : 2x, 3x, 4x, etc.
Enfin, parler d'optimisation de stockage sans préciser qu'est ce que l'on cherche à optimiser n'a pas vraiment de sens. Une base de données sacrifie justement de l'espace de stockage pour la rapidité d'accès ou la rapidité d'écriture, notamment grâce aux index.
Globalement, les index sont des structures très simples, mais très puissantes. Par contre, ce sont des structures figées : si l'on veut pouvoir faire des recherches sur de nouveaux paramètres il faut construire de nouveaux index. Cela nécessite de réfléchir à ce que l'on fait lors de la conception de son logiciel, et non pas à l'arrache au fur et à mesure.
lun. 29 sept. 2014 21:47:10 CEST -
-
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140929155551
index informatique bdd
Concrètement, donc, il est tout à fait possible d'utiliser un sous-ensemble des optimisations d'une base de données sur un système de fichiers textes "maison". Par exemple, de manière générale, ce qui accélère beaucoup une base de données ce sont les index.
Une recherche rapide dans les articles peut donc se faire grâce à un index de mots-clés, grosso modo un gros tableau de la forme mot-clé -> [ID des articles contenant ce mot-clé]. Cet index est mis à jour à chaque ajout/édition/suppression d'articles. Si le nombre de mots-clés devient très grand et que l'on est limité en taille de fichier par PHP, les index hiérarchiques sont là pour ça. Dans ce type d'index, on va utiliser une chaîne de clé pour arriver jusqu'aux ID d'articles. Ainsi, les clés forment un arbre dont les feuilles sont les différents sous-ensembles de mot-clés/ID d'articles que l'on souhaite répartir dans des fichiers différents. Par exemple, cette chaîne peut être alphabétique : une première partition se ferait sur la première lettre des mots-clés, puis sur la seconde et ainsi de suite autant de fois que nécessaire. En augmentant ainsi le nombre de niveaux hiérarchiques, on peut gérer des index de TRES grande taille.
La liaison articles/commentaires est le plus simple, il suffit d'avoir un fichier de commentaires par article, et un index de mot-clé sur les commentaires pour pouvoir faire des recherches par mot-clé. Si l'on souhaite pouvoir faire des recherches par date, on prendra soin de créer un index approprié, dont les clés sont triées par date : un index trié est très rapide à parcourir en utilisant une recherche dichotomique.
A noter qu'un index inverse des commentaires vers les articles peut s'avérer très utile pour retrouver facilement un article à partir du commentaire.
Enfin, pour gérer l'ensemble des articles et d'éventuelles métadonnées, on utilisera aussi un index d'articles. Cet index peut être distribué : par exemple, Ginger utilise des fichiers liés, découpés en blocs de x articles, ce qui permet de pré-paginer l'affichage des liens avec des facteurs de x : 2x, 3x, 4x, etc.
Enfin, parler d'optimisation de stockage sans préciser qu'est ce que l'on cherche à optimiser n'a pas vraiment de sens. Une base de données sacrifie justement de l'espace de stockage pour la rapidité d'accès ou la rapidité d'écriture, notamment grâce aux index.
Globalement, les index sont des structures très simples, mais très puissantes. Par contre, ce sont des structures figées : si l'on veut pouvoir faire des recherches sur de nouveaux paramètres il faut construire de nouveaux index. Cela nécessite de réfléchir à ce que l'on fait lors de la conception de son logiciel, et non pas à l'arrache au fur et à mesure.
lun. 29 sept. 2014 21:47:10 CEST -
-
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140929155551
index informatique bdd
xkcd: Tasks
 Cette planche est tellement vraie. Grossièrement traduit, ça donne :
Cette planche est tellement vraie. Grossièrement traduit, ça donne :
- quand un utilisateur prend une photo, l'application doit vérifier s'il se trouve dans un parc national...
- ok, c'est juste une vérification à faire avec les coordonnées géographiques.
- ... et vérifier s'il s'agit d'une photo d'oiseau.
