Journal
Ce journal contient 16 entrées.
 RSS Feed
RSS Feed Tag cloud
Tag cloud
GitHub - dokan-dev/dokany: User mode file system library for windows with FUSE Wrapper
 Génial, un équivalent à FUSE (Filesystem in Userspace) pour Windows. Il s'agit d'une interface permettant d'écrire des systèmes de fichier "virtuels", c'est-à-dire ne nécessitant pas de modifier le noyau du système d'exploitation pour fonctionner.
Génial, un équivalent à FUSE (Filesystem in Userspace) pour Windows. Il s'agit d'une interface permettant d'écrire des systèmes de fichier "virtuels", c'est-à-dire ne nécessitant pas de modifier le noyau du système d'exploitation pour fonctionner.
C'est une fonctionnalité qui a toujours manqué à Windows.
 jeu. 22 sept. 2016 14:29:10 CEST -
jeu. 22 sept. 2016 14:29:10 CEST -
 -
link
- https://github.com/dokan-dev/dokany
-
link
- https://github.com/dokan-dev/dokany
 outil programmation système
outil programmation système
C'est une fonctionnalité qui a toujours manqué à Windows.
jeu. 22 sept. 2016 14:29:10 CEST -
-
link
- https://github.com/dokan-dev/dokany
outil programmation système
L'opérateur conditionnel ternaire
Je n'aime pas beaucoup l'opérateur conditionnel ternaire (a ? b : c). Je déconseille toujours à mes étudiants de l'utiliser, car j'estime qu'il nuit à la lisibilité du code.
Eh bien, je vais pouvoir désormais illustrer mon conseil avec un exemple réel, qui vient du code de Jetty 9 :
super(new URL[]{},parent!=null?parent
:(Thread.currentThread().getContextClassLoader()!=null?Thread.currentThread().getContextClassLoader()
:(WebAppClassLoader.class.getClassLoader()!=null?WebAppClassLoader.class.getClassLoader()
:ClassLoader.getSystemClassLoader())));
mar. 10 nov. 2015 09:49:07 CET -
-
link
programmation
Eh bien, je vais pouvoir désormais illustrer mon conseil avec un exemple réel, qui vient du code de Jetty 9 :
super(new URL[]{},parent!=null?parent
:(Thread.currentThread().getContextClassLoader()!=null?Thread.currentThread().getContextClassLoader()
:(WebAppClassLoader.class.getClassLoader()!=null?WebAppClassLoader.class.getClassLoader()
:ClassLoader.getSystemClassLoader())));
mar. 10 nov. 2015 09:49:07 CET -
-
link
programmation
Blog Stéphane Bortzmeyer: Le principe de robustesse, une bonne ou une mauvaise idée ?
 Le principe de Postel est très connu dans le monde des protocoles réseaux : "Soyez rigoureux dans ce que produisez, soyez compréhensif avec ce qui vient des autres".
Le principe de Postel est très connu dans le monde des protocoles réseaux : "Soyez rigoureux dans ce que produisez, soyez compréhensif avec ce qui vient des autres".
L'objectif de ce principe consiste à maximiser le respect des standards, tout en introduisant une certaine robustesse envers les erreurs mineures et prévisibles qui pourraient exister dans les différentes implémentations.
Malheureusement, ce principe est mal compris, ou plutôt poussé à son extrême : des mécanismes complexes sont mis en œuvre pour résister à des erreurs hypothétiques, ce qui amène les développeurs à se montrer moins rigoureux et à faire émerger ces erreurs. Et une fois que ces erreurs deviennent une habitude, toute nouvelle implémentation se doit de gérer ces erreurs là.
En ce qui me concerne, j'applique le principe de Postel uniquement pour les erreurs évidentes (espaces en trop, par exemple) ou pour les erreurs faciles à détecter/corriger (valeurs oubliées). Hors de question de mettre en place des heuristiques complexes telles que celles implémentées par les navigateurs pour afficher du contenu à tout prix.
