Journal
 RSS Feed
RSS Feed Tag cloud
Tag cloud
JustWriting - Votre blog 100% Markdown (et sans base de données) - Le Hollandais Volant
 Non. Une base de données n'est pas une sorte de conteneur magique, c'est aussi un système de stockage basé sur des fichiers. Par contre, il est conçu spécifiquement pour gérer des données et fournit l'ensemble des mécanismes pour faire ça efficacement. Ce n'est pas pour rien que les théories à l'origine des bases de données sont vastes et complexes.
Non. Une base de données n'est pas une sorte de conteneur magique, c'est aussi un système de stockage basé sur des fichiers. Par contre, il est conçu spécifiquement pour gérer des données et fournit l'ensemble des mécanismes pour faire ça efficacement. Ce n'est pas pour rien que les théories à l'origine des bases de données sont vastes et complexes.
Concrètement, donc, il est tout à fait possible d'utiliser un sous-ensemble des optimisations d'une base de données sur un système de fichiers textes "maison". Par exemple, de manière générale, ce qui accélère beaucoup une base de données ce sont les index.
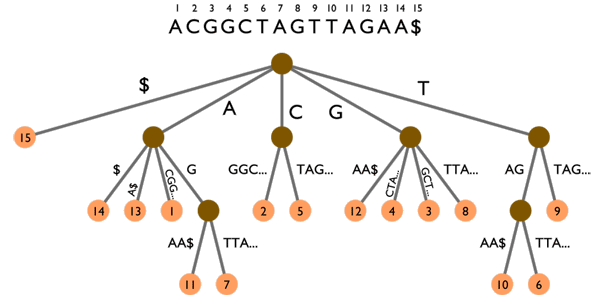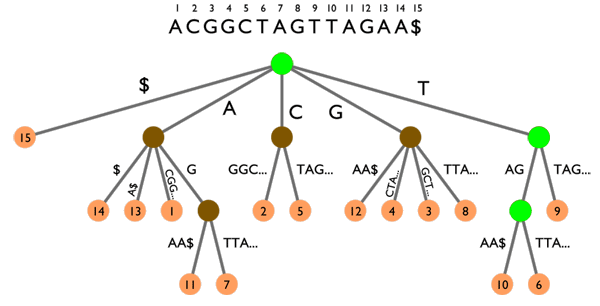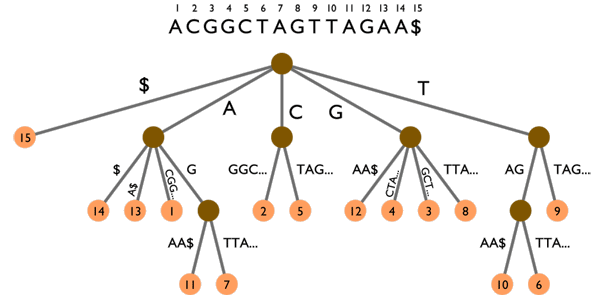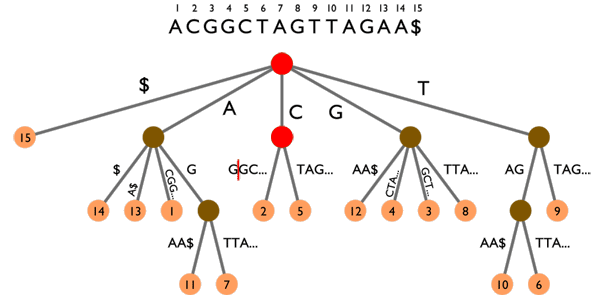
Une recherche rapide dans les articles peut donc se faire grâce à un index de mots-clés, grosso modo un gros tableau de la forme mot-clé -> [ID des articles contenant ce mot-clé]. Cet index est mis à jour à chaque ajout/édition/suppression d'articles. Si le nombre de mots-clés devient très grand et que l'on est limité en taille de fichier par PHP, les index hiérarchiques sont là pour ça. Dans ce type d'index, on va utiliser une chaîne de clé pour arriver jusqu'aux ID d'articles. Ainsi, les clés forment un arbre dont les feuilles sont les différents sous-ensembles de mot-clés/ID d'articles que l'on souhaite répartir dans des fichiers différents. Par exemple, cette chaîne peut être alphabétique : une première partition se ferait sur la première lettre des mots-clés, puis sur la seconde et ainsi de suite autant de fois que nécessaire. En augmentant ainsi le nombre de niveaux hiérarchiques, on peut gérer des index de TRES grande taille.