- j'aurais besoin d'une équipe de recherche et de cinq ans.
Légende : En informatique, il est parfois difficile d'expliquer la différence entre le facile et le pratiquement impossible.
Et le texte alternatif est très parlant lui aussi :
"In the 60s, Marvin Minsky assigned a couple of undergrads to spend the summer programming a computer to use a camera to identify objects in a scene. He figured they'd have the problem solved by the end of the summer. Half a century later, we're still working on it."
Pour info, Marvin Minsky est l'un des grands acteurs de l'intelligence artificielle.
jeu. 25 sept. 2014 12:22:16 CEST -
-
link
- http://xkcd.com/1425
humour informatique
- quand un utilisateur prend une photo, l'application doit vérifier s'il se trouve dans un parc national...
- ok, c'est juste une vérification à faire avec les coordonnées géographiques.
- ... et vérifier s'il s'agit d'une photo d'oiseau.
- j'aurais besoin d'une équipe de recherche et de cinq ans.
Légende : En informatique, il est parfois difficile d'expliquer la différence entre le facile et le pratiquement impossible.
Et le texte alternatif est très parlant lui aussi :
"In the 60s, Marvin Minsky assigned a couple of undergrads to spend the summer programming a computer to use a camera to identify objects in a scene. He figured they'd have the problem solved by the end of the summer. Half a century later, we're still working on it."
Pour info, Marvin Minsky est l'un des grands acteurs de l'intelligence artificielle.
jeu. 25 sept. 2014 12:22:16 CEST -
-
link
- http://xkcd.com/1425
humour informatique
Negative data | The Upturned Microscope
 S'il y a bien quelque chose que j'ai pu observer auprès des chercheurs, c'est cette crainte de l'échec d'une expérience ou du blocage dans une voie sans issue.
S'il y a bien quelque chose que j'ai pu observer auprès des chercheurs, c'est cette crainte de l'échec d'une expérience ou du blocage dans une voie sans issue.
Certes, c'est une crainte légitime, en cela qu'il est très difficile de publier un papier sur quelque chose qui ne fonctionne pas. Et dans le monde de la science, qui ne publie pas n'existe pas.
Toutefois, c'est extrêmement dommageable, sachant que le travail d'introspection sur ces échecs permettrait d'éviter à d'autres de les répéter et donc d'explorer d'autres voies après avoir tiré des leçons du passé. Réfléchir sur les causes de l'échec d'une idée ou de l'absence de résultats sur un axe de recherche donné est un processus sain, qui fait partie intégrante de la démarche scientifique.
Globalement :
1. Un échec EST un résultat, et devrait être publié-traité comme tel.
2. L'absence de résultats EST un résultat, et devrait être publié-traité comme tel.
Le jour où les chercheurs, et à plus forte raison les éditeurs, intégreront ces règles, les scientifiques cesseront de perdre du temps à explorer plusieurs fois les mêmes voies sans issues.
Je rêve du jour où des journaux et des conférences seront dédiés aux résultats négatifs.
ven. 19 sept. 2014 09:41:29 CEST -
-
link
- http://theupturnedmicroscope.com/comic/negative-data/
science informatique recherche
Certes, c'est une crainte légitime, en cela qu'il est très difficile de publier un papier sur quelque chose qui ne fonctionne pas. Et dans le monde de la science, qui ne publie pas n'existe pas.
Toutefois, c'est extrêmement dommageable, sachant que le travail d'introspection sur ces échecs permettrait d'éviter à d'autres de les répéter et donc d'explorer d'autres voies après avoir tiré des leçons du passé. Réfléchir sur les causes de l'échec d'une idée ou de l'absence de résultats sur un axe de recherche donné est un processus sain, qui fait partie intégrante de la démarche scientifique.