Avec le temps, je me rends compte aussi que le principe de Postel tend à être incompatible avec le principe "fail fast", qui consiste à dire qu'une erreur devrait survenir le plus tôt possible (et donc que, justement, un programme ne devrait pas chercher à corriger ou à ignorer les erreurs, mais plutôt échouer rapidement et de manière visible. En effet, l'existence d'une erreur est justement le signe que quelque chose ne va pas, et qu'il y a probablement des soucis en amont. Faire remonter ces erreurs permet de mettre en évidence ces soucis et de les corriger une bonne fois pour toute.
mar. 27 oct. 2015 19:51:03 CET -
-
link
- http://www.bortzmeyer.org/principe-robustesse.html
génie-logiciel postel programmation
L'objectif de ce principe consiste à maximiser le respect des standards, tout en introduisant une certaine robustesse envers les erreurs mineures et prévisibles qui pourraient exister dans les différentes implémentations.
Malheureusement, ce principe est mal compris, ou plutôt poussé à son extrême : des mécanismes complexes sont mis en œuvre pour résister à des erreurs hypothétiques, ce qui amène les développeurs à se montrer moins rigoureux et à faire émerger ces erreurs. Et une fois que ces erreurs deviennent une habitude, toute nouvelle implémentation se doit de gérer ces erreurs là.
En ce qui me concerne, j'applique le principe de Postel uniquement pour les erreurs évidentes (espaces en trop, par exemple) ou pour les erreurs faciles à détecter/corriger (valeurs oubliées). Hors de question de mettre en place des heuristiques complexes telles que celles implémentées par les navigateurs pour afficher du contenu à tout prix.
Avec le temps, je me rends compte aussi que le principe de Postel tend à être incompatible avec le principe "fail fast", qui consiste à dire qu'une erreur devrait survenir le plus tôt possible (et donc que, justement, un programme ne devrait pas chercher à corriger ou à ignorer les erreurs, mais plutôt échouer rapidement et de manière visible. En effet, l'existence d'une erreur est justement le signe que quelque chose ne va pas, et qu'il y a probablement des soucis en amont. Faire remonter ces erreurs permet de mettre en évidence ces soucis et de les corriger une bonne fois pour toute.
mar. 27 oct. 2015 19:51:03 CET -
-
link
- http://www.bortzmeyer.org/principe-robustesse.html
génie-logiciel postel programmation
Iterative Vs Incremental
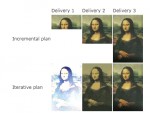 "IterativeDevelopment means:
"IterativeDevelopment means:
I write loads of stuff that's a complete mess
I go through it throwing out the irrelevant drivel, expanding on the important bits, and sorting out the structure
I go through it again now I can start to see the shape of it, sorting it some more
I go through it yet again, etc, until it's GoodEnough
IncrementalDevelopment means:
I write part one
I write part two
I write part three, etc, until the book is finished
[...]
So in practice, at least in XP practice, your development is both incremental and iterative.
-- StephenHutchinson
The danger is when people confuse the two. I saw a 200 person project iterating on their requirements (allowing arbitrary amount of change) when they should have been incrementing through their requirements, and incrementing & iterating (as you describe) through their design. They were, of course, not making any progress. Also saw a 100 person project claiming they were iterating through their entire novel, when in fact they were doing neither - they were stuck in the mud. They needed to get at least some part working first so they could tell they were moving - once again, needed incrementing as a base.
-- AlistairCockburn"
Image de la miniature : http://www.applitude.se/images/inc_vs_ite.png
lun. 19 oct. 2015 07:17:42 CEST -
-
link
- http://c2.com/cgi/wiki?IterativeVsIncremental
programmation génie-logiciel
I write loads of stuff that's a complete mess
I go through it throwing out the irrelevant drivel, expanding on the important bits, and sorting out the structure
I go through it again now I can start to see the shape of it, sorting it some more
I go through it yet again, etc, until it's GoodEnough
IncrementalDevelopment means:
I write part one
I write part two
I write part three, etc, until the book is finished
[...]
So in practice, at least in XP practice, your development is both incremental and iterative.
-- StephenHutchinson
The danger is when people confuse the two. I saw a 200 person project iterating on their requirements (allowing arbitrary amount of change) when they should have been incrementing through their requirements, and incrementing & iterating (as you describe) through their design. They were, of course, not making any progress. Also saw a 100 person project claiming they were iterating through their entire novel, when in fact they were doing neither - they were stuck in the mud. They needed to get at least some part working first so they could tell they were moving - once again, needed incrementing as a base.