La liaison articles/commentaires est le plus simple, il suffit d'avoir un fichier de commentaires par article, et un index de mot-clé sur les commentaires pour pouvoir faire des recherches par mot-clé. Si l'on souhaite pouvoir faire des recherches par date, on prendra soin de créer un index approprié, dont les clés sont triées par date : un index trié est très rapide à parcourir en utilisant une recherche dichotomique.
A noter qu'un index inverse des commentaires vers les articles peut s'avérer très utile pour retrouver facilement un article à partir du commentaire.
Enfin, pour gérer l'ensemble des articles et d'éventuelles métadonnées, on utilisera aussi un index d'articles. Cet index peut être distribué : par exemple, Ginger utilise des fichiers liés, découpés en blocs de x articles, ce qui permet de pré-paginer l'affichage des liens avec des facteurs de x : 2x, 3x, 4x, etc.
Enfin, parler d'optimisation de stockage sans préciser qu'est ce que l'on cherche à optimiser n'a pas vraiment de sens. Une base de données sacrifie justement de l'espace de stockage pour la rapidité d'accès ou la rapidité d'écriture, notamment grâce aux index.
Globalement, les index sont des structures très simples, mais très puissantes. Par contre, ce sont des structures figées : si l'on veut pouvoir faire des recherches sur de nouveaux paramètres il faut construire de nouveaux index. Cela nécessite de réfléchir à ce que l'on fait lors de la conception de son logiciel, et non pas à l'arrache au fur et à mesure.
 lun. 29 sept. 2014 21:47:10 CEST -
lun. 29 sept. 2014 21:47:10 CEST -
 -
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140929155551
-
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140929155551
 index informatique bdd
index informatique bdd
Concrètement, donc, il est tout à fait possible d'utiliser un sous-ensemble des optimisations d'une base de données sur un système de fichiers textes "maison". Par exemple, de manière générale, ce qui accélère beaucoup une base de données ce sont les index.
Une recherche rapide dans les articles peut donc se faire grâce à un index de mots-clés, grosso modo un gros tableau de la forme mot-clé -> [ID des articles contenant ce mot-clé]. Cet index est mis à jour à chaque ajout/édition/suppression d'articles. Si le nombre de mots-clés devient très grand et que l'on est limité en taille de fichier par PHP, les index hiérarchiques sont là pour ça. Dans ce type d'index, on va utiliser une chaîne de clé pour arriver jusqu'aux ID d'articles. Ainsi, les clés forment un arbre dont les feuilles sont les différents sous-ensembles de mot-clés/ID d'articles que l'on souhaite répartir dans des fichiers différents. Par exemple, cette chaîne peut être alphabétique : une première partition se ferait sur la première lettre des mots-clés, puis sur la seconde et ainsi de suite autant de fois que nécessaire. En augmentant ainsi le nombre de niveaux hiérarchiques, on peut gérer des index de TRES grande taille.
La liaison articles/commentaires est le plus simple, il suffit d'avoir un fichier de commentaires par article, et un index de mot-clé sur les commentaires pour pouvoir faire des recherches par mot-clé. Si l'on souhaite pouvoir faire des recherches par date, on prendra soin de créer un index approprié, dont les clés sont triées par date : un index trié est très rapide à parcourir en utilisant une recherche dichotomique.
A noter qu'un index inverse des commentaires vers les articles peut s'avérer très utile pour retrouver facilement un article à partir du commentaire.
Enfin, pour gérer l'ensemble des articles et d'éventuelles métadonnées, on utilisera aussi un index d'articles. Cet index peut être distribué : par exemple, Ginger utilise des fichiers liés, découpés en blocs de x articles, ce qui permet de pré-paginer l'affichage des liens avec des facteurs de x : 2x, 3x, 4x, etc.
Enfin, parler d'optimisation de stockage sans préciser qu'est ce que l'on cherche à optimiser n'a pas vraiment de sens. Une base de données sacrifie justement de l'espace de stockage pour la rapidité d'accès ou la rapidité d'écriture, notamment grâce aux index.
Globalement, les index sont des structures très simples, mais très puissantes. Par contre, ce sont des structures figées : si l'on veut pouvoir faire des recherches sur de nouveaux paramètres il faut construire de nouveaux index. Cela nécessite de réfléchir à ce que l'on fait lors de la conception de son logiciel, et non pas à l'arrache au fur et à mesure.
lun. 29 sept. 2014 21:47:10 CEST -
-
link
- http://lehollandaisvolant.net/index.php?mode=links&id=20140929155551
index informatique bdd
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.