Globalement :
1. Un échec EST un résultat, et devrait être publié-traité comme tel.
2. L'absence de résultats EST un résultat, et devrait être publié-traité comme tel.
Le jour où les chercheurs, et à plus forte raison les éditeurs, intégreront ces règles, les scientifiques cesseront de perdre du temps à explorer plusieurs fois les mêmes voies sans issues.
Je rêve du jour où des journaux et des conférences seront dédiés aux résultats négatifs.
ven. 19 sept. 2014 09:41:29 CEST -
-
link
- http://theupturnedmicroscope.com/comic/negative-data/
science informatique recherche
The Visual Microphone: Passive Recovery of Sound from Video
 Une technique pour reconstruire le son d'une vidéo à partir des vibrations infimes des objets (feuilles des plantes, paquet de chips), qui n'est pas sans rappeler l'utilisation des lasers pour détecter les vibrations d'une vitre.
Une technique pour reconstruire le son d'une vidéo à partir des vibrations infimes des objets (feuilles des plantes, paquet de chips), qui n'est pas sans rappeler l'utilisation des lasers pour détecter les vibrations d'une vitre.
La solution pour extraire des sons dont la fréquence est supérieure à la fréquence d'enregistrement de la vidéo, est particulièrement intéressante.
J'aimerais cependant connaître les détails exacts de l'expérience, comme la position de l'émetteur du signal sonore par rapport à l'objet observé ainsi que la résolution des vidéos (et pas seulement leur fréquence). D'après ce qui est dit dans la vidéo "les feuilles bougent de moins d'une centaine de pixels", ce qui porterait à croire que la résolution nécessaire est significativement élevée.
EDIT : J'ai pu lire le papier (c'est pratique de travailler dans un centre de recherche) et il s'avère que la source est très proche de l'objet (http://benjaminbillet.fr/media/siggraph2014-fig4-experiment.png). La résolution nécessaire est assez faible mais l'objet doit être filmé de près.
Toutefois, les résultats restent très intéressant, notamment dans le cas où l'acquisition est réalisée avec une caméra classique (une Pentax K-01).
mar. 05 août 2014 12:07:02 CEST -
-
link
- http://people.csail.mit.edu/mrub/VisualMic/
informatique
La solution pour extraire des sons dont la fréquence est supérieure à la fréquence d'enregistrement de la vidéo, est particulièrement intéressante.
J'aimerais cependant connaître les détails exacts de l'expérience, comme la position de l'émetteur du signal sonore par rapport à l'objet observé ainsi que la résolution des vidéos (et pas seulement leur fréquence). D'après ce qui est dit dans la vidéo "les feuilles bougent de moins d'une centaine de pixels", ce qui porterait à croire que la résolution nécessaire est significativement élevée.
EDIT : J'ai pu lire le papier (c'est pratique de travailler dans un centre de recherche) et il s'avère que la source est très proche de l'objet (http://benjaminbillet.fr/media/siggraph2014-fig4-experiment.png). La résolution nécessaire est assez faible mais l'objet doit être filmé de près.
{kind=link}
Toutefois, les résultats restent très intéressant, notamment dans le cas où l'acquisition est réalisée avec une caméra classique (une Pentax K-01).
mar. 05 août 2014 12:07:02 CEST -
-
link
- http://people.csail.mit.edu/mrub/VisualMic/
informatique
List of Free Learning Resources - vhf/free-programming-books - GitHub
 Histoire de ne plus dormir pendant quelques mois, ce repository héberge une très longue liste de livres de programmation, en libre accès. On y trouve aussi des livres portant sur l'algorithmique, des méthodologie de développement, les bases de données, le data mining, les mathématiques, etc.
Histoire de ne plus dormir pendant quelques mois, ce repository héberge une très longue liste de livres de programmation, en libre accès. On y trouve aussi des livres portant sur l'algorithmique, des méthodologie de développement, les bases de données, le data mining, les mathématiques, etc.
Les listes sont organisées par langue (plus de 20 langues) puis par langage ou domaine.