-- AlistairCockburn"
Image de la miniature : http://www.applitude.se/images/inc_vs_ite.png
{kind=link} lun. 19 oct. 2015 07:17:42 CEST -
-
link
- http://c2.com/cgi/wiki?IterativeVsIncremental
programmation génie-logiciel
lun. 19 oct. 2015 07:17:42 CEST -
-
link
- http://c2.com/cgi/wiki?IterativeVsIncremental
programmation génie-logiciel
/dev/log - Blog technique de Benjamin Billet
 J'inaugure une nouvelle partie pour le site : un blog qui me servira à prendre des notes sur mes projets personnels.
J'inaugure une nouvelle partie pour le site : un blog qui me servira à prendre des notes sur mes projets personnels.
Il m'arrive assez régulièrement de lancer des micro-projets sur des thématiques diverses et d'en profiter pour tester des technologies. Pour garder une trace des problèmes rencontrés et des méthodes de résolution, un moteur de blog me permettra de prendre des notes organisées par projets (catégories), ce de manière plus efficace que sur mon journal de liens.
J'inaugure le blog avec le petit projet sur lequel je travaille en ce moment ; un outil pour rechercher des images similaires sur ma machine.
C'est par ici :
http://benjaminbillet.fr/blog
Juste pour info, c'est un PluXml (http://www.pluxml.org), un moteur de blog très simple et sans base de données.
dim. 17 mai 2015 15:38:29 CEST -
-
link
- http://benjaminbillet.fr/blog
programmation informatique
Il m'arrive assez régulièrement de lancer des micro-projets sur des thématiques diverses et d'en profiter pour tester des technologies. Pour garder une trace des problèmes rencontrés et des méthodes de résolution, un moteur de blog me permettra de prendre des notes organisées par projets (catégories), ce de manière plus efficace que sur mon journal de liens.
J'inaugure le blog avec le petit projet sur lequel je travaille en ce moment ; un outil pour rechercher des images similaires sur ma machine.
C'est par ici :
http://benjaminbillet.fr/blog
Juste pour info, c'est un PluXml (http://www.pluxml.org), un moteur de blog très simple et sans base de données.
dim. 17 mai 2015 15:38:29 CEST -
-
link
- http://benjaminbillet.fr/blog
programmation informatique
Gestion des cas d'erreur : les exceptions
De bonnes pratiques pour la gestion des exceptions vérifiées/non vérifiées.
Toutefois, les exceptions non vérifiées, c'est-à-dire celles que le développeur n'est pas obligé de gérer pour pouvoir compiler son programme, posent un problème majeur : on ignore, à tout moment, quelles exceptions vont être retournées par les méthodes que l'on invoque.
Lorsqu'un programme devient assez gros, la plupart des méthodes font appels à d'autres méthodes et ainsi de suite. Si les librairies ne documentent pas précisément quelles sont les exceptions non vérifiées qui peuvent être lancées, alors il n'y a qu'à l'exécution que l'on se rendra compte que des erreurs surviennent en masse.
mer. 01 oct. 2014 10:10:01 CEST -
-
link
- https://blog.imirhil.fr/gestion-des-cas-derreur-les-exceptions.html
exception erreur programmation
Toutefois, les exceptions non vérifiées, c'est-à-dire celles que le développeur n'est pas obligé de gérer pour pouvoir compiler son programme, posent un problème majeur : on ignore, à tout moment, quelles exceptions vont être retournées par les méthodes que l'on invoque.
Lorsqu'un programme devient assez gros, la plupart des méthodes font appels à d'autres méthodes et ainsi de suite. Si les librairies ne documentent pas précisément quelles sont les exceptions non vérifiées qui peuvent être lancées, alors il n'y a qu'à l'exécution que l'on se rendra compte que des erreurs surviennent en masse.
mer. 01 oct. 2014 10:10:01 CEST -
-
link
- https://blog.imirhil.fr/gestion-des-cas-derreur-les-exceptions.html
exception erreur programmation
A curated list of awesome Machine Learning frameworks, libraries and software
Une liste de librairies d'apprentissage artificiel, de traitement du langage naturel et de data mining. Pour divers langages : C/C++, Java, Python, etc.
mer. 16 juil. 2014 14:58:27 CEST -
-
link
- https://github.com/josephmisiti/awesome-machine-learning
machine-learning programmation datamining
mer. 16 juil. 2014 14:58:27 CEST -
-
link
- https://github.com/josephmisiti/awesome-machine-learning
machine-learning programmation datamining
docopt—language for description of command-line interfaces
 Docopt est un langage de description d'interface en ligne de commande. Il permet d'exprimer les différents paramètres admis en entrée du programme et de générer le parser associé dans plusieurs langages (Ruby, Go, C#, Python, C, etc.).
Docopt est un langage de description d'interface en ligne de commande. Il permet d'exprimer les différents paramètres admis en entrée du programme et de générer le parser associé dans plusieurs langages (Ruby, Go, C#, Python, C, etc.).
Le langage est basé sur les conventions qui sont utilisées dans les messages d'aide des commandes linux ou dans les pages de man (voir les exemples pour plus d'informations).
ven. 11 juil. 2014 18:49:39 CEST -
-
link
- http://docopt.org
programmation shell
Le langage est basé sur les conventions qui sont utilisées dans les messages d'aide des commandes linux ou dans les pages de man (voir les exemples pour plus d'informations).
ven. 11 juil. 2014 18:49:39 CEST -
-
link
- http://docopt.org
programmation shell
ChucK => Strongly-timed, On-the-fly Music Programming Language
 ChucK est un langage de programmation open-source et multiplateforme, pour la synthèse audio temps réel. Il se présente sous la forme d'une syntaxe spécifique, conçue pour exprimer simplement des opérations de synthèse audio (oscillateurs, effets, etc.) évoluant au cours du temps (logique temporelle) et les connecter les uns aux autres. De plus, le langage offre un modèle de programmation concurrente simple d'emploi.
ChucK est un langage de programmation open-source et multiplateforme, pour la synthèse audio temps réel. Il se présente sous la forme d'une syntaxe spécifique, conçue pour exprimer simplement des opérations de synthèse audio (oscillateurs, effets, etc.) évoluant au cours du temps (logique temporelle) et les connecter les uns aux autres. De plus, le langage offre un modèle de programmation concurrente simple d'emploi.
Un petit exemple tiré de la documentation :
// on crée une signal sinusoïde que l'on connecte au "digital/analog converter"
SinOsc s => dac; // sine oscillator
while(true)
{
// on choisit une fréquence aléatoire entre 30 et 1000 Hz
Std.rand2f( 30, 1000 ) => s.freq;
// on avance de 100 millisecondes dans le temps
100::ms => now;
}
ven. 11 juil. 2014 18:06:59 CEST -
-
link
- http://chuck.cs.princeton.edu
musique programmation langage synthétiseur
Un petit exemple tiré de la documentation :
// on crée une signal sinusoïde que l'on connecte au "digital/analog converter"
SinOsc s => dac; // sine oscillator
while(true)
{
// on choisit une fréquence aléatoire entre 30 et 1000 Hz
Std.rand2f( 30, 1000 ) => s.freq;
// on avance de 100 millisecondes dans le temps
100::ms => now;
}
ven. 11 juil. 2014 18:06:59 CEST -
-
link
- http://chuck.cs.princeton.edu
musique programmation langage synthétiseur
List of Free Learning Resources - vhf/free-programming-books - GitHub
 Histoire de ne plus dormir pendant quelques mois, ce repository héberge une très longue liste de livres de programmation, en libre accès. On y trouve aussi des livres portant sur l'algorithmique, des méthodologie de développement, les bases de données, le data mining, les mathématiques, etc.
Histoire de ne plus dormir pendant quelques mois, ce repository héberge une très longue liste de livres de programmation, en libre accès. On y trouve aussi des livres portant sur l'algorithmique, des méthodologie de développement, les bases de données, le data mining, les mathématiques, etc.
Les listes sont organisées par langue (plus de 20 langues) puis par langage ou domaine.
La liste anglaise est vraiment impressionnante :
https://github.com/vhf/free-programming-books/blob/master/free-programming-books.md
jeu. 10 juil. 2014 10:51:32 CEST -
-
link
- https://github.com/vhf/free-programming-books
programmation algorithmique réseau informatique
Les listes sont organisées par langue (plus de 20 langues) puis par langage ou domaine.
La liste anglaise est vraiment impressionnante :
https://github.com/vhf/free-programming-books/blob/master/free-programming-books.md
jeu. 10 juil. 2014 10:51:32 CEST -
-
link
- https://github.com/vhf/free-programming-books
programmation algorithmique réseau informatique
C'est quoi la récursion terminale ?
Avant toute chose, nous devons parler de la pile d'exécution (ou "pile des appels", ou tout simplement "pile").