La liste anglaise est vraiment impressionnante :
https://github.com/vhf/free-programming-books/blob/master/free-programming-books.md
jeu. 10 juil. 2014 10:51:32 CEST -
-
link
- https://github.com/vhf/free-programming-books
programmation algorithmique réseau informatique
Les listes sont organisées par langue (plus de 20 langues) puis par langage ou domaine.
La liste anglaise est vraiment impressionnante :
https://github.com/vhf/free-programming-books/blob/master/free-programming-books.md
jeu. 10 juil. 2014 10:51:32 CEST -
-
link
- https://github.com/vhf/free-programming-books
programmation algorithmique réseau informatique
Great Algorithms that Revolutionized Computing
 Une petite liste de concepts et d'algorithmes qui ont eu un impact fort sur l'informatique en général, tout particulièrement :
Une petite liste de concepts et d'algorithmes qui ont eu un impact fort sur l'informatique en général, tout particulièrement :
- le codage Huffman pour la compression (ce gif est génial d'ailleurs : http://upload.wikimedia.org/wikipedia/commons/a/ac/Huffman_huff_demo.gif) ;
- le chiffrement à clé publique ;
- l'algorithme de Djikstra pour la recherche des plus courts chemins (applications variées comme, par exemple, le routage) ;
- la recherche dichotomique (binary search) pour trouver un élément dans un tableau trié ;
- le tri rapide (quick sort).
Le choix de ces algorithmes en particulier est arbitraire, de nombreux autres pourraient être cités. Il faudra que je m'y emploie un jour :)
jeu. 10 juil. 2014 10:25:06 CEST -
-
link
- http://en.docsity.com/news/interesting-facts/great-algorithms-revolutionized-computing/
informatique algorithmique compression tri cryptographie
- le codage Huffman pour la compression (ce gif est génial d'ailleurs : http://upload.wikimedia.org/wikipedia/commons/a/ac/Huffman_huff_demo.gif) ;
{kind=link}
- le chiffrement à clé publique ;
- l'algorithme de Djikstra pour la recherche des plus courts chemins (applications variées comme, par exemple, le routage) ;
- la recherche dichotomique (binary search) pour trouver un élément dans un tableau trié ;
- le tri rapide (quick sort).
Le choix de ces algorithmes en particulier est arbitraire, de nombreux autres pourraient être cités. Il faudra que je m'y emploie un jour :)
jeu. 10 juil. 2014 10:25:06 CEST -
-
link
- http://en.docsity.com/news/interesting-facts/great-algorithms-revolutionized-computing/
informatique algorithmique compression tri cryptographie
[Traduction] Une escalade vertigineuse, mais invisible | Blog de tcit
Je n'arrive pas à me souvenir du nom de l'auteur de cette citation tout à fait de circonstance qui dit, en substance :
On mesure le degré d'évolution technologique d'une civilisation au nombre de choses difficiles que ses membres peuvent accomplir sans avoir à y penser.
Quelque chose comme ça :)
mer. 04 juin 2014 15:27:54 CEST -
-
link
- https://tcit.fr/2013/06/traduction-une-escalade-vertigineuse-mais-invisible/
technologie informatique
On mesure le degré d'évolution technologique d'une civilisation au nombre de choses difficiles que ses membres peuvent accomplir sans avoir à y penser.
Quelque chose comme ça :)
mer. 04 juin 2014 15:27:54 CEST -
-
link
- https://tcit.fr/2013/06/traduction-une-escalade-vertigineuse-mais-invisible/
technologie informatique
Blog Stéphane Bortzmeyer: RFC 7111: URI Fragment Identifiers for the text/csv Media Type
Les URI peuvent désigner une partie d'un document (ou fragment) en utilisant un identifiant précédé d'un # (ex : benjaminbillet.fr/something.html#page2). Jusqu'à présent on pouvait utiliser des identificateurs pour des fichiers XML, HTML (les ancres) et texte (RFC 5147).
Stéphane Bortzmeyer signale que la RFC 7111 vient juste de sortir et décrit comment utiliser les identificateurs de fragment dans le cas des fichiers CSV (accès à une ligne spécifique, une colonne, une cellule, etc.).
RFC 4180 (format CSV) : http://www.rfc-editor.org/rfc/rfc4180.txt
RFC 7111 : http://www.rfc-editor.org/rfc/rfc7111.txt
RFC 5147 : http://www.rfc-editor.org/rfc/rfc5147.txt
ven. 17 janv. 2014 18:07:10 CET -
-
link
- http://www.bortzmeyer.org/7111.html
rfc format
Stéphane Bortzmeyer signale que la RFC 7111 vient juste de sortir et décrit comment utiliser les identificateurs de fragment dans le cas des fichiers CSV (accès à une ligne spécifique, une colonne, une cellule, etc.).
RFC 4180 (format CSV) : http://www.rfc-editor.org/rfc/rfc4180.txt
RFC 7111 : http://www.rfc-editor.org/rfc/rfc7111.txt
RFC 5147 : http://www.rfc-editor.org/rfc/rfc5147.txt
ven. 17 janv. 2014 18:07:10 CET -
-
link
- http://www.bortzmeyer.org/7111.html
rfc format
Programmer Competency Matrix
Une matrice des différentes compétences de programmeur et leur niveau de maîtrise. Le pire c'est que j'ai étudié la plupart de ces trucs à un moment donné, mais j'en ai oublié la moitié étant donné que de nombreux concepts sont abstraits par les librairies (en algorithmie notamment). La connaissance passée compte-t-elle vraiment ? >>
sam. 28 sept. 2013 11:15:43 CEST -
-
link
- http://sijinjoseph.com/programmer-competency-matrix/
programmation informatique
sam. 28 sept. 2013 11:15:43 CEST -
-
link
- http://sijinjoseph.com/programmer-competency-matrix/
programmation informatique
Grammar: The language of languages (BNF, EBNF, ABNF and more)
Ceux qui lisent les RFC ont du remarquer que celles-ci font souvent appel à des grammaires (tout particulièrement ABNF, décrite par la RFC 5234) pour décrire les protocoles et les formats.
Les grammaires sont simplement des langages utilisés pour décrire des langages (on parle de métalangages). Par exemple, le langage des expressions rationnelles est un métalangage, mais il en existe un très grand nombre.
Ce site revient sur les grammaires BNF, EBNF et ABNF, qui sont des métalangages très répandus.
RFC 5234 : http://tools.ietf.org/html/rfc5234
mar. 05 févr. 2013 13:38:54 CET -
-
link
- http://matt.might.net/articles/grammars-bnf-ebnf
grammaire format rfc
Les grammaires sont simplement des langages utilisés pour décrire des langages (on parle de métalangages). Par exemple, le langage des expressions rationnelles est un métalangage, mais il en existe un très grand nombre.
Ce site revient sur les grammaires BNF, EBNF et ABNF, qui sont des métalangages très répandus.
RFC 5234 : http://tools.ietf.org/html/rfc5234
mar. 05 févr. 2013 13:38:54 CET -
-
link
- http://matt.might.net/articles/grammars-bnf-ebnf
grammaire format rfc
Portable pixmap
J'aime beaucoup l'informatique graphique, je fais un peu de programmation 3D à l'occasion et on manipule souvent des formats de fichier image, mesh, animation, etc.
Les *map file format sont des formats de fichier d'échange (peu performant en terme d'espace disque, cela dit :p) très simple à utiliser, lisibles par un être humain.
mar. 10 juil. 2012 22:07:18 CEST -
-
link
- http://fr.wikipedia.org/wiki/Portable_pixmap
multimédia format
Les *map file format sont des formats de fichier d'échange (peu performant en terme d'espace disque, cela dit :p) très simple à utiliser, lisibles par un être humain.
mar. 10 juil. 2012 22:07:18 CEST -
-
link
- http://fr.wikipedia.org/wiki/Portable_pixmap
multimédia format
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.