La pile d'exécution est un espace de stockage permettant d'enregistrer l'endroit où chaque fonction active (= les fonctions invoquées mais non terminées) doit retourner à la fin de son exécution. Elle enregistre donc des adresses, mais aussi le contexte des fonctions actives (les variables locales, les paramètres, etc.).
Le principe de la pile est le suivant: si une fonction A invoque une fonction B, alors on stocke A au sommet de la pile pour savoir où reprendre lorsque B sera terminée. Si B invoque une fonction C, B sera placé au sommet de la pile à son tour. A la fin de C, on récupère B au sommet de la pile, et à la fin de B on récupère A au sommet de la pile (d'où le terme de pile, car on y empile et on y dépile des éléments).
Alors, imaginons une factorielle naïve :
fact(n)
{
if(n == 1) // cas de base
return 1;
else
return n * fact(n - 1);
}
Décomposons notre fonction fact : pour calculer n * fact(n - 1), il est évidemment nécessaire de calculer fact(n - 1). Cela implique que fact(n) ne peut pas retourner de résultat sans d'abord obtenir le résultat de fact(n - 1). Avant d'exécuter fact(n - 1), on place donc fact(n) au sommet de la pile et on exécute fact(n - 1).
Sauf qu'évidemment, le problème se pose à nouveau : pour calculer fact(n - 1) on doit tout d'abord calculer fact(n - 2), et on place donc fact(n - 1) sur la pile. Et ainsi de suite jusqu'à ce que l'on atteigne fact(1) qui retourne immédiatement 1.
Le souci c'est que notre pile n'est pas infinie. Dans les langages classiques type C ou Java, elle est même ridiculement petite. Lorsqu'elle est pleine, le programme crashe car il n'est plus possible d'invoquer de nouvelle fonction : c'est le dépassement (ou débordement) de pile, stack overflow en anglais.
Une fonction récursive terminale, c'est tout simplement une fonction récursive particulière, où la récursion ne fait intervenir aucune autre opération que l'appel de la fonction. Ce qui, pour notre factorielle se traduit ainsi :
fact(n, total)
{
if(n == 0)
return total;
else
return fact(n - 1, total * (n - 1));
}
Ici, lorsque l'on arrive fact(n - 1, total * (n - 1)), il n'y a rien à sauvegarder. Il suffit donc simplement de remplacer fact(n, total) par fact(n - 1, total * (n - 1)) au sommet de la pile. L'espace nécessaire sur la pile pour exécuter fact(n, total) est donc constant, ce qui assure que la pile ne débordera pas, même pour un très grand nombre de récursion.
Hélas, cette optimisation n'est pas implicite et doit être effectuée à la compilation. Beaucoup de langages classiques ne le font pas (Java, C#, Python, C/C++ sauf avec l'option -foptimize-sibling-calls, etc.). Il s'agit donc principalement d'une propriété typique des langages fonctionnels car ceux ci font massivement appel à la récursion.
sam. 28 sept. 2013 11:19:25 CEST -
-
link
programmation récursion fonctionnel algorithmique
La pile d'exécution est un espace de stockage permettant d'enregistrer l'endroit où chaque fonction active (= les fonctions invoquées mais non terminées) doit retourner à la fin de son exécution. Elle enregistre donc des adresses, mais aussi le contexte des fonctions actives (les variables locales, les paramètres, etc.).
Le principe de la pile est le suivant: si une fonction A invoque une fonction B, alors on stocke A au sommet de la pile pour savoir où reprendre lorsque B sera terminée. Si B invoque une fonction C, B sera placé au sommet de la pile à son tour. A la fin de C, on récupère B au sommet de la pile, et à la fin de B on récupère A au sommet de la pile (d'où le terme de pile, car on y empile et on y dépile des éléments).
Alors, imaginons une factorielle naïve :
fact(n)
{
if(n == 1) // cas de base
return 1;
else
return n * fact(n - 1);
}
Décomposons notre fonction fact : pour calculer n * fact(n - 1), il est évidemment nécessaire de calculer fact(n - 1). Cela implique que fact(n) ne peut pas retourner de résultat sans d'abord obtenir le résultat de fact(n - 1). Avant d'exécuter fact(n - 1), on place donc fact(n) au sommet de la pile et on exécute fact(n - 1).
Sauf qu'évidemment, le problème se pose à nouveau : pour calculer fact(n - 1) on doit tout d'abord calculer fact(n - 2), et on place donc fact(n - 1) sur la pile. Et ainsi de suite jusqu'à ce que l'on atteigne fact(1) qui retourne immédiatement 1.
Le souci c'est que notre pile n'est pas infinie. Dans les langages classiques type C ou Java, elle est même ridiculement petite. Lorsqu'elle est pleine, le programme crashe car il n'est plus possible d'invoquer de nouvelle fonction : c'est le dépassement (ou débordement) de pile, stack overflow en anglais.
Une fonction récursive terminale, c'est tout simplement une fonction récursive particulière, où la récursion ne fait intervenir aucune autre opération que l'appel de la fonction. Ce qui, pour notre factorielle se traduit ainsi :
fact(n, total)
{
if(n == 0)
return total;
else
return fact(n - 1, total * (n - 1));
}
Ici, lorsque l'on arrive fact(n - 1, total * (n - 1)), il n'y a rien à sauvegarder. Il suffit donc simplement de remplacer fact(n, total) par fact(n - 1, total * (n - 1)) au sommet de la pile. L'espace nécessaire sur la pile pour exécuter fact(n, total) est donc constant, ce qui assure que la pile ne débordera pas, même pour un très grand nombre de récursion.
Hélas, cette optimisation n'est pas implicite et doit être effectuée à la compilation. Beaucoup de langages classiques ne le font pas (Java, C#, Python, C/C++ sauf avec l'option -foptimize-sibling-calls, etc.). Il s'agit donc principalement d'une propriété typique des langages fonctionnels car ceux ci font massivement appel à la récursion.
sam. 28 sept. 2013 11:19:25 CEST -
-
link
programmation récursion fonctionnel algorithmique
Programmer Competency Matrix
Une matrice des différentes compétences de programmeur et leur niveau de maîtrise. Le pire c'est que j'ai étudié la plupart de ces trucs à un moment donné, mais j'en ai oublié la moitié étant donné que de nombreux concepts sont abstraits par les librairies (en algorithmie notamment). La connaissance passée compte-t-elle vraiment ? >>
sam. 28 sept. 2013 11:15:43 CEST -
-
link
- http://sijinjoseph.com/programmer-competency-matrix/
programmation informatique
sam. 28 sept. 2013 11:15:43 CEST -
-
link
- http://sijinjoseph.com/programmer-competency-matrix/
programmation informatique
De la place des mathématiques dans la programmation
J'entends souvent les développeurs débutants dire que les mathématiques ne sont pas utiles pour programmer.
En un sens ce n'est pas totalement faux, les mathématiques ne sont pas strictement nécessaires pour écrire des programmes. Toutefois, c'est uniquement car les programmes que nous écrivons font appel à des librairies qui résolvent la plupart des problèmes véritablement complexes que nous pourrions rencontrer. Ces librairies sont des boîtes noires qui nous masquent les détails mathématiques et algorithmiques sous-jacent, mais hélas ce n'est pas parce que nous ne manipulons pas ces détails qu'ils n'existent pas ;)
En fait, on retrouve des fondements mathématiques dans quasiment tous les domaines de l'informatique.
Retrouver des données "intéressantes" dans de grands ensembles (data mining, moteur de recherche) ? Des statistiques, des filtres, etc.
Les bases de données ? Théorie des ensembles, fonctions de hachage, etc.
L'encodage audio/vidéo ? Analyse numérique, mathématiques du signal, DFT, échantillonnage, statistiques, ...
La 3D ? Alors là c'est le pire je pense ; géométrie dans l'espace, physique, calcul vectoriel, calcul matriciel, calcul intégral, espaces, analyse numérique, algèbre, ...
Le chiffrement ? La compression ? La détection des erreurs ? Arithmétique modulaire, théorie des ensembles, théorie de l'information, ...
OCR ? Reconnaissance vocale ? Statistiques, réseaux bayésiens, réseaux de neurones, ...
Les réseaux ? Théorie de l'information, théorie des graphes, statistiques, ...
Ce n'est pas parce que nous ne manipulons pas toutes ces choses au quotidien qu'elles n'existent pas. Les ignorer revient à s'en remettre à des boîtes noires prétendument magiques, et à mal les utiliser.
jeu. 05 sept. 2013 17:13:35 CEST -
-
link
science programmation mathématiques
En un sens ce n'est pas totalement faux, les mathématiques ne sont pas strictement nécessaires pour écrire des programmes. Toutefois, c'est uniquement car les programmes que nous écrivons font appel à des librairies qui résolvent la plupart des problèmes véritablement complexes que nous pourrions rencontrer. Ces librairies sont des boîtes noires qui nous masquent les détails mathématiques et algorithmiques sous-jacent, mais hélas ce n'est pas parce que nous ne manipulons pas ces détails qu'ils n'existent pas ;)
En fait, on retrouve des fondements mathématiques dans quasiment tous les domaines de l'informatique.
Retrouver des données "intéressantes" dans de grands ensembles (data mining, moteur de recherche) ? Des statistiques, des filtres, etc.
Les bases de données ? Théorie des ensembles, fonctions de hachage, etc.
L'encodage audio/vidéo ? Analyse numérique, mathématiques du signal, DFT, échantillonnage, statistiques, ...
La 3D ? Alors là c'est le pire je pense ; géométrie dans l'espace, physique, calcul vectoriel, calcul matriciel, calcul intégral, espaces, analyse numérique, algèbre, ...
Le chiffrement ? La compression ? La détection des erreurs ? Arithmétique modulaire, théorie des ensembles, théorie de l'information, ...
OCR ? Reconnaissance vocale ? Statistiques, réseaux bayésiens, réseaux de neurones, ...
Les réseaux ? Théorie de l'information, théorie des graphes, statistiques, ...
Ce n'est pas parce que nous ne manipulons pas toutes ces choses au quotidien qu'elles n'existent pas. Les ignorer revient à s'en remettre à des boîtes noires prétendument magiques, et à mal les utiliser.
jeu. 05 sept. 2013 17:13:35 CEST -
-
link
science programmation mathématiques
Functors, Applicatives, And Monads In Pictures
 La programmation fonctionnelle emprunte un vocabulaire parfois obscur aux mathématiques, d'où cet intéressant petit article illustré qui revient sur les concepts de "fonctor" (foncteur), "monad" (monoïde) et "applicative" (foncteur applicatif).
La programmation fonctionnelle emprunte un vocabulaire parfois obscur aux mathématiques, d'où cet intéressant petit article illustré qui revient sur les concepts de "fonctor" (foncteur), "monad" (monoïde) et "applicative" (foncteur applicatif).
Une autre explication, en français :
http://lyah.haskell.fr/foncteurs-foncteurs-applicatifs-et-monoides
mer. 17 avril 2013 18:02:47 CEST -
-
link
- http://adit.io/posts/2013-04-17-functors,_applicatives,_and_monads_in_pictures.html
programmation fonctionnel mathématiques
Une autre explication, en français :
http://lyah.haskell.fr/foncteurs-foncteurs-applicatifs-et-monoides
mer. 17 avril 2013 18:02:47 CEST -
-
link
- http://adit.io/posts/2013-04-17-functors,_applicatives,_and_monads_in_pictures.html
programmation fonctionnel mathématiques
Intelligence Artificielle II - Notes de Cours
Des cours divers et variés sur plusieurs concepts issus de la recherche en intelligence artificielle (RIP :p) : réseaux bayésiens, réseaux neuronaux, arbres de décision, programmation logique, programmation par contraintes, algorithmes génétiques, etc.).
mar. 19 mars 2013 17:58:37 CET -
-
link
- http://www.damas.ift.ulaval.ca/~coursIA2/NotesDeCours.html
machine-learning programmation
mar. 19 mars 2013 17:58:37 CET -
-
link
- http://www.damas.ift.ulaval.ca/~coursIA2/NotesDeCours.html
machine-learning programmation
Literals in Programming Languages
Contrairement à ce que beaucoup de développeurs imaginent, la représentation de valeurs (literals) et de constantes varie beaucoup d'un langage à un autre. Cette page recense les syntaxes spécifiques à plusieurs langages.
dim. 27 mai 2012 18:59:41 CEST -
-
link
- http://www.gavilan.edu/csis/languages/literals.html
literal programmation
dim. 27 mai 2012 18:59:41 CEST -
-
link
- http://www.gavilan.edu/csis/languages/literals.html
literal programmation
Ce journal est basé sur Ginger, un gestionnaire de lien minimaliste développé dans le cadre d'un stage de perfectionnement. Pour plus d'informations, consulter le wiki consacré à mes projets personnels.